|
|
|
SuperX-Adminstrationshandbuch Kernmodul
|
|
|
|
Version |
4. 9 |
|
Stand |
21.12 .20 21 |
Sun, Sun Microsystems, Solaris, Java, JavaServer Web Development Kit, JDBC und JavaServer Pages sind eingetragene Warenzeichen von Oracle , Inc. Windows, WindowsNT, Win32, VBScript und Office 2000 sind eingetragene Warenzeichen von Microsoft Corp. Linux ist eingetragenes Warenzeichen von Linus Torvalds. Informix Dynamic Server, Informix Client SDK und Intersolv JDBC Driver sind eingetragene Warenzeichen der IBM Corp. HIS (HISinOne, SOS, POS, SVA, MBS, IVS, BAU, LSF und COB ) sind Produkte der HIS e.G . Alle weiteren Produktnamen sind Warenzeichen der jeweiligen Hersteller.
Dieses Produkt beinhaltet Software, die von der Apache Software Foundation ( http://www.apache.org/ ) entwickelt wurde.
SuperX wird unter der deutschen Variante der GPL-Lizenz von dem Land Nordrhein-Westfalen, vertreten durch die FernUniversität Hagen, diese wiederum vertreten durch die Geschäftsstelle der Initiative CampusSource bei der FernUniversität Hagen, Feithstraße 142, D-58084 Hagen vertrieben ( www.campussource.de ). Details zu den Lizenzbedingungen finden Sie im Kernmodul-Archiv (/lizenz.txt) oder unter http://www.campussource.de/lizenz/ . Ergänzende Hinweise finden Sie auf der Projekthomepage unter http://www.superx-projekt.de .
|
Einführung |
|
Sicherheitsaspekte |
|
Erforderliche Hardware |
|
1.2.1 Datenbankserver |
|
1.2.2 Applikationsserver |
|
Erforderliche Software |
|
Das Kernmodul |
|
Ausbaustufen einer SuperX-Implementierung |
|
Installation |
|
Neuinstallation |
|
2.1.1 Übersicht über Installationsschritte |
|
2.1.2 Besonderheiten für verschiedene Betriebssysteme |
|
2.1.2.1 Ubuntu / Debian |
|
2.1.2.2 RedHat / CentOS |
|
2.1.2.3 Noch nicht getestete Betriebssysteme |
|
2.1.3 Kurzanleitung: Das Vorgehen -kurz und knapp für Linux-Systeme |
|
2.1.4 Installation und Pflege der SuperX-Datenbank |
|
2.1.4.1 Einrichten des Datenbankservers unter UNIX / LINUX |
|
2.1.4.1.1 Stopp: welche Zeichencodierung soll es werden? |
|
Konfiguration der Zeichencodierung unter Suse Linux |
|
Konfiguration der Zeichencodierung unter Ubuntu Linux |
|
Zeichencodierung ändern |
|
2.1.4.1.2 User superx - Kernmodul entpacken |
|
2.1.4.1.3 Informix |
|
Systemvoraussetzungen |
|
Konfiguration |
|
Informix unter Ubuntu |
|
2.1.4.1.4 Installation von PostgreSQL |
|
Neuinstallation (am Beispiel derVersion 7.3.4) |
|
Postgres-Zusätze installieren: pgcrypto |
|
Postgres mit SSL Support |
|
Installation von Postgres unter Windows |
|
Native Windows-Version (nur PowerGres, Postgres 8.0 oder höher) |
|
Postgres unter Cygwin |
|
Cygwin für SuperX |
|
Postgres unter Ubuntu/Debian (Paketverwaltung) |
|
Postgres unter Ubuntu/Debian (Selbst kompiliert) |
|
Test der Installation von Postgres unter Ubuntu/Debian |
|
Postgres unter Redhat |
|
Postgres unter Suse Linux |
|
Postgres-Performance-Tipps |
|
Postgres-Nutzerkennungen mit Leserecht |
|
2.1.4.1.5 Datenbankverbindung über einen eingeschränkten User für mehr Sicherheit |
|
Entfernen und Vergeben von Datenbankrechten unter Informix |
|
Entfernen und Vergeben von Datenbankrechten unter Postgres |
|
2.1.4.1.6 Automatischer Start des Datenbankservers als Dienst |
|
Einrichtung der Dienste |
|
Aktivierung der Dienste |
|
2.1.4.2 Einspielen des Kernmoduls der SuperX-Datenbank |
|
2.1.4.3 Update und Sichern der Datenbank |
|
2.1.4.3.1 Ein Dump unter Informix |
|
2.1.4.3.2 Ein Dump unter Postgres |
|
2.1.4.4 Anpassung der DB-Parameter für Clientanwendungen |
|
2.1.4.4.1 Unter WIN32 auf den Informix-Server zugreifen: iLogin |
|
SuperX (Informix) unter Win32 als ODBC-Datenquelle einrichten |
|
2.1.4.4.2 Einrichtung des ODBC-Treibers für den Postgres-Server |
|
2.1.4.4.3 Anbindung des Access-Frontends an die ODBC-Quelle |
|
2.1.4.4.4 Anpassen der Datenbankparameter für das SuperX-Servlet |
|
Anpassung der Datenbankparameter für das SuperX-Servlet speziell für Informix |
|
2.1.4.4.5 Datenbankverbindung und Steuerung von DBForms |
|
2.1.4.4.6 Ein SSH-Tunnel für die Datenbank |
|
2.1.5 Installation und Pflege des Webservers |
|
2.1.5.1 Installation von Java und Datenbanktreibern |
|
2.1.5.2 Einrichtung der Servlet-Engine |
|
2.1.5.2.1 Steuerung des Servers: Die server.xml |
|
2.1.5.2.2 Datenbankverbindung für DBFORMS: die context.xml |
|
2.1.5.2.3 Die Datei conf/web.xml |
|
2.1.5.2.4 Administrator und Manager |
|
2.1.5.2.5 Einrichten der SuperX-Servlets unter Tomcat |
|
Allgemeines zur web.xml |
|
SuperXManager Servlet |
|
ResponseCompression |
|
field1Cache |
|
Session-Timeout |
|
CSV-Encoding beim Export |
|
Fehlerseiten |
|
2.1.5.2.6 Start des Tomcat |
|
2.1.5.2.7 Die Übertragung der Web Application |
|
2.1.5.2.8 SuperX Webanwendung in 2 Instanzen Ubuntu |
|
2.1.5.2.9 Der Webanwendung Manager |
|
Server-Cache |
|
Logging von Maskenaufrufen |
|
2.1.5.2.10 Verbesserung der Performance |
|
2.1.5.2.11 Einrichtung einer SSL-Verbindung in Tomcat |
|
Signierung eines Zertifikats in Tomcat |
|
2.1.5.2.12 Zusätzliche Verschlüsselung im Applet durch Public-Private-Key-Kontrolle |
|
2.1.5.2.13 Tomcat als Dienst unter Linux |
|
2.1.5.2.14 Tomcat als Dienst unter Windows einrichten (nur WINNT/2000 und Tomcat 3.x) |
|
2.1.5.2.15 Steuerung für das Applet: Die superx.properties |
|
2.1.5.2.16 Steuerung des XML-Frontends: PageComponents |
|
2.1.5.2.17 Einrichtung des Webservers bei mehreren Mandanten. |
|
2.1.5.2.18 Einrichtung von DBFORMS bei mehreren Mandanten |
|
2.1.5.2.19 Einrichtung Saiku bei mehreren Mandanten |
|
2.1.5.3 LDAP Anbindung |
|
2.1.5.3.1 ggfs. Zertifikat einspielen |
|
2.1.5.3.2 Anpassen der superx_ldap.properties |
|
2.1.5.4 Integration von Tomcat mit dem Apache |
|
2.1.5.4.1 Einrichten von SSL beim Apache 1.3.x unter Linux |
|
2.1.5.4.2 Einrichten von SSL beim Apache 2.x unter SuSE Linux |
|
2.1.5.4.3 Einrichten von SSL beim Apache 2.x unter Ubuntu Linux |
|
2.1.5.4.4 Zertifikate mit Let's encrypt |
|
2.1.5.5 Mailversand |
|
2.1.6 Anpassungen auf den Client-Rechnern |
|
2.1.6.1 Einstellungen für den Ajax-Client |
|
2.1.6.2 Installation der Java-Runtime |
|
2.1.6.2.1 Zertifikatswarnung im Applet |
|
2.1.6.2.2 Manuelle Anpassungen der Policy |
|
2.1.6.2.3 Installation des Applets unter UNIX / Linux |
|
2.1.6.3 Bei Problemen mit dem Start des Applets |
|
2.1.6.4 Leeren des Browser-Cache |
|
2.1.6.5 Leeren des Java - Cache |
|
2.1.7 Umgang mit SSL Verschlüsselung |
|
2.1.7.1 Erzeugen eines SSL Zertifikats |
|
2.1.7.2 Erzeugen eines Zertifikat-Request für eine Zertifizierungsstelle |
|
2.1.7.3 Importieren des Zertifikats in Java |
|
2.1.8 Test- und Produktivsystem synchronisieren |
|
2.1.8.1 Entladeparameter |
|
2.1.8.2 Ausführung |
|
Upgrade einer bestehenden SuperX-Installation |
|
2.2.1 Patch einspielen |
|
2.2.2 Upgraden des Kernmoduls |
|
2.2.2.1 Standardvorgehen beim Upgrade |
|
2.2.2.2 Upgrade Kernmodul Besonderheiten |
|
2.2.2.3 Vorbereitungen für Tomcataktualisierung |
|
2.2.2.4 Tomcat aktualisieren |
|
2.2.2.5 Datenbank aktualisieren |
|
2.2.2.6 Webserver aktualisieren |
|
2.2.2.7 Falls Joolap instaliert ist |
|
2.2.2.8 Upgrade von Mondrian / Saiku |
|
2.2.2.9 Upgrade bei mehreren Mandanten |
|
Datenschutz |
|
2.3.1 Checkliste Sicherheitsmaßnahmen SuperX |
|
2.3.1.1 Keine Verwendung von Standardkennungen |
|
2.3.1.2 Applet deaktivieren |
|
2.3.1.3 Public-Private-Key-Kontrolle von Applet-Befehlen |
|
2.3.1.4 Datenbankverbindung über einen eingeschränkten Datenbank-User |
|
2.3.1.5 Entfernen von temporären Dateien |
|
2.3.1.6 IP Adressen aus Logdateien löschen |
|
Das Clientpaket |
|
2.4.1 Installation |
|
2.4.1.1 Einrichten der Umgebung |
|
2.4.1.2 Einrichtung einer Datenbankverbindung |
|
2.4.2 Weitere Werkzeuge |
|
2.4.3 Download von Berichtsausgaben |
|
2.4.4 Mailversand von Berichtsausgaben |
|
Administration des Kernmoduls: HowTo |
|
Die SuperX-Administrationswerkzeuge |
|
3.1.1 Übersicht über Scripte unter UNIX |
|
3.1.1.1 Allgemeine Prozessverwaltung |
|
3.1.1.2 SuperX-spezifische Scripte: Übersicht |
|
3.1.1.3 Die Umgebungssteuerung: SQL_ENV |
|
3.1.1.4 Nutzung der SQL_ENV unter HISinOne-BI |
|
3.1.1.5 Allgemeine Scripte |
|
3.1.1.6 Codierung in ISO und UTF-8 |
|
3.1.1.7 Umgang mit Tabellen |
|
3.1.1.8 Modulverwaltung |
|
3.1.1.8.1 module_scripts_create.x |
|
3.1.1.8.2 module_install.x |
|
3.1.1.8.3 module_drop.x |
|
3.1.1.8.4 Entladen |
|
3.1.1.8.5 module_update.x |
|
3.1.1.8.6 module_etl.x |
|
Hochschulspezifische Transformationen im ETL-Prozeß |
|
3.1.1.8.7 Logging der Shellscripte |
|
Installation / Upgrade |
|
Laderoutinen |
|
Debugging von Freemarker Scripten |
|
3.1.1.9 Masken-Verwaltung |
|
3.1.1.9.1 Eine Maske suchen |
|
3.1.1.9.2 Eine Maske sichern und entladen |
|
3.1.1.9.3 Eine Maske neu einfügen |
|
3.1.1.9.4 Eine Maske löschen |
|
3.1.1.10 Änderungen an einer Maske vornehmen |
|
3.1.1.11 Ausführen von JasperReports |
|
3.1.1.12 XSL-Transformation |
|
3.1.2 Administration mit Abfragen im XML-Frontend |
|
3.1.2.1 Das Organigramm bearbeiten |
|
3.1.2.2 Den Themenbaum bearbeiten |
|
3.1.2.3 Userverwaltung |
|
3.1.2.3.1 Einzelne Benutzer löschen, neu anlegen und Stammdaten ändern |
|
Neuer Benutzer |
|
Benutzer löschen |
|
Benutzer bearbeiten |
|
Zum Häkchen Administrator/in |
|
3.1.2.3.2 Gastzugang |
|
3.1.2.3.3 Gruppen anlegen, löschen und Stammdaten verwaltung |
|
Neue Gruppe anlegen |
|
Gruppe bearbeiten |
|
Gruppe löschen |
|
3.1.2.3.4 Maskenrechte vergeben |
|
3.1.2.3.5 Sichten und Sichtarten zuordnen |
|
3.1.2.3.6 Benutzer Info |
|
Bericht: Benutzer – Abfragen |
|
Bericht: Benutzer – Institutionen |
|
Bericht: Benutzer - Sichten |
|
Bericht: Gruppen – Benutzer |
|
Bericht: Gruppen – Sachgebiete |
|
3.1.3 Rechte für DBFORMS |
|
3.1.4 Hochschulspezifische Filter anlegen |
|
3.1.5 Das Access-Frontend |
|
3.1.6 Weitere Tools |
|
3.1.6.1 SQLWorkbench |
|
Einen User betreuen |
|
3.2.1 Neuen User einrichten |
|
3.2.2 Passwort vergessen |
|
3.2.3 User-Rechte ändern |
|
3.2.4 User löschen |
|
Einstellungen zur Passwortsicherheit |
|
Eine Gruppe betreuen |
|
3.4.1 Neue Gruppe einrichten |
|
3.4.2 Gruppen-Rechte ändern |
|
3.4.3 Eine Gruppe löschen |
|
Verwaltung und Rechtevergabe von Sichten |
|
3.5.1 Bearbeitung von Sichten |
|
3.5.2 Berechtigung für Sichten |
|
3.5.2.1 User- und Gruppenrechte für Sichten |
|
3.5.2.2 Sachgebiete und Sichten |
|
3.5.2.3 Kostenstellenrechte innerhalb von Sichten |
|
3.5.2.3.1 Reguläre Sicht |
|
3.5.2.3.2 Rechte innerhalb von alternativen Hierarchien |
|
Startseite konfigurieren |
|
3.6.1 Startseite Menü |
|
3.6.2 Portlet Seite |
|
3.6.3 Impressum und Datenschutz |
|
3.6.4 Eigener CSS |
|
Verwendung von Mondrian / Saiku |
|
3.7.1 Anpassung der web.xml für Mondrian / Saiku |
|
3.7.2 Konfiguration der edustore.xml für Mondrian / Saiku |
|
3.7.3 Anpassung der context.xml für DBForms und Mondrian / Saiku |
|
3.7.4 Anpassung der dbforms-config.xml und edustore für Mondrian / Saiku |
|
3.7.5 Rechtevergabe in Saiku |
|
3.7.6 Logging in Mondrian / Saiku |
|
3.7.7 Troubleshooting Saiku |
|
3.7.7.1 SuperX-Kernmodul 4.7 Saiku ist nicht aufrufbar (leere Seite oder keine Würfel zur Ansicht) |
|
3.7.7.2 HISinOne-BI 2017.06 und höher:SuperX Weboberfläche wird nicht mehr angezeigt |
|
3.7.7.2.1 Configuration.xml |
|
3.7.7.2.2 Saiku-beans.xml |
|
3.7.7.2.3 Drop jcr-Tables |
|
3.7.7.2.4 Saiku data Verzeichnis löschen |
|
3.7.7.2.5 Edustore.xml im falschen Mondrian Format |
|
3.7.7.3 Wenn Dimensionen leer sind |
|
3.7.7.4 Cube Tabelle leer |
|
3.7.7.5 Umlaute in Saiku kaputt |
|
(Abfrage-)Masken entwickeln |
|
3.8.1 Maskenverwaltung im SuperX-Applet oder XML-Frontend |
|
3.8.2 Maskenverwaltung mit MS Access (obsolet) |
|
3.8.3 Effizientes Debugging |
|
3.8.4 Dokumentation von Abfragen: Glossare |
|
3.8.4.1 Allgemeine Schlüsselwörter |
|
3.8.4.2 Der Spezialfall Maskenfelder |
|
3.8.4.3 Benutzerhandbücher verlinken |
|
3.8.5 Masken für das XML-Frontend vorbereiten |
|
3.8.5.1 Erzeugen eines Stylesheets |
|
3.8.5.2 Zuordnung einer Maske zu einem Stylesheet |
|
3.8.5.3 Anpassung an Lesegeräte |
|
3.8.5.4 Einschränkungen des XML-Frontends |
|
3.8.5.5 Erweiterungen des XML-Frontends |
|
3.8.5.5.1 Export von Abfragen nach PDF und XLS |
|
3.8.5.6 Felder für Benutzergruppen verstecken |
|
3.8.5.7 Änderung von Feld-Vorbelegungen |
|
3.8.6 Maskensicherung und Rücksicherung im Browser |
|
3.8.6.1 Maskensicherung im Browser |
|
3.8.6.2 Maske im Browser rücksichern |
|
3.8.7 Masken per Kommandozeile ausführen |
|
Individuelle Kopf/Fußzeilen |
|
3.9.1 Einfache Variante: nur Hochschulename,URL und Logo |
|
3.9.2 Excel |
|
3.9.3 ganz individuelle HTML-Kopf/Fußzeilen |
|
3.9.4 PDF |
|
Upload von Dateien per Browser |
|
3.10.1 Anpassung der web.xml |
|
3.10.2 Nutzen des Upload-Servlets |
|
3.10.3 Eigene XSL-Stylesheets mittels Upload-Funktion |
|
Embedding SuperX: Eigene Oberflächen für SuperX gestalten |
|
3.11.1 Allgemeines Vorgehen |
|
3.11.2 Beispiel für eine eingebettete Seite |
|
3.11.3 Aufruf spezieller Layouts einer Ergebnistabelle |
|
3.11.4 Komplexeres Beispiel für die Einbettung von SuperX |
|
3.11.4.1 Oberfläche der Einbettung von SuperX in vorhandene Websites |
|
3.11.4.2 Technik der Einbettung von SuperX in vorhandene Websites |
|
Installation von Modulen |
|
3.12.1 Architektur von SuperX-Modulen |
|
3.12.2 Modulscripte im Kernmodul |
|
3.12.3 Installation eines Moduls: Allgemeines Vorgehen |
|
3.12.3.1 Allgemeines |
|
3.12.3.2 Einrichtung der Entladescripte |
|
3.12.3.2.1 Entladen unter Windows |
|
3.12.3.2.2 Dateitransfer beim Push-Verfahren |
|
3.12.3.2.3 Entfernen der Passworteingabe unter Unix |
|
3.12.3.2.4 Entfernen der Passworteingabe unter Windows |
|
3.12.3.2.5 Einrichtung von SFTP (Server) |
|
3.12.3.2.6 Einrichtung von SFTP |
|
3.12.3.2.7 Einrichtung von SFTP unter Windows |
|
3.12.3.2.8 Java-Client zum Entladen von Quell-Datenbanken |
|
3.12.3.3 Update eines Moduls: Allgemeines Vorgehen |
|
3.12.3.3.1 Modulupdate in mandantenfähigen Installationen |
|
3.12.3.3.2 Format der Unload Dateien: CSV |
|
3.12.3.4 Upgrade eines Moduls: Allgemeines Vorgehen |
|
3.12.3.5 Hochschulspezifische Anpassung eines Moduls |
|
3.12.3.6 Entfernen eines Moduls |
|
Überwachung und Performance |
|
3.13.1 Überwachung und Performance der Webanwendung |
|
3.13.1.1 SQL-Logging von Mondrian / Saiku |
|
3.13.1.2 Java-Monitoring mit JConsole |
|
3.13.2 Konfiguration der Datenblatt-Berichte: max. Zeilenanzahl |
|
3.13.3 SQL Benchmark Script |
|
3.13.3.1 SQLBenchmark Script downloaden |
|
3.13.3.2 SQLBenchmark Script ausführen |
|
3.13.3.3 SQLBenchmark Script Vergleichswerte |
|
Downloads einrichten und verteilen |
|
3.14.1 Konfiguration |
|
3.14.2 Tabellenstruktur |
|
3.14.3 Berechtigung für Downloads |
|
3.14.4 Masken zur Erzeugung und Verteilung von Downloads |
|
3.14.4.1 Download suchen |
|
3.14.4.2 Download bearbeiten: Metadaten und Dateien |
|
3.14.4.3 User- und Gruppenrechte auf Downloads |
|
3.14.4.4 Stichworte für Downloads |
|
Migrationsprojekte |
|
3.15.1 Postgres: Wechsel auf der Zeichencodierung auf UTF-8 |
|
3.15.2 Migration von Postgres zu Informix |
|
3.15.3 Migration von SuperX zu HISinOne / Edustore |
|
3.15.3.1 Migration von Datenbank und Dateisystem |
|
3.15.3.2 Einrichtung der BI Konnektoren |
|
Tomcat aktualisieren |
|
Bestandteile des Kernmoduls: Die Referenz |
|
Die Userverwaltung |
|
4.1.1 Verwaltung einzelner User |
|
4.1.1.1 Tabelle userinfo |
|
4.1.1.2 Tabelle user_masken_bez |
|
4.1.1.3 Tabelle sachgebiete |
|
4.1.1.4 Tabelle sachgeb_maske_bez |
|
4.1.1.5 Tabelle user_sachgeb_bez |
|
4.1.1.6 Tabelle user_institution |
|
4.1.2 Gruppenverwaltung |
|
4.1.2.1 Tabelle groupinfo |
|
4.1.2.2 Tabelle user_group_bez |
|
4.1.2.3 Tabelle group_masken_bez |
|
4.1.2.4 Tabelle group_sachgeb_bez |
|
4.1.3 Zugriffsprotokollierung |
|
4.1.3.1 Die Tabelle protokoll |
|
4.1.3.2 Die Tabelle proto_funktion |
|
Das Organigramm |
|
4.2.1 Die Tabelle Organigramm |
|
4.2.2 Füllen des Organigramms |
|
4.2.3 Die Prozedur sp_user_orga |
|
4.2.4 Die Prozedur sp_user_orga_child |
|
Die SuperX-Auswertungen |
|
4.3.1 Die Tabelle Maskeninfo |
|
4.3.1.1 SQL-Scripte |
|
4.3.1.2 Aufbau der Ergebnistabelle |
|
4.3.1.3 Verbindung zur Tabelle felderinfo |
|
4.3.2 Tabelle Felderinfo |
|
4.3.2.1 Dialogsteuerung |
|
4.3.2.1.1 Angabe einer DB- Tabelle |
|
4.3.2.1.2 Angabe einer Stored Procedure |
|
4.3.2.1.3 Angabe eines SQL-Ausdrucks |
|
4.3.2.1.4 Hinweis für Dialogart 1 und 2 |
|
4.3.2.2 Vorgabewerte für die Felder |
|
4.3.2.2.1 Konstanten |
|
4.3.2.2.2 SQL-Ausdrücke |
|
4.3.3 Tabelle systeminfo |
|
4.3.4 Die Tabelle themenbaum |
|
4.3.5 Verkettung von Masken: Die Tabelle macro_masken_bez |
|
Einzelne Schlüsseltabellen |
|
4.4.1 Die Tabelle menu_element |
|
4.4.2 Die Schlüsseltabelle aggregierung |
|
4.4.3 Die Schlüsseltabellen cif und cifx |
|
4.4.4 Die Schlüsseltabelle trans_inst |
|
4.4.5 Weitere Schlüsseltabellen |
|
4.4.5.1 Tabelle hochschulinfo |
|
Hinweise für Entwickler/innen |
|
Kompilieren der Java-Quellen |
|
5.1.1 Kompilieren mit Bordmitteln des JDK |
|
5.1.2 Kompilieren mit dem Jakarta-Build-Tool ant |
|
5.1.3 Entwicklung mit Jedit |
|
Erzeugung der SuperX-Hilfe im Javahelp-Format |
|
Versionshistorie |
|
Anhang |
|
Wichtige Anpassungen für Kern 5.0 |
|
6.1.1 Web.xml - parameter superxStandlone=true |
|
6.1.2 LDAP-Konfiguration auf neue Technik ändern |
|
LDAP Konfiguration vor Kern 4.9.2 |
|
6.2.1.1.1 Beispiel-Konfiguration Heilbronn |
|
6.2.1.2 Shibboleth Anbindung |
Das Berichtssystem SuperX ist ein sog. Data Warehouse für Bildungseinrichtungen, d.h. beliebig viele Datenquellen werden unter einer einheitlichen Auswertungsschnittstelle zur Verfügung gestellt. Da jede Hochschule unterschiedliche Datenquellen besitzt und in SuperX übernehmen will, bereiten wir für jede Datenquelle ein Modul vor, z.B. ein COB-Modul oder ein SOS-Modul. Bei Bedarf können Anwender auch eigene Module für proprietäre Datenquellen erzeugen und SuperX so erweitern.
Die Module enthalten die wichtigsten Prozeduren, Tabellen und Abfragen für die jeweilige Datenquelle. Der Startpunkt ist das Kernmodul. Eine Kurzanleitung für die Installation ist vorbereitet .
|
Zur Geschichte von SuperX |
|
SuperX wurde in den 90er Jahren an der Universität Karlsruhe von der Projektgruppe Abakus unter der Leitung von Herbert W. Roebke entwickelt. SuperX stand damals für: S ystem zur U nterstützung von P lanung und E ntscheidung des R ektorats durch I nformation, C ontrolling und S imulation. In der damaligen Version, die im Folgenden als das "alte SuperX" bezeichnet wird, bestand das System aus einer SuperX-Datenbank (Informix) und einem Win32 / SGI / Mac-Client. Im Zuge der Verbreitung von WWW-basierten Frontends wurde im Jahr 2000 in Karlsruhe der Client nach Java portiert. Dieses SuperX-Applet wurde an der Universität Duisburg weiterentwickelt und aus Performance- und Sicherheitsgründen in eine Applet-Servlet-Anwendung (3-tier) geändert. Da SuperX sich vor allem dann als nutzbar erwiesen hat, wenn das Berichtssystem auf die Bedürfnisse der Anwender (in der Regel Hochschulen) zugeschnitten werden kann, ist die neue SuperX-Anwendung ein Open Source-Projekt, d.h. Anwender können die Datenbank und den Client für ihre Zwecke ändern. Lizenzrechtlich basiert SuperX auf der CampusSource-Lizenz , einer Variante der GPL ( http://www.campussource.de/lizenz ). Um die Installation und die Weiterentwicklung von SuperX überschaubar zu halten, hat die Projektgruppe SuperX in Duisburg Ende 2001 beschlossen, die Datenbank in Module zu zerlegen. Das vorliegende Kernmodul soll sicherstellen, dass das gesamte System selbst nach Änderung von anderen Modulen weiterhin lauffähig und übertragbar bleibt. Die vorliegende Dokumentation wird außerdem deutlich machen, dass die "neue" Architektur einige Änderungen an der SuperX-Datenbank erfordert. Bisherige Anwender der Karlsruher SuperX-Anwendung erhalten eine spezielle Anleitung für das Update . |
Falls es bei der Implementation des Kernmoduls zu Problemen kommt, können Sie sich unter www.superx-projekt.de informieren. Oder mailen Sie uns direkt: danielq@memtext.de bzw. mbisping@memtext.de .
Da SuperX für den Einsatz in großen Netzen konzipiert wurde, sind folgende Schutzmechanismen implementiert:
• Benutzer- und Paßwortkontrolle
• SHA-Verschlüsselung von Passwörtern
• Benutzerspezifische Einschränkung des Angebots an Abfragemasken
• Benutzerspezifische Einschränkung der einsehbaren Institutionen in Datenbankanfragen
• Getrennte Datenhaltung (operative Systeme - SuperX)
• Abschottung der Datenbank gegenüber fremden Zugriffen (z.B. mit ODBC) durch 3-Tier-Architektur. Auch Client-Anwendungen wie das Informix Client SDK werden nicht eingesetzt.
• Verschlüsselte Verbindung von Client und Servlet (https), Möglichkeit der Zwischenschaltung eines Apache-Webservers (ggf. in der DMZ).
• Bei Einsatz des Applets: Zusätzliche Verschlüsselung der in der Anwendung eingebaute Applet/Servlet-Kommunikation
Nur das SuperX-Servlet auf dem Webserver und die SuperX-Datenbankadministratoren auf der Serverseite haben einen direkten Zugriff auf die SuperX-Datenbank. Alle anderen Zugriffsmöglichkeiten für Benutzer können ausgeschlossen werden, d.h. kein Zugriff mit anderen SQL-Frontend-Programmen wie ISQL, DBACCESS (Unix) oder ODBC (Windows, Mac).
Im Minimalbetrieb ist das gesamte SuperX-System auf einem Desktop-PC installierbar, z.B. auf einem Linux PC; dies reicht für den Testbetrieb im Intranet mit wenigen Usern vollkommen aus.
Für den Einsatz im Echtbetrieb unterscheiden wir mindestens drei Komponenten:
|
|
- Ein Datenbankserver |
|
|
- Ein Java-basierter Web- und Applicationserver |
|
|
- Die SuperX-Clients |
Die Server lassen sich auch in gängigen Virtualisierungslösungen einrichten.
Für jede Komponente gibt es unterschiedliche Empfehlungen.
Wir empfehlen generell Intel-Architektur mit Linux als Betriebssystem, da dies relativ kostengünstig ist und immer weitere Verbreitung findet. SuperX benötigt Java 1. 8 (OpenJDK). und bash-2.x-Scripte auf dem DB-Server einsetzen, beides läuft sicher unter Linux.
|
DB-Server |
Wir empfehlen die Hochleistungsserver aus den aktuellen Produktpaletten von verschiedenen Herstellern, die Firmen Canonical bzw. Novell/SuSE zertifizieren auch Hardware für Linux. Für den produktiven Einsatz empfehlen wir einen Mittelklasse-Server mit dem Betriebssystem Linux. SuperX benötigt an einer größeren Hochschule (>10.000 Studierende, viele SuperX-Module) erfahrungsgemäß 2- 3 0 GB Platz für den DB-Server. Berücksichtigen Sie bitte auch Backup Storage Space.
Wenn DB- und Applikationsserver getrennt betrieben werden und der Applikationsserver unter Linux läuft, ist auch das Betriebssystem Windows für den DB-Server möglich.
Wirt empfehlen auch hier Intel-Architektur und Linux als Betriebssystem für Neuanschaffungen.
Der Applikationsserver benötigt wenig Plattenplatz, aber eine leistungsfähige CPU und viel RAM. Der SuperX-Applikationsserver läßt sich auch ideal mit bereits konfigurierten Webservern auf Apache- oder IIS-Basis (z.B. Homepages von Hochschulverwaltungen) verbinden.
Wenn das XML-Frontend und JasperReports verstärkt eingesetzt werden soll, empfiehlt sich eine etwas leistungsfähigere Architektur, ggf. sogar der Betrieb von zwei Webservern im software-basierten Lastausgleich ("load balancing" via Tomcat).
|
Web-Server |
|
Generell gilt natürlich die Devise: So viel CPU-Taktfrequenz und RAM wie Sie sich leisten können.
Die SuperX-Datenbank läuft auf Windows- und Linux-Rechnern. Der SuperX-Client läuft im Browser . Für den Applikationsserver empfehlen wir in jedem Falle einen UNIX bzw LINUX-Server, da alle serverseitigen Scripte als Shellscripte konfiguriert sind. Ubuntu- und SuSE Linux versteh en sich gut mit Informix, aber alle aktuellen Linux-Distributionen enthalten bereits Java, Tomcat und Postgres.
Beim Informix-Datenbankserver sollten Sie darauf achten, daß SuperX in einem eigenen Online-System läuft.
Die erforderliche Software für den Betrieb des Kernmoduls:
Noch ein Hinweis zur Zeichen-Codierung: Ab dem Kernmodul 4.0 ist neben der ISO-Codierung auch UTF-8 möglich. Achten Sie darauf, das jeweils passende SuperX-Paket herunterzuladen (im Dateinamen befindet sich entweder "iso" oder "utf8"). Weitere Hinweise siehe Kapitel zur Zeichencodierung .
Das SuperX-Kernmodul beinhaltet alle zum Betrieb von SuperX unbedingt notwendigen Tabellen, Prozeduren und Abfragen; die wichtigsten Tabellen werden unten näher beschrieben.
Die folgende Tabelle zeigt die Ordnerstruktur des Kernmoduls auf einen Blick:
|
Pfad |
Beschreibung |
|
|
db |
|
Die SuperX-Datenbankseite |
|
|
bin |
Shellscripte |
|
|
etc |
Beispiel-Initscripte für SuperX-DB-Dienste |
|
|
install |
Installationsscripte |
|
|
module |
Modulpfad |
|
doc |
|
Dokumentation |
|
webserver |
tomcat |
Tomcat-Beispielimplementation (Tomcat 3.2.2) |
|
|
apache |
Apache-mod_jk (binär für SuSE Linux 8-9+ source) |
|
|
etc |
Beispiel-Initscripte für SuperX-DB-Dienste |
Die folgenden Abbildungen zeigen die Ordnerstruktur von jeweils Datenbank-Seite und Webserver-Seite.
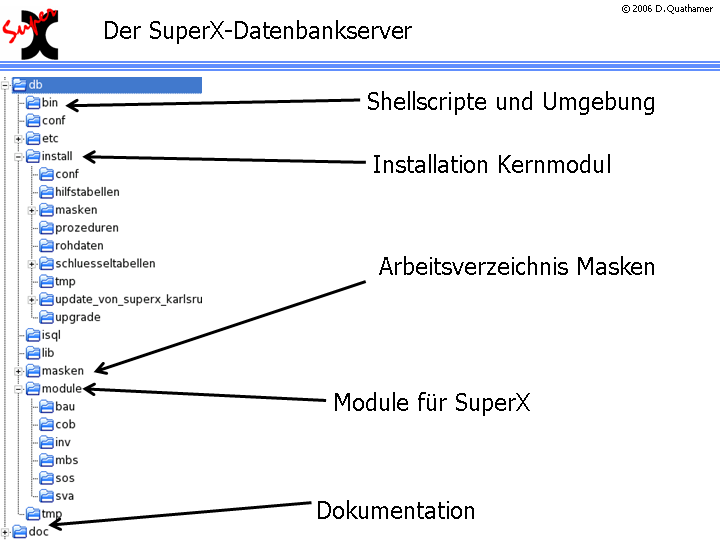
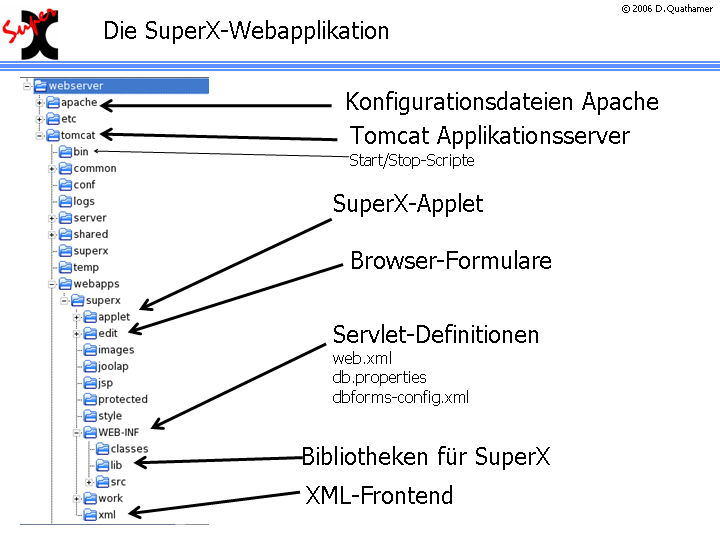
Der Datenbankserver kann auf einem anderen Rechner liegen als der Webserver; es ist aber auch möglich, das gesamte SuperX auf einem Rechner zu installieren. Je nach Hardware- oder Softwarevoraussetzungen kann dies ein WinNT/2000- oder Linux-Rechner sein. Unter Windows können Sie z.B. ein Verzeichnis C:\superx erstellen; unter Linux können Sie einen Nutzer superx mit dem Verzeichnis /home/su perx einrichten. Den von Ihnen gewählten Pfad bezeichnen wir als im Folgenden als $SUPERX_DIR , und alle Verzeichnisse des Kernmoduls ( db , doc , webserver ) werden dort hineinkopiert.
ln --symbolic <<Tatsächlicher Entladepfad>> rohdaten
SuperX liefert eine datenbankbasierten Website zur Präsentation von Inhalten der Hochschule für die öffentliche Nutzung im Internet sowie für die interne Nutzung im Intranet. Nach einer Datenübernahme aus den operativen Systemen gilt es, eine effiziente Berichterstellung zu ermöglichen und Export- und Importschnittstellen zu bieten. Das System wird in mehreren Aufbaustufen realisiert, wichtig ist daher die Skalierbarkeit des Systems vom Prototypen bis zum Echtbetrieb.
Der Prototyp der Erstinstallation ist auf einem einzelnen System möglich:
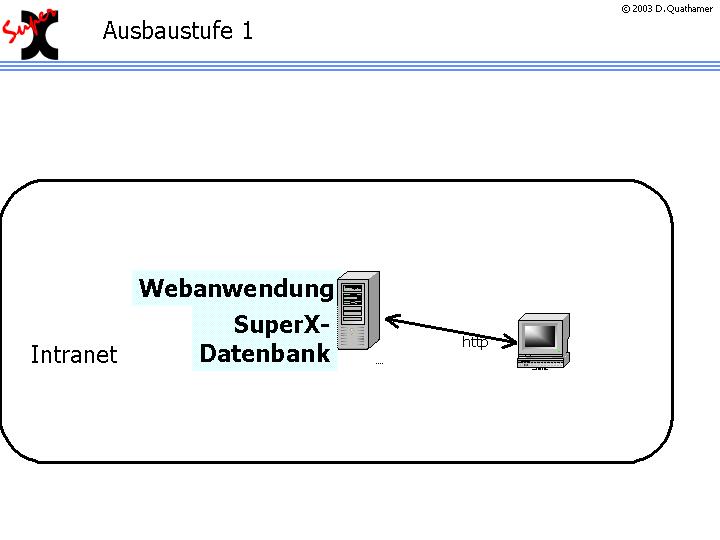
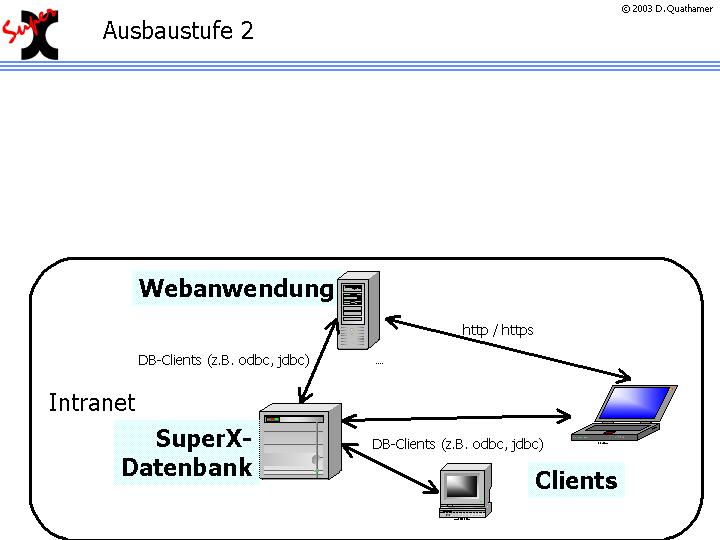
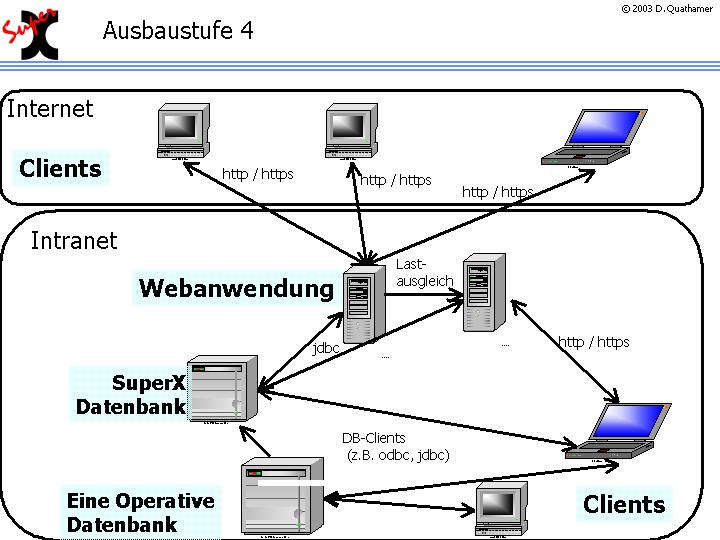
Das zu realisierende System besteht aus drei Komponenten: der Datenbank, der Webanwendung und des Clients (3-tier-Application). Die folgende Abbildung zeigt eine typi s che Beispielarchitektur:
|
Die Clients im Intranet greifen direkt oder über die Webanwendung auf die Datenbank zu. Die Clients im Internet greifen über den Browser (http oder für Verschlüsselte Zugänge https) auf die Inhalte zu. |
|
Durch diese Architektur wird verhindert, dass WWW-Clients direkten Zugriff zur Datenbank haben. Bei mittlerer Last ist diese Architektur ausreichend.
Falls die Last ansteigt, ist das System wie folgt skalierbar:
|
Die SuperX-Datenbank wird angebunden an ein oder mehrere operative Vorsysteme. Gleichzeitig, um die Webanwendung zu entlasten, ist es möglich, die Last auf einen zweiten Webserver auszulagern ("Load balancing"). |
|
Die Installationsschritte beziehen sich auf die Neuinstallation und das Upgrade. Für die Neuinstallation gibt es eine Kurzanleitung unter Linux.
Bei der Neuinstallation können Sie einfach alle Komponenten in einen Pfad $SUPERX_DIR kopieren und von dort die unten genannten Installationsschritte durchführen. Beim Update können Sie die Patchdatei in $SUPERX_DIR entpacken; die "alten" Dateien werden ersetzt. Wenn Sie die Datenbank und den WWW-Server auf getrennten Systemen betreiben, dann entpacken Sie am besten die Update-Datei in einem temporären Verzeichnis und kopieren dann die Ordner /db und /webserver auf die entsprechenden Rechner.
|
! |
Wichtig:Ändern Sie bitte keinesfalls die Ordnerstruktur unterhalb von /db und /webserver ; Sie können u.U. keine Updates ohne umfangreiche Anpassungen einspielen. Besonders bei der Inbetriebnahme des Systems ist es für die Fehlersuche unerläßlich, die Ordnerstruktur einzuhalten. |
SuperX ist zwar ein sehr offenes System, aber gewisse Konventionen werden sich in Zukunft als nützlich erweisen, wenn verschiedene Hochschulen Daten und Scripte austauschen wollen. In jedem Fall empfehlen wir Ihnen immer erst dann manuelle Anpassungen, wenn die Anwendung oder das Script funktioniert – eine äußerst sinnvolle Heuristik für die Arbeit mit derart komplexen Systemen wie SuperX.
Das Kernmodul wird in drei Arbeitsschritten installiert:
• Installation und Einrichtung der Datenbank
• Installation eines Webservers mit Servlet-Engine
• Installation der Java Runtime auf den Clients (nur bei Einsatz des Applets)
Die folgende Übersicht zeigt das Vorgehen bei der SuperX-Installation, darauf folgt eine Kurzanleitung für die Installationsmaßnahmen :
|
Schritt |
Erläuterung |
|
Kopieren und Vorbereiten des Kernmoduls nach $SUPERX_DIR |
Bringen Sie das SuperX-Kernmodul in ein Verzeichnis auf dem Rechner, am besten auf den Datenbankserver; ggf. können Sie die Verzeichnisse /doc und /webserver auf einen anderen Rechner verschieben.
Unter Windows können Sie z.B. ein Verzeichnis
C:\superx
erstellen und unter Linux einen Nutzer
superx
mit dem Verzeichnis
/home/superx
einrichten und alle Verzeichnisse des Kernmoduls (
db,doc,webserver
) dort hineinkopieren. Bei Betrieb unter Windows muss das gesamte db-Verzeichnis auf einen UNIX-Rechner verschoben werden. |
|
Installation der erforderlichen Software |
|
|
Start des Datenbankservers |
Starten Sie den Datenbankserver und spielen Sie danach die SuperX-Datenbank des Kernmoduls ein; die Zugangsparameter müssen Sie dem SuperX-Servlet bekannt geben. |
|
Start des SuperX-Servlets |
Gehen Sie in das Verzeichnis /webserver/tomcat/bin und starten Sie Tomcat, ggf. als Dienst |
|
Test des Webservers |
Öffnen Sie die Datei http://<<Rechnername>>:8080/superx/ im Browser und testen Sie zuerst die Anmeldung im XML-Frontend (und dann ggf. im Applet, wenn Sie dies nutzen wollen) |
|
Freigabe des Webservers im Netz |
Nun ist die Basisinstallation vom Kernmodul abgeschlossen, und Sie können mit der Anpassung für Ihre Einrichtung beginnen. Richten Sie User ein, und geben Sie die WWW-Adresse Ihres Webservers im Intra- oder Internet (in diesem Fall benötigen Sie auch die die Verschlüsselung) frei. |
|
Einspielen der Module |
Füllen Sie SuperX mit den einzelnen Modulen; bisherige SuperX-Andender können ihr bisheriges System übernehmen. |
Wir empfehlen den Einsatz von SuperX unter Linux. Für andere Betriebssysteme gelten hier und da Besonderheiten.
Wenn Sie Ubuntu nutzen, können Sie auch den Tomcat und Postgres von Ubuntu nutzen. Dabei ist aber auf einiges zu achten. Bitte schauen Sie dafür bitte unter den Kapiteln für Übertragung der Webapplikation auf einen vorhandenen Tomcat unter Ubuntu und Postgres unter Ubuntu/Debian nach.
Bisher konnten wir auch noch keine Probleme mit OpenJDK von Ubuntu feststellen.
Bitte prüfen Sie ob die Pakete unzip und recode installiert sind.
Bei RedHat bzw. CentOS muss man einige Pakete anders installieren. Bei Red Hat Enterprise Linux Server release 5.11 z.B. muss man das Paket recode von anderer Stelle installieren. Das Apache-Paket lautet "httpd".
Folgende Betriebssysteme wurden bisher noch nicht als Plattfomen für SuperX getestet:
• Solaris
• MacOS X
|
Voraussetzungen |
Postgres bzw. Informix IDS ist gestartet und läuft, der User existiert im Datenbanksystem hat das Recht, Datenbanken zu erzeugen, Java ist installiert.Auf dem Server sollte kein weiterer Server-Dienst auf den Ports 8005, 8009 und 8080 (Tomcat-Standard-Ports) laufen. |
|
Entpacken |
Entpacken Sie das Kernmodul in /home/superx
tar -xzvf |
|
Umgebungsvariablen |
Gehen Sie in das Verzeichnis db/bin cd db/bin Kopieren Sie SQL_ENV.sam nach SQL_ENV cp SQL_ENV.sam SQL_ENV
Wenn Sie die Datenbank superx unter Linux in
/home/superx
mit Postgres als DB-Server und Java im Verzeichnis
/usr/lib/java
installiert haben, brauchen Sie nichts ändern. Starten Sie das Script mit . SQL_ENV und fügen Sie den Aufruf am Ende der Datei ~/.bashrc ein: . ~/db/bin/SQL_ENV |
|
Einspielen der Datenbank |
Gehen Sie in das Install-Verzeichnis cd $SUPERX_DIR/db/install Starten Sie das Script kernmodul_erzeugen.x
Bei Fehlern kommt eine Meldung, Protokolle stehen in Damit ist die db-Seite eingerichtet. |
|
Steuerungsdatei für das Servlet: |
Nun gehen Sie in das Verzeichnis cd $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF Kopieren Sie db-postgres.properties bzw. db-informix.properties nach db.properties Beispiel für Postgres: cp db-postgres.properties db.properties Staten Sie den PropAdmin mit propadmin.x Passen Sie hier den Servernamen, Datenbanknamen, Usernamen und Passwort an, und drücken Sie "Verbindung testen" Danach speichern Sie die Datei. |
|
Connection Pool für dbforms |
Kopieren Sie die Datei Sie die Datei SUPERX_DIR/webserver/tomcat/webapps/superx/META-INF/context.xml.sam nach context.xml und editieren Sie die Datei. Passen Sie im Abschnitt <ResourceParams name="jdbc/superx"> die Verbindungsparameter an, die Sie oben auch dem SuperX-Servlet gegeben haben (also driverClassName und url ). Ab Kernmodul Version 4.6 wird die Datenbankverbindung des Servlets mit verwendet und die context.xml wird nicht mehr benötigt. |
|
Start von Tomcat |
Nun wechseln Sie in das Verzeichnis cd $SUPERX_DIR/webserver/tomcat/bin Und starten tomcat mit startup.sh (Stop übrigens mit " shutdown.sh ".) |
|
Und los geht’s... |
Nach erfolgreichem Start rufen Sie im Browser auf http://localhost:8080/superx/
Dort können Sie das Applet und das XML-Frontend aufrufen. Geben Sie bei der Kennung
superx
ein, und als Passwort
|
|
Feineinstellung |
Melden Sie sich im XML-Frontend an und gehen Sie im Menü auf "Tabelle suchen", klicken einfach "Abschicken" und öffnen Sie die Tabelle hochschulinfo ; dort sollten Sie Ihre Hochschule auswählen und "Speichern" anklicken, damit Ihre Hochschulnummer gespeichert wird. |
Die SuperX-Datenbank liegt als exportierte Datei in dieser Distribution vor und kann einfach importiert werden. Zunächst muss aber der Datenbankserver eingerichtet werden. Derzeit laufen die Installationsscripte und auch alle Modulscripte nur unter UNIX /Linux.
Der Datenbankserver läuft unter Informix (mind. Version 7.31) und PostgreSQL (mind. Version 8 . 3 ).
Bevor Sie das Kernmodul entpacken, sollten Sie sich vergewissern dass die Zeichencodierung des jew. Pakets mit der installierten übereinstimmt.
Die auf Ihrem System installierte Codierung erfahren Sie mit dem Befehl
echo $LANG
Mögliche Ausgaben sind de_DE@euro (oder die jew. Variante mit ISO) und de_DE.utf8 (je nach UNIX gibt es hier unterschiedliche Schreibweisen, z.B. auch de_DE.UTF-8 ). Wenn Sie sich nicht sicher sind, welche Codierung überhaupt installiert ist, können Sie mit
locale -a | grep de
eine Liste der deutschsprachigen Locales anzeigen.
SuperX unterstützte bis Version 3.5 nur die Locale de_DE@euro. Ab Version 4.0 ist auch UTF-8 möglich. Es ist auch ein Mischbetrieb möglich: Der Datenbankserver läuft mit ISO-Codierung, und der Tomcat mit UTF-8-Codierung. Achten Sie nur darauf, dass Sie immer das Paket mit der jeweils richtigen Codierung laden.
Mit dem SuperX-Kernmodul werden Scripte ausgeliefert, mit denen die Codierung von Dateien flexibel geändert werden kann.
Wenn die Fehlermeldung:"psql: FATAL: conversion between LATIN9 and LATIN1 is not supported" auftritt, unterscheidet sich die in der Shell eingetragene locale mit der in der Datenbank eingetragenen locale. Das Problem lässt sich Lösen mit setzen der Variable LANG auf "de_DE.8859-1". Wenn die Locale nicht verfügbar ist, muss man sie nachinstallieren (s.u.).
Da SuSE Linux "deutsche" Wurzeln hat, die die benötigten Locales d e_DE@euro und de_DE.utf8 in der Standardinstallation bereits installiert. Sie können die Zeichencodierung in der SQL_ENV eintragen und in der $HOME/.bashrc laden.
Hinweis für OpenSuse und Postgres: Die psql- und Java-Shell in OpenSuse 11.4 wertet nicht nur die Variable LANG aus, sondern auch "LC_ALL". Die Ursache dafür haben wir noch nicht gefunden. Im Zweifelsfall setzen Sie LC_ALL auf den gleichen Werte wie LANG.
Mit locale -a | grep de sehen Sie alle deutschen installierten Locales. Wenn die ISO-Codierung fehlt, müssen Sie sie wie folgt nachinstallieren:
apt-get install language-pack-de-base language-pack-de locales
Danach prüfen Sie in der Datei /usr/share/i18n/SUPPORTED , ob die Locales auswählbar sind:
vi /usr/share/i18n/SUPPORTED
Hier sind nun alle möglichen Sprachen sichtbar. Wir benötigen die locale de_DE@euro ISO-8859-15
Dann muss man sie verfügbar machen:
vi /var/lib/locales/supported.d/de
hat z.B. den Inhalt:
de_DE.UTF-8 UTF-8
de_CH.UTF-8 UTF-8
de_BE.UTF-8 UTF-8
de_LI.UTF-8 UTF-8
de_LU.UTF-8 UTF-8
de_AT.UTF-8 UTF-8
de_DE@euro ISO-8859-15
Danach gibt man ein:
dpkg-reconfigure locales
Wenn Sie dann noch einmal locale -a | grep de eingeben, sollte die Locale de_DE@euro sichtbar sein.
Tipp: wenn Sie unter Debian/Ubuntu eine root-Shell benötigen, müssen Sie eingeben: sudo -i
Die Datei .bashrc wird unter Ubuntu Linux nicht beim Öffnen einer Login Session durchlaufen, Sie können diese aber in der $HOME/.profile laden:
...
if [ -n "$BASH_VERSION" ]; then
# .bashrc laden, wenn vorhanden:
if [ -f "$HOME/.bashrc" ]; then
. "$HOME/.bashrc"
fi
fi
...
Für die tägliche Arbeit ist es nützlich, das Unix-Programm recode zu installieren, dies wird von den Konvertierungsscripten genutzt. Bei OpenSuse ist das standardmäßig installiert, bei Ubuntu muss man es nachinstallieren. Bei Red Hat Enterprise Linux Server 5.* muss man zunächst die Paketquelle angeben:
Datei /etc/yum.repos.d/rpmforge.repo anlegen mit dem Inhalt:
# Name: RPMforge RPM Repository for Red Hat Enterprise 5 - dag
# URL: http://rpmforge.net/
[rpmforge]
name = Red Hat Enterprise $releasever - RPMforge.net - dag
#baseurl = http://apt.sw.be/redhat/el5/en/$basearch/dag
mirrorlist = http://apt.sw.be/redhat/el5/en/mirrors-rpmforge
#mirrorlist = file:///etc/yum.repos.d/mirrors-rpmforge
enabled = 1
protect = 0
#gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-rpmforge-dag
gpgcheck = 1
Danach gibt man ein
yum --nogpgcheck install recode
Danach ist recode verfügbar.
Legen Sie einen User superx am einfachsten mit dem home-Verzeichnis /home/superx an.
Wenn wir im Folgenden $SUPERX_DIR sprechen, meinen wir /home/superx . Es ist natürlich auch jedes andere Verzeichnis möglich.
Es muss auf Betriebssystemebene sichergestellt werden, dass das Dateisystem Textdateien in der passenden Locale anlegt sind. Bei modernen UNIXen wird die Umgebungsvariable $LANG auf "UTF-8" gesetzt.
Setzen Sie die richtige Locale z.B. mit LANG=de_DE.utf8 ; export LANG.
Entpacken Sie die kernmodul-XX.tar.gz imVerzeichnis $SUPERX_DIR.
Machen Sie eine Kopie der Datei Date $SUPERX_DIR/db/bin/SQL_ENV.sam und nennen Sie sie einfach SQL_ENV . In dieser Datei werden viele allgemeine Konfigurationen der Umgebung vorgenommen. Prüfen Sie, ob die in der SQL_ENV angegebene Locale ( LANG=de_DE... ) existiert.
Geben Sie der Datei ggf. Ausführungsrechte mit chmod +x SQL_ENV .
SuperX unter Informix läuft derzeit unter UNIX und LINUX. Für den Datenbankserver unter Windows NT benötigen Sie in jedem Fall einen UNIX / LINUX-Rechner für die Shellscripte in den Modulen. Das Vorgehen ist im Abschnitt Konfiguration beschrieben..
Da die meisten Hochschulen bereits Informix-Datenbanken einsetzen, sind hier keine Hinweise zur Installation nötig. Da SuperX ein beliebtes System für Linux-basierte Systeme ist, hier nur ein paar kurze Hinweise für Informix 9.x unter Linux
Informix für Linux lässt sich ab Version 7.3 unter Linux installieren (wir haben SuSE Version 7.3-8.1 und RedHat 8/9 getestet). Gemäß Anleitung von IBM/Informix geht man so vor:
1. Als root anmelden
2. User und Gruppe informix anlegen (achten Sie darauf, dass die Default-Gruppe des Users "informix" nicht die Gruppe "users" ist, sondern "informix").
3.
Die Umgebungsvariable z.B. auf /home/informix setzen
export INFORMIXDIR=/home/informix
setzen
4. Dann die Informix- sql-CD einlegen und mounten, bzw. das IDS-Archiv in ein beliebiges Verzeichnis entpacken
5. ./ids_install starten (Serverpaket wählen, Seriennummer etc eingeben), und zum Abschluß auch das Script ./RUN_AS_ROOT.server
Die Ko n figuration des IDS geschieht im onmonitor über das Menü Mode->Parameters oder direkt in der Textdatei "onconfig", für unser Beispiel onconfig.superx . Die Pfade zu $INFORMIXDIR müssen ggf. angepaßt werden, die Voreinstellung ist oft "/usr/informix" . Wichtig ist außerdem der DBSpace (zu prüfen mit onstat -d ).
Zum Betrieb von SuperX hier nur einige Angaben zur empfohlenen Größe: Für das Kernmodul selbst würden 100 MB ausreichen, wenn Sie aber als erstes das SOS-Modul installieren möchten, sollten Sie nicht unter 400 MB starten (Parameter ROOTSIZE in onconfig.superx s.u.).
Wir empfehlen, das Logging auszuschalten, da SuperX keine Dialog-Anwendung ist und durch die Prozeduren sehr viel Logging anfallen würde. Selbst bei ausgeschaltetem Logging entstehen noch sehr viele Eintragungen, deshalb sollten Sie als Log Archive Tape Device LTAPEDEV /dev/null angeben.
Für die Rohdaten aus den operativen Systemen gibt es ein eigenes Verzeichnis, z.B. $SUPERX_DIR/db/module/<<modulname>>/rohdaten . Aus Platzgründen, und um sich den ftp-Transfer zu ersparen, bietet es sich unter UNIX an, hier NFS-Laufwerke einzurichten.
Falls Sie noch keine onconfig Datei für SuperX haben, erstellen Sie eine Kopie von /home/informix/etc/onconfig.std und nennen Sie sie onconfig.superx .
|
|
Wenn man den DB-Space in einem Cooked-File ablegen will, kann man z.B. als root eine leere Datei /var/informix/rootdbs erstellen (z.B. leere Datei mit vi). Beim DB-Space müssen Sie darauf achten, dass der Benutzer und die Gruppe informix Schreibrechte auf den Cooked File bzw. die Datenpartition haben. Dieser Pfad muss dann als Parameter für den DB-Space in der onconfig.superx angegeben werden. ROOTNAME rootdbs ROOTPATH /var/informix/rootdbs
|
In der onconfig-Datei für SuperX sind die Parameter DBSERVERNAME (wir empfehlen superx_host ) und DBSERVERALIAS (wir empfehlen superxdb ) wichtig.
Entsprechend dieser zwei Parameter ergänzen Sie die Datei sqlhosts.
|
|
|
|
$INFORMIX/etc/sqlhosts |
Die Datei mit den Hostnamen für Shared Memory-Zugriff (statt miles geben Sie den in /etc/hosts definierten Rechnernamen an) und für TCP-Zugriff. |
|
Beispiel: 
|
|
|
Machen Sie eine Ergänzung in /etc/services |
|
|
/etc/services |
Der SuperX-Service mit Portnummer |

|
|
|
|
|
Unter Informix für Windows NT befindet sich die onconfig unter %INFORMIXDIR%\etc\onconfig , die sqlhosts wird in der Registry unter HKEY_LOCAL_MACHINE oder besser über das Programm setnet32 geändert.
Wichtig ist die Eintragung eines DBSERVERALIAS, über den das Servlet die Verbindung aufbaut. Der Port des Service in /etc/services wird ebenfalls benötigt.
Diese Parameter werden in der Datei db.properties vom SuperX-Servlet benötigt.
Es muss sichergestellt werden, dass einige Umgebungsvariablen beim Start initialisiert werden. Je nach UNIX-Art geschieht das in der .profile oder. .bashrc im Home-Verzeichnis der Benutzer informix und superx. (Im Zweifelsfall ausprobieren)
Damit man die Umgebungsvariabeln nur an einer Stelle zu pflegen braucht, empfiehlt es sich, dem User Informix Leserechte auf die Datei $SUPERX_DIR /db/bin/SQL_ENV zu geben und diese in der .profile bzw. .bashrc der beiden User aufzurufen.
Eintrag: . $SUPERX_DIR/db/bin/SQL_ENV
|
Wichtig für den Einsatz unter Linux / |
#SX_CLIENT=pgsql; SX_CLIENT=dbaccess SUPERX_DIR=/home/superx; export SUPERX_DIR INFORMIXDIR=/home/informix; export INFORMIXDIR INFORMIXSERVER=superx_host; export INFORMIXSERVER ONCONFIG=onconfig.superx; export ONCONFIG echo echo "ONCONFIG: " $ONCONFIG echo "INFORMIXSERVER: " $INFORMIXSERVER CLIENT_LOCALE=de_de.8859-1; export CLIENT_LOCALE DB_LOCALE=de_de.8859-1; export DB_LOCALE SERVER_LOCALE=de_de.8859-1; export SERVER_LOCALE TERMCAP=$INFORMIXDIR/etc/termcap; export TERMCAP TERM=ansi; export TERM #Terminal für TeraTerm Pro auf Win32-Systemen:pctcp PATH=${PATH}:${SUPERX_DIR}/db/bin:$INFORMIXDIR/bin; export PATH DBDELIMITER=^ export DBDELIMITER DBDATE=DMY4.; export DBDATE DBMONEY=.; export DBMONEY TERMINAL=`tty`; export TERMINAL #Wenn auf DB-Server auch Webserver / Tomcat läuft #Beispiel für Suse Linux 7.3-Installation: export JAVA_HOME=/usr/lib/jdk1.6.29 |
Stellen Sie sicher, dass die Zeile #SX_CLIENT=pgsql; mit dem Gatterzaun auskommentiert ist und die Zeile SX_CLIENT=dbaccess nicht ;
In dieser Datei werden auch die Pfade und Parameter für das Laden der Daten aus den operativen System festgelegt. Sie wird von den Entladescripten und von den Cronjobs benutzt.
Für Informix ist es generell günstiger, unter Unix / Linux mit einem ANSI-Terminal zu arbeiten. Beachten Sie allerdings, daß bei dieser Einstellung kein xterm verfügbar ist und Sie somit keine graphischen Java –Anwendungen, z.B. den propadmin , auf dem Datenbankserver starten können.
Die Umgebungsvariablen DBTEMP und PSORT_DBTEMP sind eigentlich nicht mehr notwendig; wenn es Probleme beim Sortieren und Auslagern auf temporäre Datenträger gibt, dann sollte man diesen Pfad ebenfalls setzen. Die onconfig.superx liegt unter $INFORMIXDIR/etc und muss unbedingt als Parameter die Zeile
DBSPACETEMP dbtemp # Default temp dbspaces
enhalten, wobei der Name dbtemp im onmonitor frei gewählt werden kann.
Ist die Umgebung korrekt eingerichtet, dann startet man den IDS mit
|
Erstmaliger Start des IDS |
oninit -ivy |
Wenn bereits ein Informixserver vorhanden war muss in der onconfig der DBSPACE neu formatiert werden. Setzen Sie dazu die Variable
FULL_DISK_INIT=1
und wiederholen Sie den oninit -ivy .
Weitere nützliche Kommandozeilen-Befehle für Informix
|
oninit |
startet den Datenbankserver und bringt ihn in online-Modus |
|
onmode -yuk |
Beendet alle Transaktionen und stoppt den Server |
|
onstat |
Zeit die aktuellen Prozesse des DB-Servers an |
|
oninit -s |
Von Offline nach quiescent |
|
onmode -m |
Von quiescent nach online |
|
onmonitor |
Zeigt aktuellen Status sowie ein Menü zur Administration an |
|
tail -200 $INFORMIXDIR/online.log |
Zeigt das Ende der Logdatei an |
|
ipcs -m |
Anzeigen von Shared Memory für die Datenbank |
|
oncheck -pt <<Datenbank>>:<<Tabellenname>> |
Zeigt die Extents einer Tabelle an |
|
oncheck -ce |
Zeigt den genutzten Speicherbedarf der Extents für jeden dbspace an |
|
onspaces -c -d superxdbs -p /home/informix/storage/superxdbs -o 0 -s 4194304 |
Legt einen neuen dbspace "superxdbs" mit 4 GB Größe an, im Cooked File /home/informix/storage/superxdbs |
|
onstat -g ses |
Zei g t aktive Sessions an |
Dann kann man die Datenbank als User superx einspielen (s.u.).
Für den Ablauf der UNIX-Scripte zu den Masken (sx_select_mask, sx_insert_mask etc.) und für Cron-Jobs müssen die Parameter in der Datei $SUPERX_DIR/db/bin/SQL_ENV stimmen.
Hinweis für Datenbankserver unter AIX oder anderen Linux / Unix-Derivaten: Beachten Sie, daß die Scripte nur dann lauffähig sind, wenn auf dem Datenbankserver unter /bin/bash die bash Version 2.x oder höher liegt (bzw. gelinkt ist). Die Scripte von SuperX erwarten die bash-Shell im Verzeichnis /bin ; wenn dies nicht der Fall ist, sollte die Datei sh z.B. von /usr/bin nach /bin kopiert oder gelinkt werden. Unter Ubuntu Linux 6.10 beispielweise ist die Standardshell nach /bin/dash gelinkt, dies müssen Sie für SuperX ändern.
Die ersten Arbeitsschritte machen Sie in der root-Shell:
Unter Ubuntu legen Sie zunächst Gruppe und User informix an:
addgroup informix
adduser --ingroup informix informix
Beispiel Informix Innovator-C Edition als user root :
tar -xvf iif.12.10.FC8IE.linux-x86_64.tar
./ids_install
Es startet eine dialogbasierte Installation. In der typischen Installation wird auch ein DB-Server installiert und direkt gestartet. Der Db-Server hat in der Innovator-C Edition 130 MB Plattenplatz. Mit
ROOTSIZE 2097152
geben Sie dem Server in der onconfig die maximalen 2 GB Plattenplatz.
Er nutzt die Ports 9088 (DNS-Name) und 9090 (localhost).
Es wird im Installationsverzeichnis eine Umgebungsdatei ./ol_informix1210.ksh angelegt, die Sie mit
. ./ol_informix1210.ksh
laden können, und dann den Server starten/beenden können. Die angelegte onconfig lautet
onconfig.ol_informix1210
und liegt im Unterverzeichnis etc
Lehrfilm zur Installation von Postgres
SuperX ist seit Version 2.1 mit Postgres 7.2 bis 8.2 lauffähig, die neuen Module im Kernmodul 4.0 laufen auch unter Postgres 8.3 und 8.4. Die Distribution von Postgres für Unix findet sich unter www.post gresql.org . Eine Version für Windows befindet sich im Cygwin-Paket, dass Sie von unserem www.cyg win.com beziehen können.
Verschiedene Linux-Distributionen enthalten zwar bereits Postgres und müssen nicht "von Hand" installiert werden. Dies hat den Vorteil dass die Installation leicht ist und Sicherheitsupdates automatisch eingespielt werden können. Aber Vorsicht: die Distribution legt Postgres in anderen Verzeichnissen ab, als das Standardscritp von Postgres.
Im folgenden wird die Installation vom Quellcode beschrieben.
|
Voraussetzungen |
Postgres läuft unter verschiedenen UNIX-Varianten, z.B. Linux, HP-UX oder MacOS X. Wir empfehlen für den Einstieg Linux
2
. Vor der Installation unter Linux sollte die
Locale-Umgebungsvariable
$LANG
auf den gewünschten Wert geändert werden (
de_DE.utf8
oder
de_DE@euro
oder eine andere deutsche Locale (meist in
/usr/lib/locale
). Die aktuelle Locale wird bei der Installation von Postgres berücksichtigt und sorgt dafür, dass Datums- und Währungsformate korrekt sind.
Bei SuSE Linux 7.x bis 11.x ist es für ein Kompilieren der Postgres-Quellen erforderlich, dass die Pakete gcc, glibc, gettext, gettext-devel, readline, readline-devel, zlib und zlib-devel installiert sind. |
Erzeugen Sie zunächst den User postgres mit dem Homeverzeichnis der Postgres-Installation (z.B. unter Linux mit useradd -g users -d /usr/local/pgsql postgres ).
In der Download-Version von Postgres wird Postgres standardmäßig nach /usr/local/pgsql installiert. Als DBSpace muss man ein oder mehrere Verzeichnisse anlegen und mit initdb vorbereiten. Die SuperX-Datenbank läßt sich dann in einem eigenen DBSpace ablegen.
Zunächst müssen Sie sich als root anmelden. Wir gehen im folgenden davon aus, dass die Quellen von Postgres im Verzeichnis
/usr/src/packages/SOURCES
liegen (das Archiv z.B. von postgresql-7.3.4.tar.gz muss hier entpackt werden).
Dann gehen Sie in das Verzeichnis postgresql-7.3.4 , und führen folgende Befehle aus:
|
Postgres 7.3.-9x |
./configure --enable-nls make make install mkdir /usr/local/pgsql/data chown postgres /usr/local/pgsql/data |
Wenn Sie Postgres 7.2.x installieren, müssen beim ./configure der Parameter --enable-multibyte=LATIN1 gesetzt werden, in Postgres 7.3 oder höher ist dies defaultmäßig bereits eingebaut sind.
Wenn Sie SSL Support benötigen, müssen Sie noch den Parameter –with-openssl hinzufügen. Wenn Sie Postgres in einem anderen Verzeichnis als /usr/local/pgsql installieren wollen, müssen Sie den Parameter –prefix=<<Pfadname>> hinzufügen. Weitere Optionen fürs configure gibt die Zeile
./configure --help
Damit sind die Schritte, die als
root
auszuführen sind, beendet. Wir wechseln nun zur Kennung postgres mit
su - postgres
Vor der Initalisierung des DBSPACE sollte die Sprachumgebung des Users postgres korrekt sein. Für die bash wird in den meisten Distributionen die Umgebung generell in der Datei .bashrc bzw. .profile im Homeverzeichnis des Users postgres gesetzt; dort geben Sie den Pfad für das data -Verzeichnis an, und legen die Ausführprogramme von Postgres in den Datenpfad. Hier ein Beispiel für den Betrieb mit UTF-8:
|
.bashrc |
... #Zur Sicherheit für Postgres auch einzeln: export LC_CTYPE='de_DE.utf8' export LC_COLLATE='de_DE.utf8' export LC_TIME='de_DE.utf8' export LC_NUMERIC='de_DE.utf8' export LC_MONETARY='de_DE.utf8' export LC_MESSAGES='de_DE.utf8'
PATH=$PATH:/usr/local/pgsql/bin
export PGDATA=/usr/local/pgsql/data |
und hier ein Beispiel für ISO:
|
.bashrc |
... #Zur Sicherheit für Postgres auch einzeln: export LC_CTYPE='de_DE@euro' export LC_COLLATE='de_DE@euro' export LC_TIME='de_DE@euro' export LC_NUMERIC='de_DE@euro' export LC_MONETARY='de_DE@euro' export LC_MESSAGES='de_DE@euro'
PATH=$PATH:/usr/local/pgsql/bin
export PGDATA=/usr/local/pgsql/data |
Wenn die Sprachumgebung stimmt, dann wird der DBSPACE vom User postgres initialisiert.
|
Initialisierung des DBSPACE |
/usr/local/pgsql/bin/initdb -D $PGDATA
|
Durch initdb wird der DBSpace erzeugt. Wenn die Umgebung stimmt, dann wird Postgres für die deutsche Locale vorbereitet (Sortierung von Zeichen, Datums- und Währungsformate etc).
|
Ausgabe von |
/usr/local/pgsql/bin/initdb -D $PGDATA
|
|
Wenn Sie Postgres als Binärpaket aus der Distribution von SuSE 8.x - 10.x verwenden, müssen Sie beachten, dass der DBSPACE beim ersten Start des Postmaster automatisch in
/var/lib/pgsql/data
angelegt wird. Wenn dabei die Umgebungsvariablen nicht auf die deutsche Locale gesetzt sind, wird ein amerikanischer Zeichensatz benutzt (Default-Einstellung). Bevor Sie also das Init-Script z.B. im Runlevel-Editor des
YAST
starten, sollten Sie mit dem Sysconfig-Editor (im Yast:
System->Editor für Sysconfig-Dateien
) die Variable
POSTGRES_LANG
(im Yast: Suche nach "POSTGRES") auf die deutsche Locale (
de_DE.utf8
oder
de_DE@euro
setzen. Außerdem sollten Sie dann die Variable
POSTGRES_OPTIONS=-i
|
Dann müssen Sie die ip-Nummer des Rechners mit dem SuperX-Webserver (sowie von allen anderen Clients, die direkt auf die Datenbank zugreifen sollen) in die Datei /usr/local/pgsql/data/pg_hba.conf eintragen. In der Datei $PGDATA/pg_hba.conf stehen die Verbindungsberechtigungen für der Server; hier müssen Sie mindestens dem User superx die Verbindungsrechte geben, z.B. mit folgender Zeile:
|
Auszug aus pg_hba. |
host
all
all
127.0.0.1/32
trust |
Die obige Zeile gibt dem User superx Verbindungsrechte für alle Datenbanken auf dem lokalen Rechner 192.168.0.16 .
Die Netzmaske "/32" schränkt die Regel einen Rechner ein (entspricht 255.255.255.255). Wenn Sie "/24" wählen, öffnen Sie die Netzmaske auf 255.255.255.0, d.h. bei obigem Beispiel alle Rechner im Netz 192.168.0.x.
Bitte beachten Sie, dass die Standardvorgabe nach der Installation von Postgres die ist, dass alle User auf dem aktuellen Rechner mit dem Datenbankserver verbinden dürfen. Dies sollten Sie natürlich ändern.
Wenn Sie statt " trust " den Wert " md5 " eingeben, dann erfolgt eine Passwortabfrage. Dies ist für nächtliche Ladejobs nicht praktikabel. In diesem Falle müssen Sie das Passwort per Client übergeben, entweder mit einer Datei " ~/.pgpass " mit dem Inhalt:
<<Servername>>:<<Port>:<<Datenbank>>:<<Kennung>>:<<Passwort>>
z.B.
dbserver.hochschule.de:5432:superx:superx:anfang12
Alternativ kann man auch die Umgebungsvariable PGPASSWORD mit dem Passwort belegen, dies ist allerding "deprecated" und wird in zukünftigen Versionen von Postgres unterbunden.
Weitere Parameter werden in der Konfigurationsdatei postgresql.conf definiert; wichtig ist die Einstellung, dass Postgres einen TCP-IP-Socket öffnet (Parameter tcpip_socket=true bei Postgres 7.x, listen_addresses=<<IP-Nr.>> bei Postgres 8.0 oder höher) sowie der TCP-IP-Port (port = 5432 ist die Standardvorgabe). Die Anzahl der gleichzeitig offnenen Verbindungen muss kleiner sein als die Anzahl, die Sie für das SuperX-Servlet definieren. Weitere Details zur Einrichtung von Postgres-Runtime-Parametern finden Sie im Admin-Handbuch der Postgres-Distribution. Außerdem sollen Sie beim Betriebssystem SuSE 9.1 oder höher den IPV6-Eintrag für "localhost" (::1) in /etc/hosts auskommentieren.
Danach wird der Datenbankserver gestartet mit dem Befehl postmaster.
/usr/local/pgsql/bin/postmaster -i -D /usr/local/pgsql/data
Wir empfehlen, die Ausgabe von dem Prozeß in eine Logdatei zu schreiben, z.B. nach /var/log/postgresql.log . Legen Sie diese Datei als User root an, und machen Sie dann den User postgres zum Eigentümer. Ein Beispielscript ist folgendes (im Kernmodul zu finden unter $SUPERX_DIR/db/install ):
Um zu testen, ob die Locale richtig ist, gehen Sie als User postgres in die Shell:
|
Prüfen der Locale |
Öffnen Sie mit Bei richtiger Locale lautet die Ausgabe:
?column?
|
Im Verzeichnis $SUPERX_DIR/db/install befindet sich ein Shellscript check_sortierung_pg.x, das prüft, ob die aktuell in der Umgebung festgelegten Variablen zu korrekter Darstellung von Umlauten und Sortierung unter Postgres der gewünschte Ergebnis bringen. Das Script legt einen temporären DBSPACE an, führt darin einen Testselect aus und löscht den DBSPACE wieder, in der Logdatei check_sortierung.log steht dann das Ergebnis. In dem Script muss die Variable PG_HOME korrekt gesetzt sein, der Rest wird automatisch geprüft.
Dann erzeugen Sie den User
superx
für Postgres:
createuser superx
Wenn der User ein SuperUser sein soll, geben Sie ein:
createuser --superuser superx
ggfs. ALTER USER superx WITH PASSWORD 'new_password';
Bei Änderungen der pg_hba.conf müssen Sie übrigens Postgres nicht neu starten, Sie können die Datei im laufenden Betrieb auch mit pg_ctl -D $PGDATA reload neu laden.
SuperX benötigt die Prozedursprache plpgsql . Wenn Sie als SuperUser die Prozedursprache installieren wollen (in Postgres 7.x und 8.x notwendig, in Postgres 9.x nicht mehr), geben Sie in der Shell ein:
createlang plpgsql
Damit ist Postgres installiert und für die SuperX-Installation konfiguriert. Bei dieser Gelegenheit sollten Sie den Datenbankserver gleich als Dienst beim Systemstart einrichten.
Es kann unter Umständen folgende Fehlermeldung in dem Postgres Logfile auftauchen:
FATAL: could not create shared memory segment: Das Argument ist ungültig
DETAIL: Failed system call was shmget(key=5433001, size=39149568, 03600).
HINT: This error usually means that PostgreSQL's request for a shared memory segment exceeded your kernel's SHMMAX parameter. You can either reduce the request size or reconfigure the kernel with larger SHMMAX. To reduce the request size (currently 39149568 bytes), reduce PostgreSQL's shared_buffers parameter (currently 4096) and/or its max_connections parameter (currently 100).
If the request size is already small, it's possible that it is less than your kernel's SHMMIN parameter, in which case raising the request size or reconfiguring SHMMIN is called for.
The PostgreSQL documentation contains more information about shared memory configuration.
Lösung:
Als erstes die zu ändernde Datei im Originalzustand sichern.
cp /etc/sysctl.conf /etc/sysctl.conf-orig
Danach mit vi die Datei /etc/sysctl.conf bearbeiten und folgendes am Ende einfügen:
# For postgres
kernel.shmmax = 104857600
Danach dürfte der Start von Postgres kein Problem mehr sein.
Vergl. http://www.postgresql.org/docs/current/static/kernel-resources.html#SYSVIPC
Neben dem Kernsystem von Postgres bietet es sich an, die vielen Zusatzmodule von Postrges zu nutzen. Die Installation erfolgt aus den Quellen der Kerndistribution. Wir zeigen dies am Beispiel von pgcrypto , einem Paket zur Verschlüsselung, das wir für die Verschlüsselung von Passwörtern gebrauchen:
In Postgres9 ist crypto defaultmäßig bereits mitinstalliert.
Nach dem ./configure (s.o.) der gesamten Postgres-Quellen gehen Sie als root in das Verzeichnis contrib/pgcrypto
Geben Sie ein:
gmake all
gmake install
Es werden Bibliotheken in
/usr/local/pgsql/lib
erzeugt. Das SQL-Script zur Erzeugung der Crypo-Funktionen liegt in
/usr/local/pgsql/share/contrib/pgcrypto.sql
. Wenn Sie es in der SuperX-Datenbank installieren wollen, geben Sie dort ein:
psql superx < pgcrypto.sql
Wenn Sie es allen Datenbanken zur Verfügung stellen wollen, laden Sie die Funktionen nach template1:
psql template1 < pgcrypto.sql
Wenn die Postgres Binaries mit SSL Support erzeugt wurden, kann man den SSL Support leicht aktivieren:
• Erzeugen Sie ein öffentliches und ein privates Zertifikat
• in der Datei postgresql.conf den Schalter ssl = on setzen
• Das öffentliche Server Zertifikat nach $PGDATA/server.crt kopieren
• Das private Zertifikat nach $PGDATA/server.key kopieren.
Wenn Sie die Zertifikate wie Anleitung erzeugt haben lauten die Befehle z.B.:
cp /root/demoCA/cacert.pem /usr/local/pgsql/data/server.crt
cp /root/demoCA/private/cakey.pem /usr/local/pgsql/data/server.key
Achten Sie beim Kopieren darauf, dass die Dateirechte nur dem Eigentümer Leserecht geben.
Beim Serverstart wird ggf. ein PEM Passwort abgefragt.
Um den Zugriff zum Server per SSL zu steuern, können Sie in der Datei pg_hba.conf statt der Direktive "host" den Namen "hostssl" nutzen. Damit werden SSL Verbindungen erlaubt. Umgekehrt werden keine non-SSL Verbindungen erlaubt, wenn es keine "host" Direktive gibt.
In psql können Sie den Zugang testen, allerdings müssen Sie die Umgebungsvariable
PGSSLMODE=require
setzen und in der SQL_ENV speichern. Im Erfolgsfall bekommen Sie die Meldung:
psql (XXX)
SSL-Verbindung (Verschlüsselungsmethode: DHE-RSA-AES256-SHA, Bits: 256)
Geben Sie »help« für Hilfe ein.
superx=#
Damit die JDBC Klassen und die Shellscripte mit SSL verbinden, muss man das Zertifikat in der Java Runtime bekannt machen in der Datei webapps/superx/WEB-INF/ db.properties den Parameter:
ssl=true
hinzufügen.Mit DOQUERY "..." kann man den Zugriff testen.
Für die Installation von Postgres unter Windows existiert seit Postgres 8.0 eine Möglichkeit, Postgres nativ zu betreiben. Dies empfehlen wir. Aus historischen Gründen haben wir auch den Betrieb von Postgres unter Cygwin dokumentiert.
Für den Betrieb von SuperX wird aber auf jeden Fall die Shell-Umgebung von Cygwin benötigt. Dies wird in einem dritten Abschnitt erläutert.
Seit längerem gibt es eine kostenpflichtige Windows-Version von Postgres unter dem Namen PowerGres. Mit der Version 8.0 läuft auch das "normale" Postgres nativ (d.h. ohne die Unix-Emulation Cygwin) unter Windows, allerdings nur unter Win2000 und WinXP (nur XP Professional, nicht XP Home). Dies bietet erheblich mehr Komfort bei der Installation und Stabilität beim Betrieb. Für SuperX müssen Sie aber in jedem Fall cygwin installieren (s.u.), da die SuperX Scripte nur unter Unix / bash laufen.
Laden Sie die neueste Version von Postgres (Win) herunter.
•
Installieren Sie als Administrator das msi-Paket, z.B. im Verzeichnis
C:\Programme\PostgreSQL\8.0-beta1
. Achten Sie darauf, daß alle Pakete installiert werden, auch
pgadmin III
(ältere pgadmins, odbc- oder jdbc-Treiber funktionieren nicht).
• Der User, der postgres startet, muss ein normaler User sein(z.B. "postgres"), kein Administrator; er muss vorher unter Windows angelegt sein. Er ist auch der Eigentümer der Datenbank template1 (der Superuser).
• Postgres sollte als Dienst installiert werden
• Beim Anlegen des Datenbank-Cluster legen sie die deutsche Locale an, und als Zeichenformat LATIN1 (nicht unicode). Das Dateisystem muss NTFS sein.
• psql & co dürfen für den Betrieb von SuperX beim User nicht in den Windows-PATH gesetzt werden (z.B. C:\Programme\PostgreSQL\8.0-x\bin ), stattdessen nehmen wir die Cygwin-Applikationen (s.u.).
•
in
C:\Programme\PostgreSQL\8.0-x\data\postgresql.conf
muss man statt
früher tcpip_socket = true
den Parameter listen_adress ='IP-Adresse'
• In der Datei pg_hba.conf ist die Standardanmeldung anders als unter Unix auf md5 (nicht trust) gesetzt; wenn Sie nicht ständig das User-Passwort eingeben wollen, sollten Sie den entsprechenden Passus auf "trust" setzen.
Damit ist Postgres konfiguert, Sie können den Dienst jederzeit in der Computerverwaltung über das Applet "Dienste" neu starten. Normalerweise startet Postgres dann auch beim Systemstart automatisch.
Neben der nativen Postgres-Installation (die wir empfehlen) gibt es auch die Möglichkeit, Postgres unter Cygwin zu betrieben. Insgesamt eignet sich eine unter Cygwin kompilierte Postgres-Installation unter nur für den Testbetrieb, denn bei der Sortierung werden Umlaute falsch eingeordnet und es wird sehr großzügig mit der Prozessorlast umgegangen: Wenn Postgres-Prozesse laufen, dann ist die Performance des Rechners für andere Anwendungen weitgehend gesperrt.
Aber auch bei der nativen Postgres-Installation unter Windows benötigen Sie für Postgres und SuperX unter Windows die UNIX-Shell-Emulation cygwin . Cygwin bietet rudimentäre UNIX-Funktionen wie z.B. die "bash", aber keine UNIX-typischen Dateirechte (z.B. Ausführungsrechte für User, Gruppen oder Andere).Außerdem unterstützt Cygwin (unseres Wissens) keine Locales, und unter Win98 haben wir keine stabile Installation hinbekommen. In den Mailinglisten wurden häufiger Probleme mit Win98 berichtet, unter WinME, Win2000 und Windows XP haben wir Cygwin erfolgreich getestet.
Das folgende Beispiel arbeitet mit Postgres 7.4.x. Postgres ist als Paket im Installer von Cygwin auswählbar.
Für die Installation muss man eine Windows-Kennung benutzen, die Rechte für "Standardbenutzer" reichen aus (es sei denn Cygwin soll als Dienst laufen). Außerdem: Wenn Sie planen, Daten bzw. entladene Datenbank-Exporte zwischen verschiedenen Rechnern hin- und herzuschieben, sollten Sie darauf achten, dass Sie immer die gleiche Kennung benutzen. Sie können z.b. superx nehmen. Die Windows Kennung, unter der man Cygwin installiert, wird nämlich nach Cygwin durchgereicht.
Vorgehen:
1)
Die setup-Datei
setup.exe
der Unix-Emulation Cygwin von
http://www.cygwin.com
herunterladen und starten
Dann je nach Belieben
direkt aus dem Internet installieren oder zunächst herunterladen und dann
install from local directory
(alle Komponenten ausgewählt lassen) anklicken (wir empfehlen letzteres Vorgehen, da das Online-Cygwin-Paket ständig aktualisiert wird).
2) Als Installationspfad sollten Sie unbedingt einen Pfad wählen, der keine Leerzeichen enthält, z.B. c:\cygwin ).
3) Bei der Frage, für welchen User Cygwin installiert werden soll, wählen Sie "All users", und beim Standard-Dateiformat wählen Sie Unix.
4)
Bei der Auswahl der Pakete sollten Sie wie folgt vorgehen: Bei den
Shells
mauss auf jeden Fall die
bash
ausgewählt sein. Zusätzlich zu den Defaults müssen lediglich
Base ->
TextUtils,
Database -> Postgres, Admin -> cron, net->openssh
und
Libs -> libint
und
libint1
manuell ausgewählt werden. Ein Mailprogramm (mutt, mail) sollte auch installiert werden. Wenn Sie Postgres selbst aus den Quellen installieren wollen, dann wählen Sie natürlich nicht Postgres aus.
Danach einmal starten, das
home
-Verzeichnis wird angelegt
5) Das Cygwin-/bin Verzeichnis muss in der Umgebungsvariable PATH vor den Windows Programm-Verzeichnissen liegen, denn die sort.exe von Cygwin muss benutzt werden, nicht die von Windows. Prüfen Sie außerdem im Verzeichnis /bin, ob die bash.exe existiert - dies muss der Fall sein.
6)
Wenn Sie Postgres nativ (d.h. mit dem Windows-Installer von Postgres ab Version 8.x) installiert haben, dann können Sie jetzt aufhören. Der folgende Teil gilt nur für Postgres unter Cygwin:
IPC-Daemon starten
ipc-daemon2 &
Danach ist Postgres bereits installiert. Wenn Sie Postgres selbst aus den Quellen installieren, dann gehen Sie in das Verzeichnis mit den Quellen von postgresql. Die Installationsschritte entsprechen der Linux-Installation, außer dass Sie beim
configure
auch
--enable-odbc
eingeben sollten. Wenn entsprechende Fehlermeldungen erscheinen, müssen Sie noch dafür sorgen, dass (am Beispiel einer Installation von Cygwin in c:\cygwin)
C:\cygwin\usr\local\pgsql\lib\pq.dll
im PATH ist.
7)
Nach der Installation Cygwin neu starten; danach muss unter cygwin ein User installiert werden. Geben Sie dazu ein
mkpasswd -d | grep <<Windows-Username>> >> /etc/passwd
Unter Win95/98/ME muss man das Passwort in
/etc/passwd
noch verschlüsseln; ersetzen Sie den Passus "use crypt" durch die Ausgabe von dem Befehl
crypt <<Ihr Passwort>>
8) Zur Initialisierung von Postgres folgendes eingeben:
ipc-daemon2 &
initdb -D /usr/local/pgsql/data
in
/usr/local/pgsql/data/postgresql.conf
#tcpip_socket=false
# wegnehmen und auf true setzen
Zum Start des Postmaster eine Batchdatei z.B. pgsql_start.x anlegen mit dem Inhalt:
|
pgsql_start.x |
#! /bin/sh ipc-daemon2 & pg_ctl -D /usr/local/pgsql/data -l /var/log/postgres.log -o -i start |
Danach gibt man ein:
chmod +x pgsql_start.x
./pgsql_start.x
Der Postmaster startet dann, und die Logdatei /var/log/postgres.log wird gefüllt.
Den erfolgreichen Start von Postgres kann man prüfen, indem man psql template1 eingibt.
Den postmaster beendet man wie unter UNIX mit
pg_ctl stop –D /usr/local/pgsql/data
Die Installation des Kernmoduls kann danach vorgenommen werden; bei der Umgebungsvariable JAVA_HOME müssen Sie die Windows-Installation von Java verwenden (/cgydrive/<<Windows-Laufwerk>>/<<Pfad zum JDK>>).
Noch ein kleiner Hinweis: Wenn Sie sich von entfernten Rechnern auf dem Cygwin-Server anmelden wollen, müssen Sie den ssh-Daemon installieren (s.u.).
Für die Modulscripte von SuperX wird die leistungsfähige Scripting-Umgebung Cygwin benötigt (unter Windows / DOS gibt es nichts Vergleichbares!). Gleichzeitig bleiben dadurch SuperX-Distributionen plattformübergreifend, durch geringe Anpassungen erreichen wir, dass Scripte unter Unix auch unter Cygwin laufen. Allerdings können Sie Cygwin nur in Verbindung mit Postgres nutzen, nicht mit Informix, weil der Informix-Client dbaccess (nach unserem Wissen) nicht unter Cygwin läuft.
Die folgenden Ausfürhungen gelten also nur für Postgres-Anwender: Sie installieren also zunächst wie oben beschrieben Cygwin und Postgres, allerdings ohne das Paket IPC-Daemon zu installieren. Bei nati vem Windows-Betrieb muss der oben bei Cygwin genannte cygipc -Dienst nicht installiert und gestartet werden. Im Folgenden ein paar Anpassungen für die Bash unter Cygwin.
Beachten Sie, dass in der Konfigurationsdatei $SUPERX_DIR/db/bin/SQL_ENV die Umgebungsvariable PGHOST gesetzt sein muss, und dass der Pfad für die Binaries von Postgres angepasst werden muss.
|
Auszug aus der SQL_ENV für Cygwin und Postgres (nativ) |
case $SX_CLIENT in |
Wenn Sie Cygwin und Postgres-Windows auf einem Rechner nutzen, müssen sie darauf achten, dass beim Öffnen der Cygwin-Shell in der Umgebungsvariable "PATH" auf jedne Fall der Pfad zum Cygwin-psql (normalerweise in /bin ) vor dem Eintrag zum DOS-psql (nomalerweise unter C:\Programme\Postgresql<<Version>>\bin ) liegt, denn die SuperX-ETL-Scripte können mit dem DOS-psql nicht arbeiten.
Noch ein Hinweis für ältere SuperX-Versionen (2.x): Der alte jdbc-Treiber pgjdbc2.jar im Verzeichnis %SUPERX_DIR%\webserver\tomcat\webapps\superx\WEB-INF\lib muss gelöscht und durch den mitgelieferten Treiber pg74.214.jdbc3.jar ersetzt werden. Entsprechende Verweise in der Datei $SUPERX_DIR/db/bin/SQL_ENV (Umgebungsvariable JDBC_CLASSPATH ) müssen entsprechend geändert werden.
Wenn Sie auch einen SSH-Zugriff aus dem Rechner ermöglichen wollen (dies empfehlen wir u.a. wg. der Dateiübertragung mittels rsync ), müssen Sie den SSH-Dämon unter Cygwin starten. Dazu müssen Sie zunächst eine Cygwin-Shell öffnen, und dort eingeben:
ssh-host-config
Es werden einige Dateien generiert, und außerdem werden ein paar Einstellungen abgefragt. Bei dem Fragen zum Account für den SSH-Daemon antworten Sie mit "no", d.h. der aktuelle Cygwin User startet den Dämon (dieser ist ohnehin kein Admin-User). In diesem Falle lässt sich cygwin aber nicht als Dienst einrichten.
Danach startenSie den SSH-Server mit
/usr/sbin/sshd
Danach können Sie sich mit Putty auf dem Server einloggen.
Postgres kann über die normale Paketverwaltung installiert werden. Weiter unten wird beschrieben wie Sie Postgres unter Debian/Ubuntu selbst kompilieren.
Vorbemerkung: Wenn Sie den DB-Server auf einem anderen Rechner betreiben, reicht es die Postgres-Clientpakete zu installieren:
apt-get install postgresql-client-common
apt-get install postgresql-client
Danach sind Kommandos wie psql verfügbar.
Die folgenden Anleitungen gelten nur für den Dienst als Server:
apt-get update
apt-get install postgresql postgresql-contrib
apt-get install policykit-1
(wird für postgresql start/stop benötigt)
Unter Ubuntu finden Sie die Postgresinstallation z.B. unter
/etc/postgresql/9.1/main
. Achten Sie bitte darauf, dass Sie in der SQL_ENV den Pfad für $PGPATH und $PGDATA in der SQL_ENV Ihrer Postgresinstallation dementsprechend anpassen. $PGDATA ist in meiner Beispielkonfiguration unter Ubuntu gleich dem Verzeichnis von $PGPATH.
Wenn Sie auch den Tomcat von Ubuntu nutzen wollen, empfehlen wir Ihnen den Tomcatuser auch in der Datenbank für die SuperX DB Verbindung zu nutzen.
Postgres starten und stoppen Sie mit dem Befehl:
Starten: /etc/init.d/postgresql start
Stoppen: /etc/init.d/postgresql stop
Neustarten: /etc/init.d/postgresql restart
Achtung: Ubuntu legt beim ersten Start den DBSPACE in der Default-Codierung UTF-8 an. Wenn Sie ISO benutzen wollen, müssen Sie die Zeichencodierung ändern .
Bei Postgres 9 wurde z.B. festgestellt, dass standardmäßig eine Codierung „SQL-ASCII“ verwendet wurde, die nicht mit UTF-8 kompatibel ist.
Kontrolle mit psql -l
Damit der Server UTF-8 nutzt, muss man einen ggf. vorhandenes Cluster zunächst löschen:
[Als user postgres:]
pg_dropcluster 9.5 main
oder nach Version
pg_dropcluster 10 main
ggfs anzeigen
pg_lsclusters
Danach geben Sie ein:
pg_createcluster -e UTF-8 9.5 main (bzw. 10)
Damit wird ein DBSPACE angelegt in /var/lib/postgresql/9.5/main
für ISO-8859:
initdb --encoding=LATIN 9 --locale=de_DE@euro -D $PGDATA
Danach müssen Sie den Postgres-Dienst neu starten (s.o.).
Um Postgres zu kompilieren benötigen Sie die folgenden Pakete (Beispiel Ubuntu 19.04):
apt-get install -y gettext libreadline8 libreadline-dev zlib1g zlib1g-dev
Danach gehen Sie vor wie im Kapitel Neuinstallation (am Beispiel derVersion 7.3.4) beschrieben.
Danach können Sie testen:
psql template1
Die Ausgabe sollte sein:
psql (9.5.12)
Type "help" for help.
template1=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+------------+------------+-----------------------
postgres | postgres | UTF8 | de_DE.utf8 | de_DE.utf8 |
template0 | postgres | UTF8 | de_DE.utf8 | de_DE.utf8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | de_DE.utf8 | de_DE.utf8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
Danach können Sie den Postgres-Superuser einrichten:
createuser - s superx
Um Postgres unter Redhat zu installieren muss zuerst ein passendes Repository eingerichtet sein. Die Liste der Repositories geben Sie mit:
yum repolist
aus. Wenn hier Repositories eingetragen sind, suchen Sie als nächstes nach dem Postgres Paket:
yum search postgres
Je nachdem, welche Repositories eingerichtet sind, kann die Postgres Server Version unterschiedlich sein. In dem Beispiel wird die Version:“postgresql84-server.x86_64“ installiert:
yum install postgresql84-server.x86_64
Wenn Postgres installiert wurde, befindet sich das „data“ Verzeichnis unter:
/var/lib/pgsql/data/
Vor data kann auch noch die Versionsnummer von Postgres als Verzeichnis liegen.
Die Datenbank wird initialisiert mit:
service postgresql initdb
Wenn Postgres automatisch mit dem Systemstart mit gestartet werden soll, machen Sie das mit dem folgenden Befehl:
chkconfig postgresql on
Start/Stopp Befehle für Postgres:
service postgresql <command>
für <command> kann folgendes verwendet werden:
start : startet die Datenbank
stop : stoppt die Datenbank
restart : neustart der Datenbank – Nach Änderungen an der Konfiguration
reload : reload pg_hba.conf Datei. Dabei läuft die Datenbank weiter.
Sie installieren Postgres aus der Distribution mit
zypper -n in -l postgresql
zypper -n in -l postgresql-server
zypper -n in -l postgresql-contrib
Vor dem ersten Start müssen Sie die Sprachumgebung einrichten. Prüfen Sie die installierten Locales mit
locale -a | grep de
Die gewünschte Lolcale, in der Regel de_DE.utf8 , tragen Sie dann in der Datei /etc/sysconfig/postgresql ein, bei der Variable
POSTGRES_LANG="de_DE.utf8"
Danach starten Sie den Server als root mit
rcpostgresql start
Der DBSPACE wird in /var/lib/pgsql/data angelegt, dort liegen dann die Dateien postgresql.conf und pg_hba.conf .
Damit der Server beim Booten hochfährt, geben Sie ein:
chkconfig --set postgresql on
Dann wechseln Sie in die Shell des Users postgres, und legen den User an mit
createuser --superuser superx
Der Optimierer unter Postgres läßt sich uber die Kommandozeile mit
vacuumdb --analyze --verbose -f -d $DBNAME
starten und hilft bei regelmäßiger Anwendung, deshalb empfehlen wir, diesen Befehl als Cronjob jede Nacht oder einmal pro Woche auszuführen.
Wichtige Parameter sind die "Shared buffers" und der "Effective cache size". Shared buffers meinen nicht das gesamte zur Verfügung stehende RAM (das verwaltet das System), sondern den Arbeitsspeicher, der Postgres zum Zwischenspeichern benutzt, bevor Abfragen an den Kernel geschickt werden. Der Wert sollte nicht zu hoch gewählt werden, weil dann die Performance nachlässt. Faustregel: 6-15% des physischen RAM, man sollte aber auch in der Praxis viel probieren. Generell sollte man auf Datenbankservern mind. die Hälfte des verfügbaren physischen Rams für Postgres reservieren.
Beim Start des Postmasters lassen sich die "Shared buffers" zuweisen mit der Option
postmaster –o "–B 128"
Dabei wird das Shared Memory von (standardmäßig) 64*8192 Bytes auf 128*8192 Bytes erhöht. Man kann den Parameter aber auch in der postgresql.conf setzen.
|
Beispielkonfiguration Postgres-RAM bei DB-Server mit 1 GB RAM unter Suse Linux |
in der Datei
/etc/init.d/boot.local
geben Sie ein:
Die Parameter lassen sich auch zur Laufzeit aus einer root-Shell setzen. Danach ersetzen Sie in der
postgresql.conf
die folgenden Parameter: Danach starten Sie Postgres neu. |
Die checkpoint segments sollen Sie erhöhen, wenn Sie in den Postgres-Logs folgende Meldung bekommen:
LOG: Checkpoints passieren zu oft (alle xx Sekunden)
TIPP: Erhöhen Sie eventuell den Konfigurationsparameter "checkpoint_segments".
In der Postgres-Auslieferung sind checkpoint segments=3 vorgegeben, bei großen Anwendungen sollten Sie großzügig erhöhen, z.B. 24.
Effective Cache Size sollte als Faustregel 25% des physischen RAM betragen.
Diese und weitere Perfomance-Tipps für das jeweilige Betriebssystem finden Sie im PostgreSQL Administrator's Guide im Abschnitt "Run-Time Configuration".
Leider lassen sich Transaktionen für Postgres nicht abschalten, für ein (passives) Berichtssystem wie SuperX wären Transaktionen unbedeutend.
Autovacuum wurde mit Postgres 8 eingeführt. Für SuperX empfehlen wir dies nicht, denn das Vacuum wird in der Laderoutine ohnehin jede Nacht ausgeführt, und Autovacuum-Prozesse stören die Laderoutine, teilweise empfindlich.
Falls Sie für Testzwecke einen User „ alex “ anlegen wollen, der alle Tabelle n einer DB lesen kann, geht dies mit Postgres so:
Zunächst müssen Sie in der pg_hba.conf sicherstellen, dass Passwort-Anmeldung über IP4 möglich ist:
# TYPE DATABASE USER ADDRESS METHOD
host all all <<IP-Nummernkreis>> md5
Dann starten Sie Postgres neu oder führen einen RELOAD aus, z.B. unter Linux:
/etc/init.d/postgresql reload
Dann gehen Sie als Superuser auf den DB-Server, und führen Sie in der Ziel-Datenbank folgende SQLs aus:
CREATE USER alex WITH NOSUPERUSER PASSWORD 'password';
GRANT USAGE ON SCHEMA public TO alex ;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO alex ;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO alex ;
Der letzte Befehl sorgt dafür, dass auch neue Tabellen Berechtigung erhalten.
Wenn Sie das Passwort später ändern wollen schreiben Sie
alter USER alex WITH PASSWORD 'anfang12';
Zur Erhöhung der Sicherheit ist es möglich, dass die Datenbankverbindung von Tomcat zur Datenbank mit einem eingeschränkten User durchgeführt wird. Richten Sie dazu einen entsprechenden User in Ihrer Datenbank ein und geben Sie diesen beim Propadmin bei eingeschränkter User an.
Der erste im Propadmin auszufüllende User muss weiterhin umfassende Rechte auf alle Tabellen haben, weil er auch bei Modulinstallationen/-updates verwendet wird. Das Minimum, was der eingeschränkte User haben muss sind select-Rechte auf alle Tabellen, insert-Rechte auf die Tabelle protokoll und update-Rechte auf userinfo .
Sobald Sie Ihre db.properties mit dem Propadmin bearbeitet haben, sieht die db.properties z.B. so aus:
restrictedConnectionName=superx_restricted
connectionPassword=sx_des\#8\#-127\...
restrictedConnectionPassword=sx_des\#34\#76...
Nun können Sie auf DB-Ebene die nötigen Rechte vergeben. Zunächst sollten Sie modulweise die vorgefertigten Scripte von uns aufrufen. Diese sind DBMS-spezifisch, und durch entsprechende Aufrufe könen Sie steuern, daß einzelne Module (z.B. Stellen, Personal) nicht lesbar sind (siehe unten).
Zur Sicherheit sollten Sie zunächst alle Rechte entfernen, und dann explizit vergeben.
Wenn Sie keine modulspezifischen Tabellenrechte benötigen, können Sie praktisch die Leserechte auf alle Tabellen vergeben, in dem Sie einmal das Skript
sx_restrictedconnmanager.x false aufrufen .
Wenn Sie Funktionen wie User/Gruppe/Maske einrichten/löschen etc. im XML-Frontend benutzen wollen, müssen zusätzliche Kernmodultabellen freigeschaltet werden:
sx_restrictedconnmanager.x true
Nach einem Tomcat-Neustart findet sich in der catalina.out nach "Aufbau von Datenbank-ConnectionPool (..) .. OK" ein Hinweis:
eingeschränkter Datenbankuser für Verbindung: true|false
Achtung bei Informix: wenn ein Benutzer unter Unix angelegt wurde, hat der automatisch Rechte auf alle Datenbanken, die lokal liegen.
Bei Informix haben standardmäßig alle Datenbankobjekte Rechte für die Gruppe "public", d.h. alle angemeldeten Benutzer. Bei Informix muss man daher alle Objekte der Gruppe "public" entziehen, und dann dem jew. User explizit geben.
Beispiel für "Entfernen von Rechten" unter Informix für den User "superx_restricted":
#!/bin/sh
#das folgende Script nimmt dem User superx_restricted alle Rechte auf SuperX-Tabellen:
#Kernmodul:
install/conf/module_revoke.x "all" public
#nur zur Sicherheit:
install/conf/module_revoke.x "all" superx_restricted
for i in bau cob erfolg fin gang ivs kenn sos zul sva; do
module/$i/conf/module_revoke.x "all" public
#nur zur Sicherheit:
module/$i/conf/module_revoke.x "all" superx_restricted
done
Danach vergeben Sie Rechte gezielt für den User "superx_restricted", hier z.B. für alle Module außer SVA:
#das folgende Script gibt dem User superx_restricted Rechte auf alle Tabellen ausser SVA:
#DOQUERY "GRANT USAGE ON SCHEMA superx TO superx_restricted;"
install/conf/module_grant.x "select" superx_restricted
#Recht, temp.Tabellen anzulegen:
DOQUERY "grant resource to $GRANTEE;"
for i in bau cob erfolg fin gang ivs kenn sos zul; do
module/$i/conf/module_grant.x "select" superx_restricted
done
Anders als bei Informix ist der Datenbank-User unabhängig vom Betriebssystem-User, d.h. Man muss den Benutzer in Postgres manuell anlegen und Rechte vergeben.
create user superx_restricted with password 'anfang12';
Wenn der Benutzer kein Superuser ist, hat er zunächst keinerlei Leserechte auf vorhandene Datenbankobjekte, er kann aber neue Objekte,z.B. Tabellen, erzeugen.
Man kann also direkt die "grant"-Befehle absetzen, z.B. Tabellenrechte für alle Module außer SVA:
#das folgende Script gibt dem User superx_restricted Rechte auf alle Tabellen ausser SVA:
install/conf/module_grant.x "select" superx_restricted
for i in bau cob erfolg fin gang ivs kenn sos zul; do
module/$i/conf/module_grant.x "select" superx_restricted
done
Nach erfolgreicher Installation des Datenbankservers muss der Server als Dienst eingerichtet werden. Wir haben das Vorgehen für die Betriebssysteme RedHat 8.0 und SuSE Linux 7.x-8.x beschrieben (für Debian ebenfalls, aber diese Scripte haben wir noch nicht getestet).
Im Kernmodul befinden sich unter /home/superx/db/etc die Vorlagen für den DB-Server. Die Ordnerstruktur entspricht dem Linux-Rechners auf oberster Ebene. Kopieren Sie die Dateien als root in die entsprechenden Verzeichnisse, z.B. bei Redhat-Linux
$SUPERX_DIR/db/etc/init.d/superx_db.redhat
nach
/etc/init.d/superx_db
Ebenso verfahren Sie mit den Dateien in
$SUPERX_DIR/db/etc/sysconfig
.
Dann machen Sie die User informix / postgres zu Eigentümern der Dateien.
Die Variablen, die ggf. angepasst werden müssen, sind
SUPERX_USER
JAVA_HOME und andere Variablen aus $SUPERX_DIR/db/bin/SQL_ENV
(wenn Sie SuperX in einem anderen Verzeichnis als /home/$SUPERX_USER installiert haben, müssen Sie die Pfade zu TOMCAT_START und TOMCAT_STOP entsprechend anpassen).
Dann erzeugen Sie als root die leere Datei
/var/log/superx.log
und machen den User superx zum Eigentümer
chown superx:users /var/log/superx.log
Analog verfahren Sie mit
•
/var/log/informix
und machen den user
informix
zum Eigentümer
bzw.
• /var/log/postgres und machen den user postgres zum Eigentümer
•
Dann
•
kopieren Sie die Datei
$SUPERX_DIR/db/etc/home_informix/start.sh
in das Homeverzeichnis von
Informix
,
und machen den user
informix
zum Eigentümer
bzw.
•
kopieren Sie die Datei
$SUPERX_DIR/db/etc/home_postgres/start.sh
in das Homeverzeichnis von
postgres
,
und machen den user
postgres
zum Eigentümer.
Kontrollieren Sie, ob die Datei start.sh Ausführungsrechte besitzt.
Zur Aktivierung der Dienste für den Runlevel 3 führen Sie jeweils folgende Schritte durch; erzeugen Sie einen symbolischen Link für das Script superx-db im Runlevel 3 und 5
Redhat/Mandrake:
ln -s /etc/rc.d/init.d/superx_db /etc/rc.d/rc3.d/S90superx_db
ln -s /etc/rc.d/init.d/superx_db /etc/rc.d/rc5.d/S90superx_db
ln -s /etc/rc.d/init.d/superx_db /etc/rc.d/rc3.d/K90superx_db
ln -s /etc/rc.d/init.d/superx_db /etc/rc.d/rc5.d/K90superx_db
SuSE 8.x:
ln -s /etc/init.d/superx_db /etc/init.d/rc3.d/S98superx_db
ln -s /etc/init.d/superx_db /etc/init.d/rc5.d/S98superx_db
ln -s /etc/init.d/superx_db /etc/init.d/rc3.d/K98superx_db
ln -s /etc/init.d/superx_db /etc/init.d/rc5.d/K98superx_db
Debian,LSB:
ln -s /etc/init.d/rc/superx_db /etc/init.d/rc3.d/S98superx_db
ln -s /etc/init.d/rc/superx_db /etc/init.d/rc5.d/S98superx_db
ln -s /etc/init.d/rc/superx_db /etc/init.d/rc3.d/K98superx_db
ln -s /etc/init.d/rc/superx_db /etc/init.d/rc5.d/K98superx_db
Danach können Sie als root testen, ob die Scripte laufen, indem Sie als root
/etc/init.d/superx_db start
zum Starten der Datenbank ausführen, und sowie
/etc/init.d/superx_db stop
zum Stoppen der Datenbank.
Etwaige Fehlermeldungen stehen in Logdatei /var/log/informix.log, postgres.log bzw.
superx.log
Für die Installation haben wir eine Kurzanleitung vorbereitet. Das Kernmodul der Datenbank liegt exportiert vor und kann in das DBMS übernommen werden. Die nachfolgenden Installationschritte gehen davon aus, daß Sie keinen speziellen DBSpace für SuperX vorgesehen haben.
Das Installationsscript für die Datenbank befindet sich im Verzeichnis
$SUPERX_DIR/db/install/kernmodul_erzeugen.x <<ggf. mit Name des DBSpace>>
Das Script läuft nur, wenn die Parameter in der Datei $SUPERX_DIR/db/bin/SQL_ENV stimmen . Bei erfolgreichem Ablauf kommt eine Erfolgmeldung, im Falle eines Fehlers wird die Fehler-Logdatet create.log angezeigt. Wenn ein Fehler auftritt, müssen sie die Datenbank vor einem erneuten Ablauf des Scriptes droppen.
Wenn Sie bei der Postgres Installation nicht den Parameter --enable-multibyte=LATIN1 angegeben haben müssen Sie eventuell in dem Script kernmodul_erzeugen.x die Variable ENCODING auf LATIN1 setzen.
Danach können Sie mit dbaccess superx (unter Informix) bzw. psql superx (unter Postgres) testen, ob die Datenbank verfügbar ist.
Schließlich sollten Sie die Tabelle hochschulinfo anpassen und die Daten Ihrer Hochschule dort eingeben, insbesondere die Hochschulnummer (apnr-Wert in cifx mit key=36).
Vor dem Start der Update-Scripte sollte immer eine Sicherung der Datenbank erfolgen. Für Backups ist es notwendig, die Datenbank regelmäßig zu exportieren. Beide Datenbanken bieten entsprechende Werkzeuge.Es bietet sich an, einen cronjob einzurichten, der zuerst das Backup vornimmt, und dann die einzelnen Module nacheinander aktualisiert.
Ein Beispiel-Eintrag der crontab des users superx liegt in $SUPERX_DIR/db/module/crontab.sam . Ein Beispiel-Update-Script liegt in $SUPERX_DIR/db/module/update.x.sam . Der Eintrag in der crontab, der das Script werktags um 18:00 Uhr startet, sähe dann wie folgt aus:
|
Beispieleintrag in der crontab des users |
# Täglicher SuperX-Update um 18 Uhr # 00 18 * * 1-5 /home/superx/db/module/update.x >>/home/superx/db/module/update.log 2>&1 |
Ein Beispielinhalt für das Script update.x ist Teil des Kernmoduls:
|
Beispiel-Updatescript für SuperX: |
#!/bin/sh |
Ein Beispielscript, das die Datenbank sichert, liegt in $SUPERX_DIR/db/install/dump_it.x . Es erzeugt den Dump im Verzeichnis $SUPERX_DIR/db/install , prüft die erfolgreiche Sicherung und verschickt ggf. eine Fehler-Mail. Wenn Sie das Script in einem Cronjob betreiben wollen, müssen Sie als ersten Parameter $SUPERX_DIR übergeben.
Die Rücksicherung einer Datenbank ist mit dem Script $SUPERX_DIR/db/install/restore_it.x möglich.
Die Datenbank lässt sich mit dem Kommando dbexport –o <Pfad> superx exportieren und sichern. Beachten Sie aber, dass durch das Servlet eine (oder mehrere) Verbindungen zur Datenbank geöffnet ist. Deshalb muss das Servlet beendet werden oder die Datenbank muss vom User Informix einmal auf quiescent und dann wieder auf online gesetzt werden, damit eventuell noch ablaufende SuperX-Prozesse beendet werden.
Postgres lässt sich auch im laufenden Betrieb sichern.
In unserem Dump-Script wird der Dump mit dem Parameter "--inserts" versehen. Dies ist eine sehr vorsichtige Einstellung, aber der Dump ist dadurch maximal kompatible zu verschiedenen Postgres-Versionen, außerdem tauchen keine Probleme mit Umbrüchen in langen Textfeldern auf.
Wenn Ihnen die resultierenden Dumps zu groß sind, können Sie in einem eigenen Dump auf die Inserts verzichten,z.B. mit
pg_dump -f superx.sql superx
Noch kompakter ist der Dump als Binärfile mit dem Parameter --format=c:
pg _dump -f $DBNAME.sql --format=c $DBNAME
Zunächst ist es wichtig, eine Verbindung vom Webserver zum Datenbankserver zu bekommen. Dazu gibt es verschiedene Werkzeuge.
superx_server 1542/tcp
hinzufügen.
Nun können Sie Parameter für den Zugang von WIN32-Rechnern auf den Datenbankserver überprüfen. Der beste Weg dafür ist das Werkzeug iLogin, das von Informix in den Client-SDKs mitgeliefert wird. Die folgende Abbildung zeigt ein Beispiel für die Parameter beim iLogin
|
Die Parameter sind oben bereits erläutert. Ein erfolgreicher iLogin ist Voraussetzung für das weitere Vorgehen! |
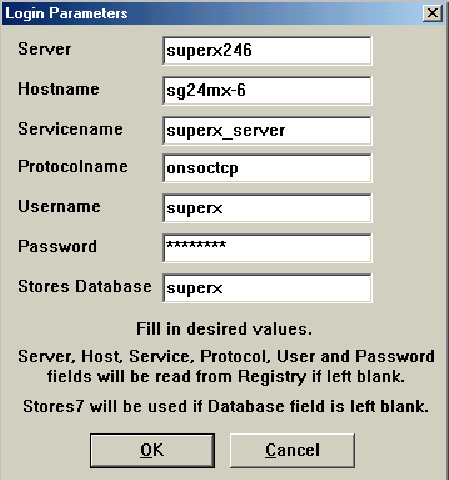
|
Für den regulären SuperX-Betrieb ist dieser Schritt nicht unbedingt erforderlich. Wenn Sie allerdings unter Win32 direkt auf die Datenbank zugreifen möchten, z.B. um Microsoft Access als Frontend einzusetzen, müssen Sie SuperX als ODBC-Quelle einrichten. Für die Informix-Datenbank gibt es eigene Treiber für den ODBC-Zugriff (für IDS 7.31 gibt es Intersolv 3.10 oder 3.11). Diesen Treiber muss man sich zunächst von www.informix.com besorgen. Meist sind die Treiber Teile des Informix Client SDK; für den reinen ODBC-Zugriff reicht es vollkommen aus, bei der Installation Custom zu wählen und nur den ODBC-Treiber zu installieren.
Zur Installation:
Systemsteuerung -> (Win 2000: Verwaltung)-> Datenquellen (ODBC)->System-DSN -> Hinzufügen
|
Für IDS 7.31 kann man als ODBC-Treiber z.B.den Intersolv 3.11-Treiber wählen. Dieser befindet sich im Informix Client SDK 2.40 (der 3.10-Treiber geht auch, der ist im Informix Client SDK 2.02). Für den IDS 9.21 benötigt man den Treiber Informix 3.33, der Teil des Client SDK 2.60 ist. Version 3.34 läuft ebenfalls. |
|
|
Der Datenquellen-Name ist superx.
|
|
|
Als Datenbank-Name die SuperX-Datenbank angeben. Für die Verbindung die rechten Parameter eingeben (Achtung: Beispielangaben für Duisburg); wichtig sind der Hostname, der Service-Name (s.u.) und der Server.
|
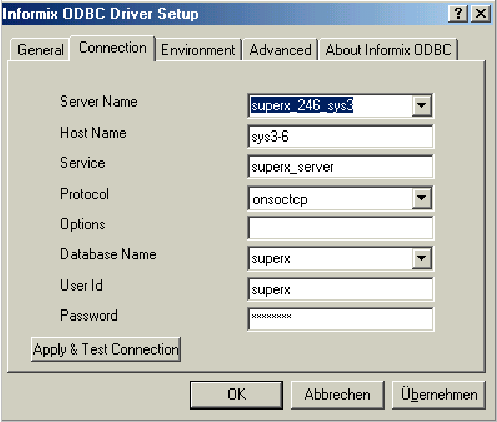
|
Get-DB-List from Informix kann man deaktivieren. Manche ODBC-Treiber erlauben es in den erweiterten Optionen (Environment), eine DB-Locale zu definieren; wir empfehlen, diese auf Use Server Database Locale zu setzen.
|
Vorsicht mit ODBC |
Der Informix-ODBC-Treiber 3.8 darf auf keinen Fall benutzt werden, er ist extrem fehlerhaft und kann zum Datenverlust führen. |
Beachten Sie ggf., dass diese Installation unter NT/ Win 2000 kennungsabhängig ist.
Der ODBC-Treiber für Postgres ist vom Postgres-Projekt verfügbar ( www.postgresql.org ). Er ist in der 8.0-Distribution von Postgres bereits enthalten. Der Treiber lässt sich leicht installieren, indem Sie in der Systemsteuerung über Verwaltung -> ODBC-Datenquellen eine Datenquelle einrichten, z.B. mit dem Namen superx.
|
Der Datenquellen-Name ist superx, der Datenbankname ebenfalls. Bei Server geben Sie den Hostnamen oder die IP-Nummer ein, und rechts den Port. Die Kennung ist hier z.B. superx . |
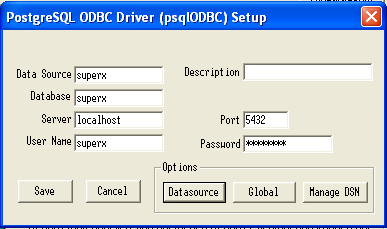
|
Im Dialog "Options-> Datasource" müssen einige Einstellungen vorgenommen werden:
|
Setzen Sie die Data Type Options wie rechts angezeigt. Das Kreuz bei
Bools as Char
ist notwendig, weil Access oder andere Frontends sich mit Postgres bei Binären Datentypen nicht vertragen. Boolean-Felder werden mit "1" oder "0" codiert. |
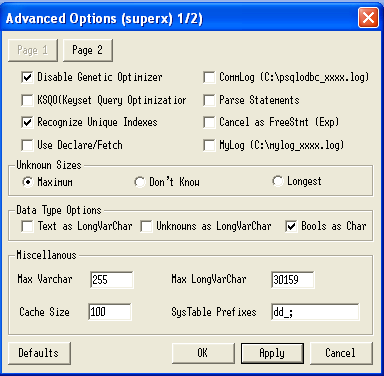
|
Auf der zweiten Seite sind die Defaults korrekt.
|
Die Linefeed-Umsetzung ist wegen der Scripte in SuperX-Textfeldern notwendig. |
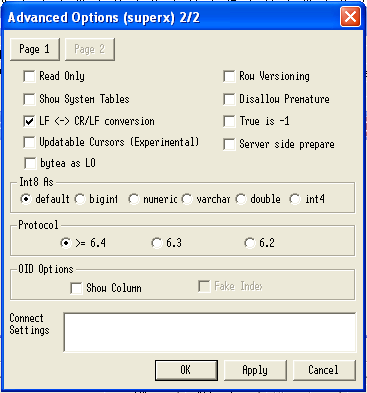
|
Wenn Sie die SuperX-Datenbank als ODBC-Quelle unter dem Namen superx eingerichtet haben, dann können Sie das im SuperX-Clientpaket unter $SUPERX_DIR/tools/access/superx_frontend_sam.mdb enthaltene Access-2000-Frontend benutzen. Bei der Datei handelt es sich um ein Muster, vor dem ersten Gebrauch kopieren Sie sie bitte nach $SUPERX_DIR/db/superx_frontend.mdb und arbeiten Sie nur mit letzterer Datei - so können Sie sichergehen, dass Ihr Access-Frontend nicht bei einem SuperX-Update überschrieben wird.
Beim ersten Öffnen der Datei sind die Tabellen noch nicht verknüpft. Sie müssen zunächst Das Formular Setup aufrufen, den Namen der ODBC-Quelle (s.o.) eintragen, und "Erzeuge Kernmodul-Verknüpfungen" drücken. Wenn der Informix-Treiber dies unterstützt, sollte vorher die Option "Passwort speichern" aktiviert werden, ansonsten muss man für jede Tabellenverknüpfung das Passwort eingeben.
|
Die Datenquelle wird eingegeben, und die Kernmodul-Tabellen können so verknüpft werden. Die Verknüpfungen haben nach Access-Voreinstellung den Namen |
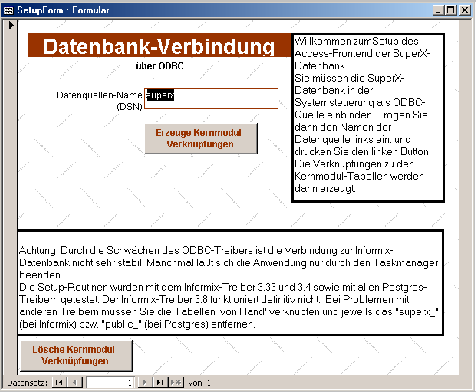
|
Falls der Setup so nicht funktioniert, müssen die Tabellen "von Hand" verknüpft und umbenannt werden. Die Funktionalität des Access-Frontends ist dadurch nicht beeinträchtigt. Bei Tabellen ohne Primary Key muss allerdings ein eindeutiger Datensatzbezeichner angegeben werden, sonst ist die Tabelle schreibgeschützt.
Wenn Sie die Verfügbarkeit des Datenbankservers getestet haben (z.B. über das Utility iLogin von Informix), dann müssen die Datenbankparameter in die Datei
$SUPERX_DIR/webserver/tomcat/webapps/superx/web-inf/db.properties
übertragen werden, damit das Servlet eine Verbindung zur Datenbank herstellen kann. Ein Muster für Informix und eines für Postgres ist bereits im Kernmodul enthalten. Kopieren Sie die Datei db-informix.properties bzw. db-postgres.properties nach db.properties . Das voreingestellte Passwort lautet hier "anfang12".
Zur Erstellung und ggfs. Änderung dieser Datei gibt es ein Tool: propadmin.x . Das Shellscript liest aus der Umgebungsvariable $DB_PROPERTIES (oder über den ersten Parameter) den Speicherort der db.properties ein; in der Regel muss das die obige Position sein, damit das Servlet die Datei findet. Ausnahmen gibt es nur, wenn SuperX über den jdbc-Client auf eine andere Datenbank zugreifen soll.
Starten Sie das Tool von einer Konsole bzw. Eingabeaufforderung das Tool mit dem Befehl
propadmin.bat
bzw.
propadmin.x
(unter Linux).
Füllen Sie die Felder entsprechend des folgenden Beispiels (zunächst Postgres, dann Informix):
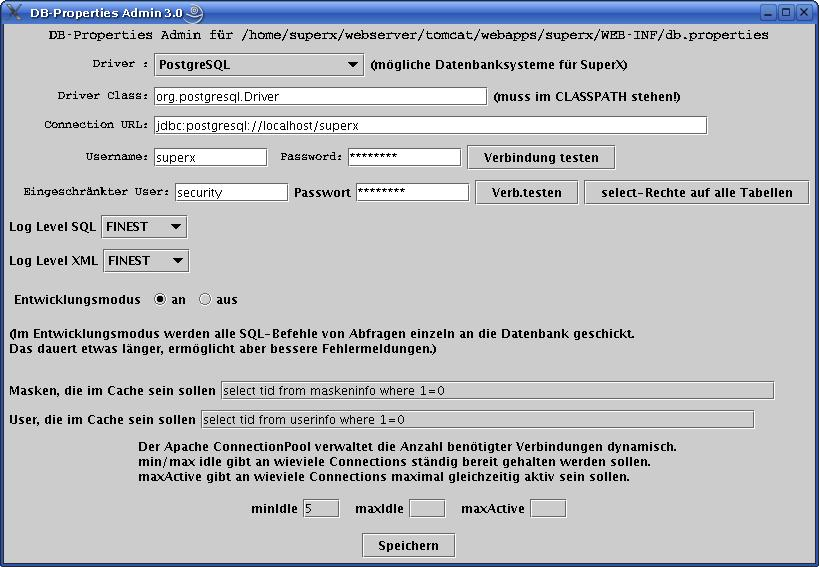
Hinweis für Postgres: Wenn Sie Postgres auf einem anderen Port als dem voreingestellten 5432 betreiben, müssen Sie im jdbc-Treiber als Connection-URL den Port wie folgt angeben:
connectionURL=jdbc:postgresql://localhost:<<Portnumer>>/superx
Bei Informix könnte es beispielsweise so aussehen:
|
Nehmen wir z.B. für Informix die Parameter beim ILogin (oben erläutert). Wenn die rechte Abbildung eine korrekte Einstellung anzeigt, .... |
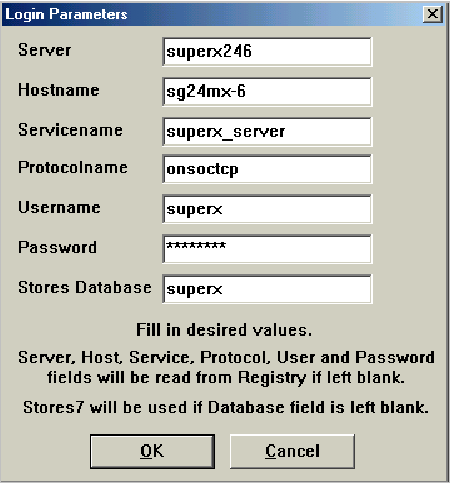
|
...dann übernehmen Sie die Parameter wie folgt für die db.properties :
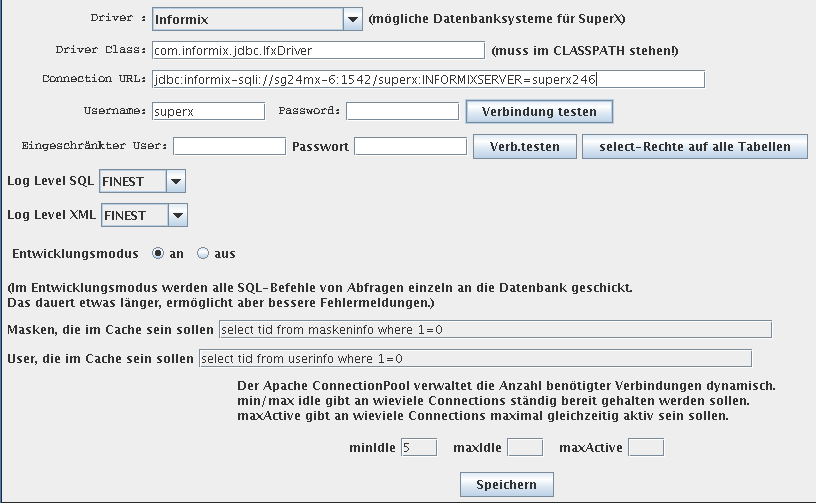
Der Port 1542 ergibt sich aus dem Service für SuperX, der oben bereits beschrieben wurde.
Die Parameter für den LogLevel können auf einer Skala von fünf Stufen gewählt werden: FINEST bis SEVERE. Bei FINEST wird fast alles geloggt, bei SEVERE werden nur Fehler geloggt .
Im Entwicklungsmodus werden alle SQL-Befehle von Abfragen einzeln an die Datenbank geschickt.Das dauert etwas länger, ermöglicht aber bessere Fehlermeldungen. Man kann diese Einstellung auch im laufenden Betrieb ändern.
Die Parameter im Cache legen fest, wie viel Information gecached werden werden sollen. Standardmäßig wird nichts gecached, aber im Produktiveinsatz sollten hier die entsprechenden Parameter gewählt werden.
In den Connection-Pool Angaben wird angegeben, wieviele Verbindungen maximal gleichzeitig vom Servlet zur Datenbank hergestellt werden sollen.
Durch Anklicken von OK wird die Datei db.properties (bzw. der Pfad zum Inhalt der Umgebungsvariable DB_PROPERTIES) erstellt, wobei das Passwort verschlüsselt wird. Vorher sollten Sie mit "Verbindung Testen" prüfen, ob eine Datenbankverbindung hergestellt werden kann. Wenn dies nicht klappt, sollten die Fehlermeldungen weiterhelfen.
Wenn Sie einen UNIX / LINUX-Server für Tomcat betreiben wollen, dann ist es möglich, daß Sie unter Linux keine graphische Java-Umgebung starten können. In diesem Fall müssen Sie das Kernmodul auf einem Rechner mit installiertem Java und graphischer Umgebung kopieren, das Programm dort aus der Konsole starten und die Parameter ändern (wichtig: der Rechner muss die gleiche Zeichenkodierung haben, also LATIN1). Danach kopieren sie die Datei db.properties mit scp / WinSCP auf den UNIX-Rechner. Alternativ können Sie die Parameter mit dem vi bearbeiten. Wenn der Propadmin ohne graphische Umgebung gestartet wird, kann lediglich das Passwort eingegeben werden.
Wenn Sie Tomcat auf einem anderen Rechner als dem Datenbankserver betreiben, müssen Sie die Startdateien
propadmin.bat
bzw.
propadmin.x
im Verzeichnis
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF
benutzen (in diesem Falle ist das Verzeichnis $SUPERX_DIR/db nicht notwendig.)
Für den Informix JDBC Treiber kann angegeben werden wo Temporäre und Cache Dateien abgespeichert werden. Im Normalfall wird dafür das aktuelle Verzeichnis verwendet. Wenn der Tomcat als Service gestartet wird, ist es nicht immer ganz klar, wo das nun liegt und ob dort nun die richtigen Berechtigungen vorliegen. Um Problemen vorzubeugen wird empfohlen die Connection Property JDBCTEMP zu setzen. Der angegebene Pfad sollte von Root („/“) aus gehen. Beispiel:
connectionURL=jdbc\:informix-sqli\://superxdb\:1542\:informixserver\=superxdb;database\=superx;JDBCTEMP\=/tmp
Wenn in der catalina.out folgende Fehlermeldungen auftauchen, kann der Parameter JDBCTEMP die Lösung sein:
java.sql.SQLException: Blob not found
java.io.IOException: Permission denied
Der Parameter LOBCACHE steuert wo der Cache abgelegt wird. Positive Zahlen gibt die maximale Anzahl an bytes an, die im Arbeitsspeicher angelegt werden. „0“ bedeutet, alles wird im Dateisystem in Temp Ordner abgelegt. Und bei negativen Zahlen wie -1 wird alles im Arbeitsspeicher abgelegt. Es kommt dann allerdings zu einem Fehler, wenn dieser voll ist.
Weitere Infos hier:
http://www.ibm.com/support/knowledgecenter/SSGU8G_11.50.0/com.ibm.jdbc_pg.doc/ids_jdbc_040.htm
Neben der normalen Properties-Konfiguration muss außerdem der Verbindungsparameter für die Servlets von DBFORMS gesetzt werden.
Die zentrale Steuerungsdatei heißt dbforms-config.xml und liegt im Verzeichnis SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF . Dort liegt bereits ein Muster mit dem Namen kern_dbforms-config_pg.xml für Postgres bzw. kern_dbforms-config_ids.xml für Informix. Diese Datei wird bei der Installation automatisch kopiert nach dbforms-config.xml .
Die Datenbankverbindung wird in der Datei $WEBAPP/META-INF/context.xml konfiguriert . und am Ende der Datei die Connection-Attribute angeben. Die Parameter sind identisch mit denen, die Sie in der db.properties angeben.
Wenn Sie die DBFORMS-Komponente nicht benötigen bzw. aus Sicherheitsgründen für eine externe Website abschalten wollen, gehen Sie wie folgt vor:
|
Aktion |
Code |
|
Sperren Sie das dbforms-Servlet in der Datei $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/web.xml , indem Sie die rechts blau markierten Kommentarzeichen um die entsprechenden Elemente setzen. |
... |
|
Fügen Sie an das Ende der web.xml vor dem End-Tag "</web-app>" folgende Elemente ein |
... |
|
Ändern Sie am Ende der Datei $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/dbforms-config.xml beim Element dbconnection den Attributnamen "name" auf einen nicht existenten Namen, z.B. "superx1". |
<dbconnection id="superx" isJndi="true" name="java:/comp/env/jdbc/superx 1 "/> |
|
Starten Sie Tomcat neu, und prüfen Sie in der Logdatei $SUPERX_DIR/webserver/tomcat/logs/catalina.out , ob der Tomcat-Start erfolgreich war. |
|
Durch diese Maßnahme sind der DBFORMS-Komponente keine Datenbankverbindungen mehr möglich, und das Ausspähen geschützter Dateien in Tomcat-Systemverzeichnissen durch das Control-Servlet ist nicht mehr möglich.
Eine Abschaltung der DBFORMS beeinträchtigt in keiner Weise die "normalen" Funktionen zur Berichtserstellung von SuperX.
Mit der oben beschriebenen Installation ist die Datenbankverbindung zwischen Client und Server noch unverschlüsselt. Zur Verschlüsselung kann einerseits die native Verschlüsselung im DBMS eingeschaltet werden. Man kann aber auch Datenbankverbindungen durch einen zusätzlichen ssh-Tunnel verschlüsseln. Zum Tunneln z.B. von Postgres von einem entfernten Rechner über ssh gehen Sie wie folgt vor:
Unter Windows:
• Starten Sie den ssh-Client putty (z.B. von http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html )
• Erzeugen Sie ggf. eine neue Session, indem Sie auf der obersten Seite "Sessions" den Host Name, Port, Protocol=ssh eintragen.
• Geben Sie dann bei saved sessions einen neuen Namen, und drücken Sie sicherheitshalber "Save".
• Geben Sie im Menüpunkt "Connection" bei "Auto-Login username" den Namen "superx" an.
• Geben Sie im Menüpunkt "SSH"->"Tunnels" unten im Menü "Add new forwarded Ports"
• bei "Source Port" z.B. "9998" ein.
• Bei "Destination" geben Sie "localhost:5432" ein (wenn 5432 der Port ist, auf dem Postgres läuft).
• Lassen Sie "Local" angekreuzt, und drücken Sie dann darüber "Add")
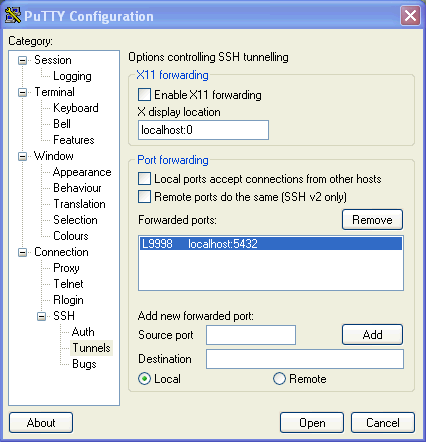
• Dann speichern Sie die Session auf der obersten Seite "Sessions"
• Dann drücken Sie unten "Open" und loggen sich ein.
Unter Unix/Linux:
Geben Sie einfach in der Shell ein:
ssh superx@<<IP-Nr. des DB-Servers>> -L 9998:localhost:5432
In diesem Moment ist der Tunnel eingerichtet. Sie können ihn nun nutzen, wenn Sie mit Ihrem JDBC- oder ODBC-Client auf den Port localhost:9998 zugreifen.
Z.B. für die sqlWorkbench unter Postgres im Dialog "Connect" die URL
jdbc:postgresql://localhost:9998/superx
Der Tunnel wird geschlossen wenn Sie sich ausloggen. Sie müssen übrigens nicht den Hostnamen des Client-Rechners in die pg_hba.conf eintragen, für Postgres verhält sich der Tunnel so, als ob vom Rechner "localhost" auf den Server zugegriffen wird. Auch in der Firewall des DB-Servers muss nur der SSH-Port freigeschaltet sein, nicht der Datenbank-Port.
Bei Problemen ist ggf. im SSH-Server das Port-Forwarding aus Sicherheitsgründen ausgeschlossen. Für Informix haben wir das obige Vorgehen noch nicht getestet.
Die Servlet-Engine Tomcat verfügt zwar über einen kleinen "eingebauten" Webserver, doch für den Echtbetrieb sollte man aus Performance-Gründen einen der marktgängigen Webserver nutzen (z.B. Apache, IIS), der auch Verschlüsselung bietet. Für den Echtbetrieb empfehlen wird die Installation eines Apache 1.3.x auf Linux-Basis – meist ist dieser in der Linux-Distribution bereits integriert. Der Apache läßt sich sehr gut mit dem Tomcat verbinden (siehe Tomcat User's Guide im Kernmodul unter $SUPERX_DIR/doc/tomcat/doc ). Bei der Linux-Installation gehen wir davon aus, dass alle Maßnahmen unter der Kennung superx erfolgen, und dass der User superx Zugriffsrechte auf die Datenbank hat. Beim Kopieren des Archivs sollten Sie darauf achten, dass der User superx auf die Scriptdateien Ausführungsrechte besitzt.
Die folgenden Anleitungen gehen davon aus, dass Sie als Installationspfade für den Webserver C:\superx\webserver (unter win32) und /home/superx/webserver (unter UNIX / LINUX) gewählt haben. Sie können natürlich auch andere Pfade wählen, müssen dann aber die Pfade in dieser Dokumentation entsprechend umsetzen. Fehlende oder falsche Pfade bzw. Umgebungsvariablen sind in Java- und Datenbankprojekten eine wichtige Fehlerquelle (z.B. unter LINUX die Groß- / Kleinschreibung). Aus diesem Grunde haben wir ins Stammverzeichnis des webservers eine html-Datei erstellt ( $SUPERX_DIR/webserver/index.htm ), von der aus die Parameter und Pfade schrittweise überprüft werden können.
Der Webserver muss Java-fähig sein, damit er Servlets ausführen kann.
Arbeitsschritte:
1.
OpenJDK 1.8
installieren
2. Die Umgebungsvariable JAVA_HOME setzen und das bin-Verzeichnis der Java-Installation in den PATH legen. Die Umgebungsvariable CLASSPATH sollte mindestens "." enthalten, aber auf keinen Fall einen älteren XML-Parser (z.B. xerces 1.0).
3. Nur für Informix-Anwender: Laden Sie den jdbc-Treiber von Informix (oder das Informix Client SDK) herunter, installieren Sie das Produkt und kopieren Sie die Datei ifxjdbc.jar nach $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/lib .
4. Testen Sie die Datenbankverbindung mit dem Werkzeug propadmin .
5. Ablauf mit einem einfachen java-Servlet testen
Die Servlet-Engine ermöglicht dem Webserver das SuperX-Servlet auszuführen. Anders als andere Scriptsprachen (z.B. asp, PHP, Perl) für Webserver ist der Java-Code als Bytecode kompiliert; die Servlets werden normalerweise also nicht auf dem Webserver entwickelt und getestet, sondern auf einem eigenen Entwicklungsrechner.
Im Kernmodul ist der Tomcat 8 . 5 . 4 0 mitgeliefert. Tomcat ist von Oracle als Referenzimplementierung von Webapplikationen anerkannt, d.h. Sie sollten die Konfiguration mühelos auf andere Server übertragen können. Die Web-Applikation von SuperX läuft unter allen Tomcat-Versionen ab 8.*
Editieren Sie zunächst die Konfigurationsdatei $SUPERX_DIR/webserver/tomcat/conf/server.xml .
Hier werden die Ports und Anbindungen der Tomcat-Implementation angepasst. Standardmäßig läuft Tomcat auf dem Port 8080, und die Apache-Anbindung auf dem Port 8009. Weiterhin muss der Port 8005 für den Shutdown frei sein. Die Apache-Anbindung ist weiter unten dokumentiert.
Wichtig beim Betrieb des Tomcat mit UTF-8-Codierung: Der jew. Connector muss das weitere Attribut URIEncoding="UTF-8" aufführen. Wenn z.B. der Connector 8080 genutzt wird, sieht das so aus:
|
Einrichtung des Connectors |
<!-- Define a non-SSL HTTP/1.1 Connector on port 8080 --> |
Dies ist wichtig für den Ajax-Client.
Analog bei ISO Installationen:
URIEncoding="ISO-8859-1"
Nach einer Änderung müssen Sie Tomcat neu starten.
In der Datei
$SUPERX_DIR/webserver/tomcat/webapps/superx/META-INF/context.xml
befinden sich ein paar Attribute für die Webanwendung:
<Context reloadable="true" crossContext="true">
<Logger className="org.apache.catalina.logger.FileLogger"
prefix="localhost_superx_log." suffix=".txt"
timestamp="true"/>
<Manager pathname="" />
<Environment name="maxExemptions" type="java.lang.Integer"
value="15"/>
</Context>
Diese Datei wird im Kernmodul nicht ausgeliefert, es existiert aber einer Musterdatei context.xml.sam im gleichen Verzeichnis.
Die Datenbank-Verbindung für DBFORMS und Saiku wird in der Datei $SUPERX_DIR/webserver/tomcat/webapps/superx/ WEB-INF / dbforms-config .xml definiert. Am Ende steht:
<dbconnection conClass="org.apache.commons.dbcp.PoolingDriver"
name="jdbc:apache:commons:dbcp:default"
isJndi="false"
default="true"
defaultConnection="true" />
Damit wird der Connection Pool genutzt, der in der db.properties definiert ist. Nach einer Änderung muss man Tomcat neu starten.
In der Datei $TOMCAT_HOME/conf/web.xml sie u.a. die serverweite "Welcome-Page" bzw. deren Reihenfolge., welche wiederum Dateien anzeigen, wenn der Anwender ein Verzeichnis ohne Dateinamen aufruft, z.B. http://servername/superx/ :
|
Welcome-Files für Tomcat-Verzeichnisse |
<welcome-file-list> |
Wenn Sie z.B. die Reihenfolge so ändern, dass zuerst die Datei index.jsp angezeigt wird (sofern sie existiert), dann können Sie eigene "Homepages" definieren, die nicht von der SuperX-Distribution (z.B. bei Updates) überschrieben würden. Außerdem ist dies eine sinnvolle Sicherheitsmassnahme, weil so keine Directory Listings angezeigt werden.
Änderungen in der Datei web.xml in der Webanwendung ( <<Webanwendung>>/WEB-INF/web.xml ) überschreiben die Einträge in der serverweiten web.xml .
Weitere Konfigurationsmöglichkeiten (Server Side Includes etc). sind in dieser Datei dokumentiert.
Vergleiche auch den unten folgenden Abschnitt zur Einrichtung der SuperX-Servlets unter Tomcat.
In der Tomcat Auslieferung gibt es Beispiel-Webanwendungen, bitte löschen Sie diese.
Die Datei $WEBAPP/WEB-INF/web.xml enthält die Konfiguration der Webanwendung, z.B. maximale Zeilenanzahl bei Berichten. Diese Datei wird initial ausgeliefert, bei Upgrades des Kernmoduls aber nicht automatisch überschrieben. Im Zweifelsfall stellen Sie die Auslieferungsdatei wieder her, es Muster dafür befindet sich in der Datei $WEBAPP/WEB-INF/web.xml. superxonly .
Eine Änderung in der web.xml macht einen Tomcat Neustart erforderlich. Achten Sie auf die wolhgeformte XML Notation, wenn die Datei nicht wohlgeformt ist, startet der Server gar nicht mehr. Nutzen sie daher am Besten einen XML-fähigen Editor.
Ab Kernmodul 4.9 benötigen Sie in der Datei am Ende vor dem ersten "<servlet-mapping>" Eintrag folgende Konfiguration:
<!--REST -->
<servlet>
<servlet-name>Jersey REST Service</servlet-name>
<servlet-class>
com.sun.jersey.spi.container.servlet.ServletContainer
</servlet-class>
<init-param>
<param-name>com.sun.jersey.config.property.packages</param-name>
<param-value>de.superx.sxrest</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>Jersey REST Service</servlet-name>
<url-pattern>/sxrest/*</url-pattern>
</servlet-mapping>
<!--Ende REST -->
<servlet-mapping>
<servlet-name>spring</servlet-name>
<url-pattern>/oauth/*</url-pattern>
</servlet-mapping>
Im Zweifelsfall
Für SuperX-Standalone-Betrieb (also unabhängig von HisInOne) ist ab Kernmodul 5.0 der context-Parameter zentral
<web-app xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd" version="2.4">
<display-name>SuperX</display-name>
<absolute-ordering />
<description>SuperX</description>
<context-param>
<param-name>superxStandalone</param-name>
<param-value>true</param-value>
</context-param>
Anpassen der Datei db.properties mit den Datenbank-Zugangsdaten (siehe Anpassen der Datenbankparameter für das SuperX-Servlet ) ist Voraussetzungen dafür, dass der Applikationsserver auf die Datenbank zugreifen kann.
In der web.xml werden im SuperXManager Servlet einige wichtige Konfigurationen vorgenommen:
|
Zentrales Servlet ist der SuperXManager, für den ein Eintrag benötigt wird.
|
<servlet> <servlet-name> SuperXManager </servlet-name> <servlet-class> de.superx.servlet.SuperXManager </servlet-class>
|
|
XSL-Prozessor |
<!—-Bei Bedarf kann Saxon-als XSL-Prozessor definiert werden, wenn der folgende Eintrag aktiviert wird--> <!--<init-param> <param-name>xsl_processor</param-name> <param-value> net.sf.saxon.TransformerFactoryImpl </param-value>
oder
<param-value>org.apache.xalan.processor.TransformerFactoryImpl</param-value> </init-param> -->
|
|
Max. Zeilenanzahl |
<!—Die maximale Anzahl von Datensätzen, die eine Abfrage zurückliefern sollte, sollte jetzt beim SuperX-Manager angegeben werden, nicht mehr beim SuperXDBServlet, im Normalfall reicht der Standardwert von 20000 der ohne init-param als default genommen wird <init-param> <param-name>maxRows</param-name> <param-value>20000</param-value> </init-param>
|
|
<!—-neu in 3.5rc2 – Erläuterung s.u.--> <init-param> <param-name> field1Cache </param-name> <param-value>tid>10000</param-value> </init-param>
|
|
|
<init-param> <!-- soll die Funktion sessionbasierter Felderdefaults deaktiviert werden-->
|
|
|
Sessionbasierte Felddefaults (Vorbelegung gleichnamiger Felder in unterschiedlichen Selektionsmasken) |
<init-param>
<load-on-startup>50</load-on-startup> </servlet> |
Default für Response Compression ist true, dann braucht der init-param auch nicht angegeben zu werden. Die RTWH Aachen nutzt allerdings einen ReverseProxy der mit der gzip-Kompression nicht klar kam, in diesem Fall kann man durch setzen des ResponseCompression -Initparams mit param-value=false die Kompression ausschalten.
Neu in SuperX3.5rc2 ist die Möglichkeit einen sogenannten field1Cache für Auswahllisten (Feldart 1) zu nutzen.
Wenn ein entsprechender init-param beim SuperXManager definiert ist, lädt sich der webserver beim Start Inhalte für die angegeben Felder der Feldart 1 (aus felderinfo), in denen es keine dynamischen Tags gibt (wie z.B. <<Haushaltsjahr>>) in einen Cache. Dadurch wird der Start des Webservers natürlich etwas langsamer, aber wenn die Benutzer einzelne Maske aufrufen, können diese schneller dargestellt werden, weil weniger Datenbankzugriffe nötig sind.
Als Param-value muss eine where-Bedingung für einen select auf die Tabelle felderinfo angegeben werden. Sie können das Beispiel tid>10000 belassen oder bei Bedarf bestimmte Felder auslassen, z.B.
tid>10000 and name not in ('Haushaltsjahr','Semester').
Der Cache wird aktualisiert, wenn im SuperXManager-Servlet auf den Button “Server-Cache aktualisieren” geklickt wird oder der Webserver neu gestartet wird. Außerdem wird er jeden Morgen einmal automatisch aktualisiert. Felder die sich zusätzlich zu den nächtlichen Updates dynamisch ändern, sollten ausgeschlossen werden, damit sie immer aktuell aus der Datenbank geholt werden.
Ein weiterer Parameter für die gesamte Webapplikation, der aber nur im XML-Frontend ausgewertet wird, lautet <session-timeout> (siehe Beispiel-web.xml in unserem Kernmodul, ganz am Ende der webapp-Deklaration). Dieser Wert beschreibt die "Lebenszeit" einer Anmeldung bei Inaktivität des Benutzers (in Minuten). Ein negativer Wert bedeutet, dass die Session nie beendet wird. Ein sinnvoller Wert ist z.B. 180 (3 Stunden). Je länger die Zeit, desto höher die Belastung des Servers.
Ab Kernmodul 4.7 / HISinOne-BI 2017.12: Der CSV Export von Masken wird standardmäßig in der gleichen Kodierung vollzogen wie die des Servers. Sie können eine abweichende Codierung eingeben, wenn Sie z.B. den Server unter UTF-8 betreiben, aber den CSV Export für die Anwender/innen in ISO ausführen wollen, weil die meisten Anwender/innen unter Windows mit Excel arbeiten. In diesem Falle setzen Sie für das Servlet SuperXManager den init-param "CSV-Encoding" auf den Wert ISO-8859-1:
<servlet>
<servlet-name>SuperXManager</servlet-name>
<servlet-class>de.superx.servlet.SuperXManager</servlet-class>
...
<init-param>
<param-name>CSV-Encoding</param-name>
<param-value> ISO-8859-1 </param-value>
</init-param>
</servlet>
Nach einer Änderung müssen Sie Tomcat neu starten.
Sie können auch durch spezielle Fehlerseiten die normale Fehlerausgabe des SuperX-Servlets sperren.
|
Fügen Sie an das Ende der web.xml vor dem End-Tag "</web-app>" z.B. folgende Elemente ein |
...
|
Die ist die Voreinstellung bei Neuinstallation von SuperX, ältere Installationen müssen dies ggf. nachholen.
Sie können auf verschiedene Fehler-Codes sowie Exception-Types eigene Fehlerseiten definieren. Details dazu finden Sie in der Dokumentation Ihres Applikationsservers.
Vor dem Start müssen die Umgebungsvariablen der Datei $SUPERX_DIR/db/bin/SQL_ENV geladen werden.
Die Umgebungsvariable JAVA_HOME muss korrekt gesetzt sein
•
Unter WIN32:
Das geht unter MS-DOS als Kommandozeile
set JAVA_HOME=c:\jdk1.6x
oder man macht einen Eintrag als Systemvariable (Systemsteuerung – System – Erweitert – Umgebungsvariablen) neue Systemvariable JAVA_HOME , Wert c:\jdk1.6x
(wenn nur die Runtime installiert ist, ist das Verzeichnis evtl. c:\programme\javasoft\jre\1.6x)
• <tomcat-Basisverzeichnis>\bin\startup.bat ausführen (zum Beenden shutdown.bat)
• Falls unter Windows 98/ME eine Meldung kommt, dass der Umgebungsspeicher nicht ausreicht, muss man über start->Ausführen folgende Zeile eingeben: command.com /p /e:4096
•
Unter UNIX / LINUX:
Setzen Sie entweder in der /etc/profile oder in der Datei
.profile
bzw. .bashrc im Heimverzeichnis des Users
superx
bzw. bei Betrieb von Datebank und Webserver auf einem Rechner in der Datei
$SUPERX_DIR/db/bin/SQL_ENV
die Zeile ein:
export JAVA_HOME=/usr/lib/java
(als Beispiel für eine Java-Installation unter SUSE Linux 9.1)
• Das aktuelle Verzeichnis sollte im PATH sein (ggfs. /etc/profile oder .profile bzw .bashrc PATH=PATH$:.;export PATH
• Melden Sie sich ab und wieder an
• <tomcat-Basisverzeichnis>\bin\startup.sh ausführen (zum Beenden shutdown.sh ).
Das Terminal-Fenster zeigt den Port an, auf dem Tomcat läuft, z.B. 8080; um die Engine zu testen, kann man einen Webbrowser (zur Not auch lynx ) starten und die Seite http://localhost:8080/ ... aufrufen.
Testen, ob der SuperX-Kontext unter Tomcat verfügbar ist:
http://localhost:8080/superx/
Testen, ob Sie sich auf der SuperX-Datenbank anmelden können
http://localhost:8080/superx/xml/
Testen, ob das Applet läuft
http://localhost:8080/superx/applet/
Beendet wird Tomcat mit dem Befehl: shutdown.bat für MS-DOS bzw. shutdown.sh für UNIX.
•
Wenn Sie die SuperX-Webapplikation auf einem vorhandenen Tomcat installieren wollen, folgen Sie dem Leitfaden auf der Seite
http://www.superx-projekt.de/doku/kern_modul/tomcat/f_TomcatausLinuxDistributionen.htm
Um eine weitere Tomcat-Instanz starten zu können (z.B. für ein Testsystem) müssen folgende Schritte getan werden:
1. mkdir /var/lib/tomcat8-test
2. cd /var/lib/tomcat8-test
3. mkdir conf temp webapps work logs
4. cd ..
5. chown -R tomcat8:tomcat8 tomcat8-test
6. ln- s /var/lib/tomcat8/conf/catalina.properties /var/lib/tomcat8-test/conf
7. ln- s /var/lib/tomcat8/conf/web.xml /var/lib/tomcat8-test/conf
8. ln- s /var/lib/tomcat8/conf/policy.d/ /var/lib/tomcat8-test/conf
9. cp /var/lib/tomcat8/conf/server.xml /var/lib/tomcat8-test/conf/
10. In der /var/lib/tomcat8-test/conf/server.xml alle Ports ändern. Diese dürfen nicht gleich sein.
11. cd /etc/init.d/
12. cp tomcat8 tomcat8-test
13. vi tomvat8-test
14. Ändern nach: # Provides: tomcat8-test
15. Ändern nach: NAME=tomcat8-test
16. Ändern nach: DESC="Tomcat servlet engine SuperX"
17. Ändern nach: CATALINA_HOME=/usr/share/tomcat8
18. Abspeichern mit wq
19. systemctl daemon-reload
20. Nun kann die neue Tomcat Instanz verwendet werden.
Mit dem Webanwendung- Manager kann man verschiedene Einstellungen und Protokolle aufrufen vornehmen.
Es kann bei Administrationsrechten aufgerufen werden im Menü Standardberichte:
oder direkt unter der Adresse:
http://rechnername:port/superx/edit/kern/webapp_manager.jsp
Hier ein Screenshot vom Kernmodul 4.9:
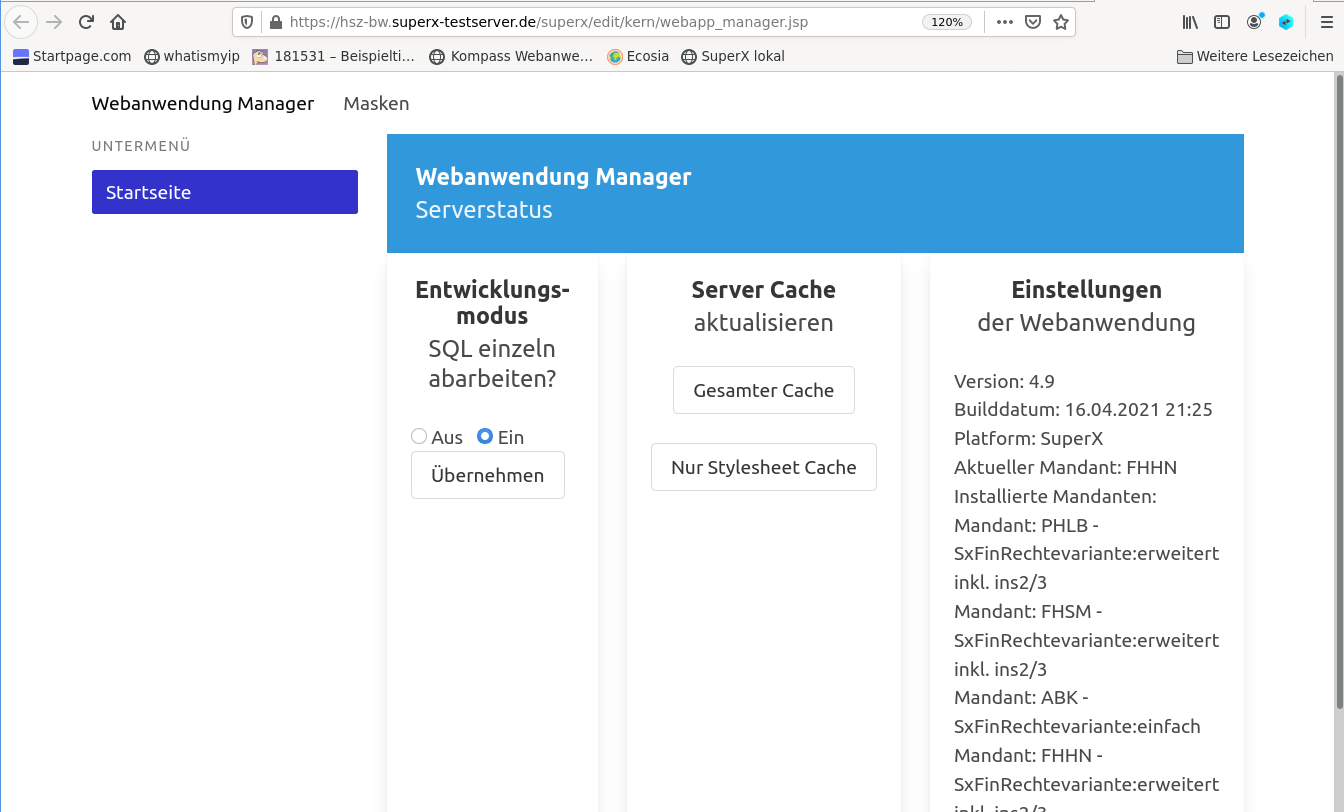
SuperX cacht zur Performanceverbesserung einige Dinge im Webserver, dazu gehören Erläuterungen und Übersetzungen und für's XML-Frontend auch: User, Userrechte und Sichten und auch Abfragen wenn in der db.properties eingetragen.
Falls Sie bei Entwicklungsarbeiten Änderungen an diesen Dingen gemacht haben und im XML-Frontend arbeiten, müssen Sie einmal den "Server-Cache aktualisieren".
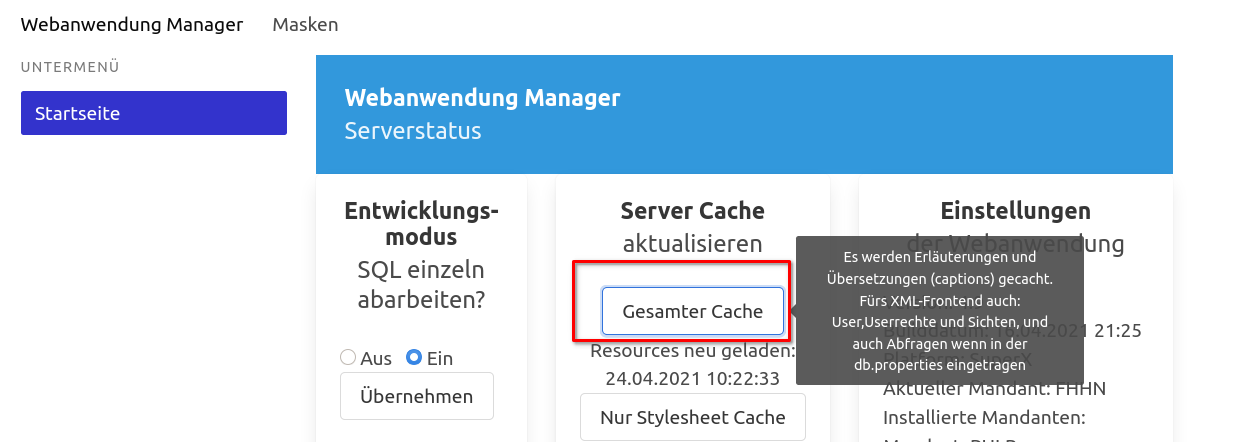
Hinweis: Neue Sichten können z.B. auch durch ein Update der KLR -Daten erfolgen, wenn neue alternative Hierarchien dazukommen.
Im Webanwendung Manager werden verschiedene SQL/XML-Loginformationen für Support- oder Entwicklungszwecke angezeigt. Dies befindet sich im Menü "Masken":
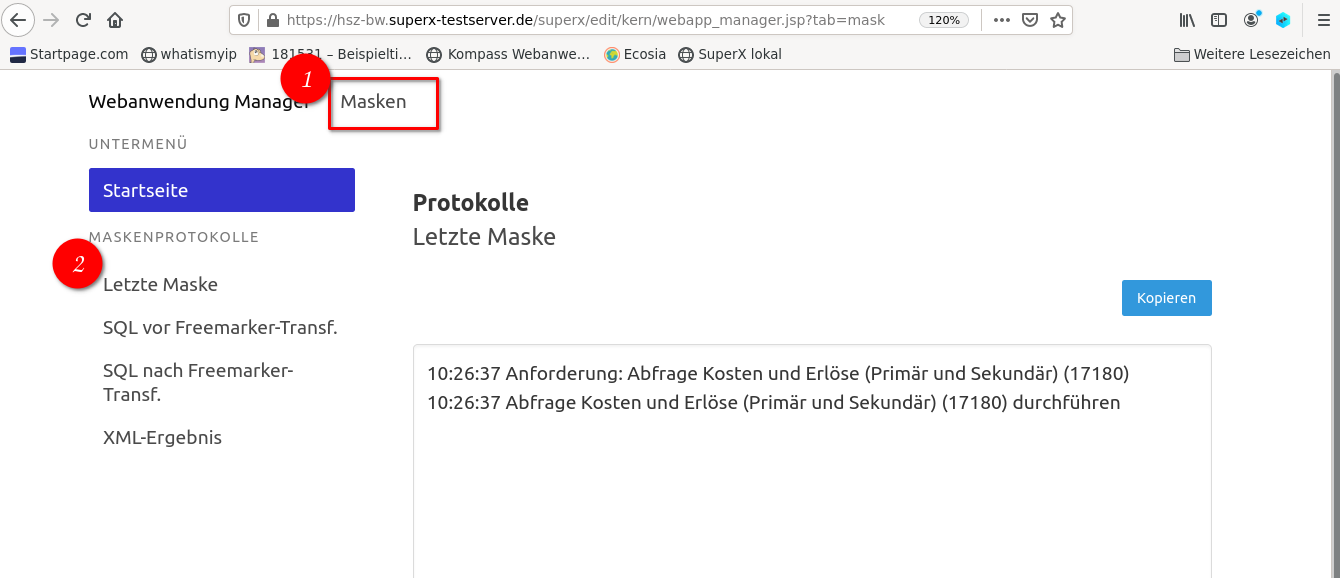
Sie können jeweils den Aufruf der letzten Maske anschauen, oder den SQL-Quellcode der Maske. Wenn die Maske Freemarker nutzt, können Sie zwischen dem Quellcode vor..
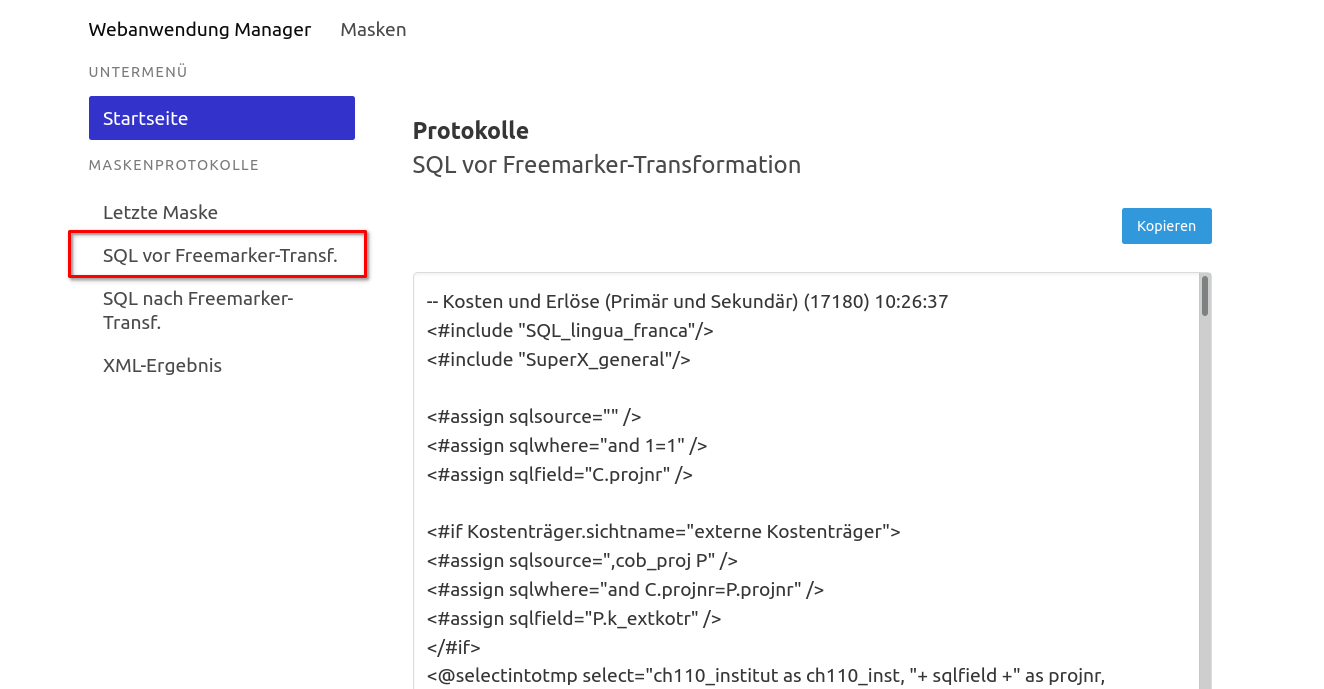
...und nach der Freemarker Transformation wählen:
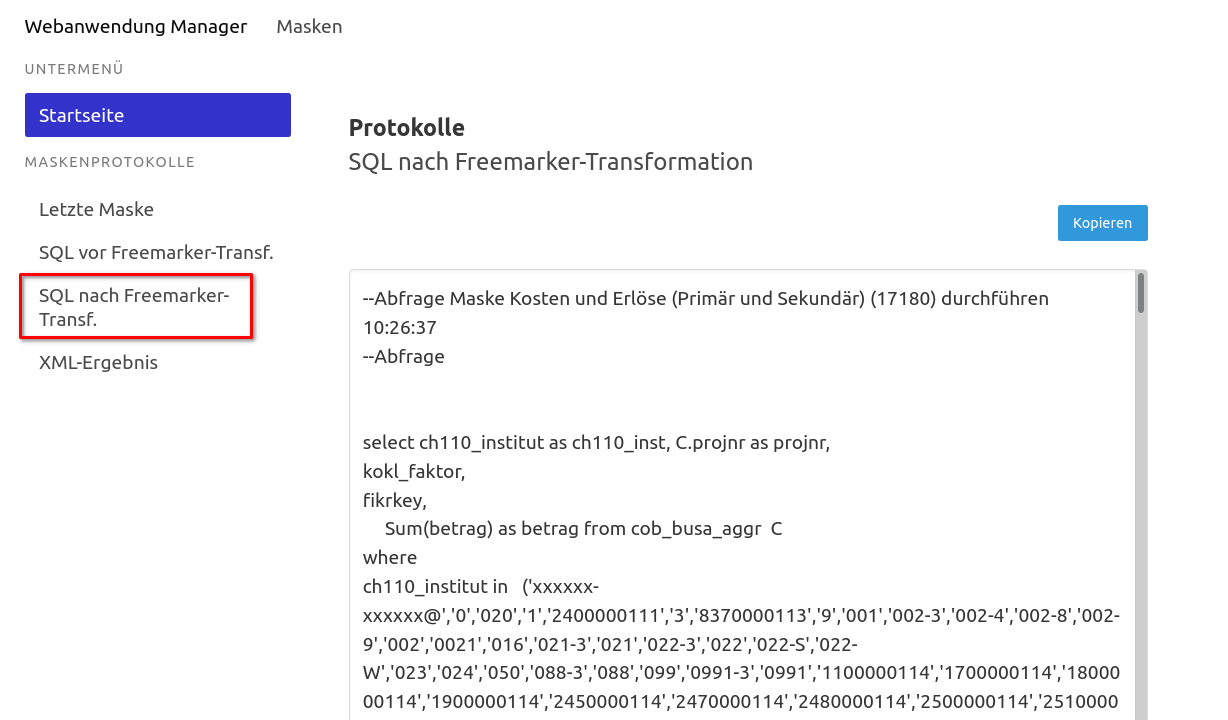
Außerdem können Sie das XML-Ergebnis der Maske aufrufen, hier allerdings nur max. 30 Zeilen.
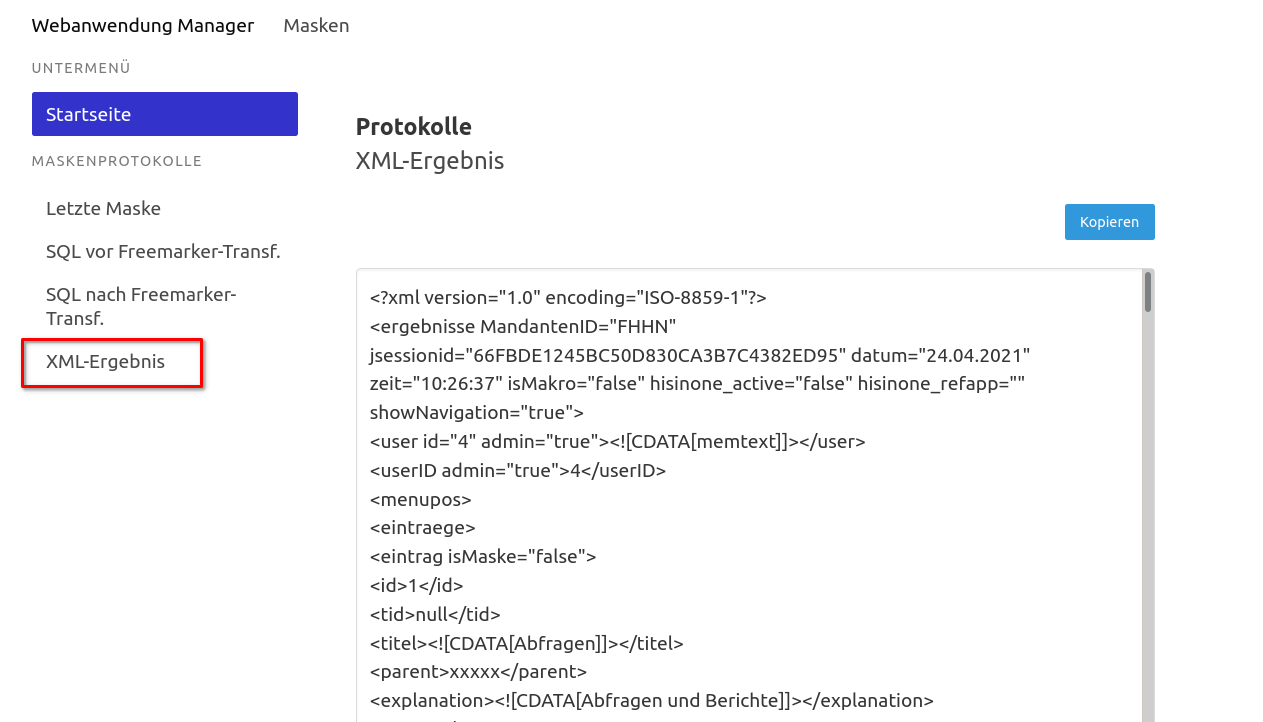
Den XML können Sie lokal speichern und z.B. mit JasperReports weiterverarbeiten, siehe unser JR-Handbuch .
Die Tomcat-Performance läßt sich durch Zuweisung von mehr RAM steigern. Dazu muss lediglich die Umgebungsvariable
JAVA_OPTS
gesetzt werden, z.B. mit
JAVA_OPTS= "-Xmx300M -Djava.awt.headless=true"
export JAVA_OPTS
Hierdurch werden 300 MB RAM dem Tomcat zugewiesen. Die Umgebungsvariable wird außerdem auch von diversen SuperX-jdbc-Clients berücksichtigt. Dies ist z.B. sinnvoll, wenn größere Tabellen be- oder entladen werden. Der Passus " -Djava.awt.headless=true" muss immer dabei sein, wenn Tomcat auf einem UNIX-System ohne graphische Konsole aus aufgerufen wird.
Die Performance von Tomcat läßt sich weiterhin durch den Lastausgleich in Kombination mit dem Apache Webserver steigern. Beim Tomcat 3.2.x Die Konfiguration wird in der Datei conf/workers.properties vorgenommen.
Die bereits vorhandenen Beispieleinträge sollten die Konfiguration des Lastausgleich erläutern. Weitere Details zur workers.properties finden Sie in der Anleitung zur Anbindung an den Apache . Die verschiedenen Howtos in der Tomcat-Distribution erläutern Details zur Apache-Anbindung.
Wenn Tomcat mit einer SSL-Verschlüsselung arbeiten soll, dann sollte von vornherein das JDK 1.4.x oder höher installiert werden, weil dies die notwendigen Bibliotheken dazu enthält. Es gibt ferner die Möglichkeit, die Verschlüsselung vom Webserver (Apache oder IIS) vornehmen zu lassen (siehe unten oder Tomcat-Dokumentation in tomcat-docs/tomcat-ssl-howto.htm). Im folgenden eine Anleitung, wenn kein öffentlich bekanntes und signiertes Zertifikat genutzt werden soll. Große Teile wurden übernommen aus der Tomcat Dokumentation "ssl-howto.html".
Erzeugen Sie zunächst auf dem Applikationsserver einen Keystore mit dem Befehl
|
Windows: |
%JAVA_HOME%\bin\keytool -genkey -alias tomcat -keyalg RSA |
|
UNIX: |
$JAVA_HOME/bin/keytool -genkey -alias tomcat -keyalg RSA |
Die Parameter werden erfragt; wichtig ist, dass der erste Eintrag (Vor- und Nachname, COMMON NAME CN) der DNS-Name des Werbservers ist, z.B. superx.verwaltung.uni-duisburg.de . Als Passwort geben Sie beide Male z.B. "changeit" an (das ist nur ein Beispielpasswort für die Dokumentation, natürlich sollten Sie das Passwort ändern). Daraufhin wird ein Zertifikat erzeugt und in der Datei .keystore im Homeverzeichnis des Benutzers angelegt (unter Windows im Profiles-Verzeichnis, unter UNIX im home-Verzeichnis).
Das persönliche Zertifikat können Sie durch einen kommerziellen Zertifizierungsserver publizieren; zu Testzwecken können Sie auch ein selbsterstelltes Zertifikat erzeugen:
keytool -selfcert -alias tomcat -validity <<Anzahl der Tage>>
Danach ändern Sie die Datei $TOMCAT_HOME/conf/server.xml , indem Sie die Passage mit der SSL-Verschlüsselung (z.B. 8443) ent-kommentieren und den normalen Port (8080) auskommentieren.
<Connector port="8443" protocol="HTTP/1.1" SSLEnabled="true"
maxThreads="150" scheme="https" secure="true"
clientAuth="false" sslProtocol="TLS"
keystorePass="changeit" keystoreFile="/home/superx/.keystore"
/>
Danach ist die Webanwendung über https://localhost:8443 statt http://localhost:8080 erreichbar. Sie müssen alle Links entsprechend ändern und, wenn Sie auch das Applet nutzen, in der Datei superx.properties die Zeile
|
superx.properties mit ssl |
SxServerURL=https://localhost:8443/superx/servlet/SuperXDBServlet statt SxServerURL=http://localhost:8080/superx/servlet/SuperXDBServlet aktivieren. |
Das Zertifikat können Sie löschen, indem Sie auf der Kommandozeile eingeben:
keytool -delete -alias tomcat
1.
public key + private key erzeugen und die im keystore-file ablegen
(der private key wird dabei mit passwd verschlüsselt):
keytool -genkey -keyalg RSA -alias tomcat -keystore xxx.jks
2.
certificate request generieren --> Datei server.csr und an die CA schicken:
keytool -certreq -keyalg RSA -file server.csr -keystore xxx.jks
3.
Den von der CA signierten public key = Serverzertifikat
zurückbekommen --> Datei
server.cer
4.
Zuerst das Zertifikat der CA (z.B. UTN-USERFirst-Network Applications, http://www.usertrust.com) downloaden und in den keystore einspielen:
keytool -import -file UTN.cer -alias tomcat -keystore xxx.jks
5.
Dann das neue Serverzertifikat in den keystore einspielen:
keytool -import -file server.cer -alias tomcat -keystore xxx.jks
6.
in der Tomcat-server.xml auf die keystore-Datei verweisen:
keystoreFile="<<Pfad zur xxx.jks-Datei>>" keystorePass="passwd"
Wichtig: dasselbe passwd einsetzen wie unter 1. zum Verschlüsseln
des private key benutzt wurde
7. Restart Tomcat
8. https-Verbindung zum Server, Zertifikat überprüfen - vertrauenswürdig?
Zur Erhöhung der Sicherheit im SuperX-Applet ist es möglich, eine DSA-public/private-Key-Kontrolle zu installieren. Dabei wird jeder SQL-Befehl, der vom Applet ans Servlet geschickt wird, mit dem einen Key signiert und im Servlet wird mit Hilfe des anderen, nur dort bekannten Keys kontrolliert, ob der ankommende SQL eine gültige Signatur aufweist.
Zur Installation eines zufällig erzeugten Key-Paars brauchen Sie auf dem Datenbankserver in der Shell nur die
SQL_ENV
aufzurufen und anschließend das Kommando
sx_keymanager.x install
abzuschicken. Mit
sx_keymanager.x delete
könnten Sie ggfs. das Schlüsselpaar wieder entfernen und mit
sx_keymanager.x check
prüfen, ob ein Schlüsselpaar installiert ist. Wenn Sie Tomcat auf einem separaten Rechner betreiben, brauchen Sie hier kein Script ausführen, es recht, dort das jeweilige Kernmodul-Paket zu entpacken. Bei mandantenfähigen Installationen müssen Sie das Script
sx_keymanager.x install
für jeden Mandanten einzeln ausführen.
Wenn Sie Tomcat neu starten, können Sie in den Logdateien (normalerweise $SUPERX_DIR/webserver/tomcat/logs/catalina.out ) kontrollieren, ob die public/private key Kontrolle aktiv ist oder nicht.
Nach der Meldung zum Aufbau des Datenbank-Connectionpools kommt ein einsprechender Hinweis.
Aufbau des ConnectionPool (....) .. OK
public/private key aktiv
Im SuperX-Applet können Sie den Info-Button anklicken, in der erscheinenden Infobox wird angegeben, ob public/private key Kontrolle aktiv ist oder nicht.
Die Implementation von Tomcat als Dienst ist unverzichtbar, damit der Serve rbeim Hochfahren automatisch startet. Wir haben Konfigurationsscripte und Startscripte mitgeliefert, die Sie recht leicht anpassen können.
Im Verzeichnis $SUPERX_DIR/webserver/etc befinden sich Musterdateien, um einen Dienst unter SUSE oder RedHat Linux daraus zu machen. Kopieren Sie die Inhalte des Verzeichnisses etc als root auf den Webserver ins Verzeichnis /etc , und passen Sie /etc/sysconfig/superx_webserver entsprechend Ihrer Umgebung an. Schließlich muss ein symbolischer Link von /etc/init.d/superx_webserver nach (usr)/bin/rcsuperx _webserver gelegt werden.:
ln -symbolic /etc/init.d/superx_webserver /bin/rcsuperx_webserver
Danach kann man den Dienst im Runlevel-Editor des YAST aktivieren (Runlevel 3 und 5). Der Dienst muss vor dem Webserver, aber nach dem Start des Datenbankservers gestartet werden. Der Dienst selbst wird vom User superx gestartet, und kann jederzeit mit
rcsuperx_webserver restart
neu gestartet werden.
Unter RedHat Linux gibt es ebenfalls Werkzeuge für die Einrichtung der Runlevel, ggf. kann man auch manuell symbolische Links einrichten, wie beim Start des Datenbankservers beschrieben . Außerdem muss ggf. die Umgebung vor dem Start des Tomcat geladen werden, z.B. durch Aufruf der SQL_ENV. Wichtig ist, dass beim Start des Tomcat als Dienst die Variable JAVA_HOME korrekt gesetzt ist und die Variable LANG auf eine deutsche Locale zeigt. Letzteres ist bei RedHat nicht standardmäßig vorgesehen.
Die Einrichtung des Tomcat als Dienst ist auch für Windows-Server möglich, wie im folgenden gezeigt wird.
Tomcat muss auf Windown-NT/2000-Rechnern nicht in einer DOS-Box laufen, sondern kann auch als Dienst laufen. Die Installer von Tomcat 7 sehen unter Windows NT /2000/XP eine Installation als Dienst vor.
Unter NT 4 läuft der Tomcat-Dienst nur mit dem JDK 1.6.x, unter Win2000 sollte man Java JDK 1.6.x oder höher installieren. Die Variable JAVA_HOME zeigt dann auf dieses Verzeichnis. Für die Einrichtung muss man bei Windows folgendes machen:
• In der Datei d:\superx\webserver\tomcat\conf\wrapper.properties öffnen und Tomcat_home und Java_Home auf den richtigen Pfad setzen
• Man fügt der Computerverwaltung Tomcat als Dienst hinzu, indem man in einer DosBox vom <tomcat>/bin -Verzeichnis aus " jk_nt_service –I tomcat ..\conf\wrapper.properties " ausführt.
• Dann kann man den Dienst über die Systemsteuerung -> Dienste starten (besser: auf automatisch setzen), und theoretisch läuft Tomcat auch dann, wenn kein User auf dem Rechner angemeldet ist. Aus der DOS-Box kann man den Dienst auch mit net start tomcat starten.
• Die Deinstallation des Dienstes erfolgt über jk_nt_service –R tomcat
Der Dienst wird in der Systemsteuerung des Rechners aufgeführt, und das Ergebnis sieht unter Win2000 wie folgt aus:
|
Rechts sehen Sie die Eigenschaften des tomcat-Dienstes unter NT-Server. Bei dem Starttyp können Sie automatisch wählen, und die weiteren Registerkarten sind nicht gefüllt. Der Dienst lässt sich mit den Start/ Unterbrechungsbuttons manuell neu starten:
|
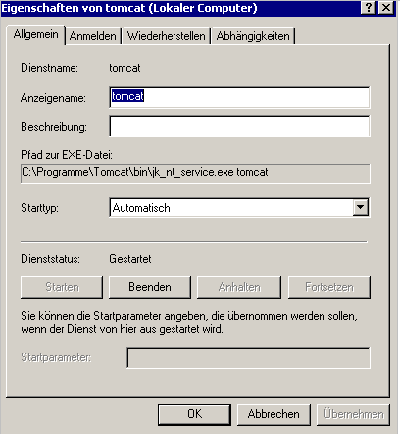
|
Das SuperX-Applet greift u.a. auf eine Datei superx.properties zu , um zu erfahren, mit welchem Datenbanksystem gearbeitet wird (Informix/Postgres).
Für diese Datei gibt es im Kernmodul ein Muster
$SUPERX_DIR/webserver/tomcat/webapps/superx/applet/superx.properties.sam
das Sie nach superx.properties kopieren und wie folgt anpassen:
Die Adresse des Servlets wird normalerweise automatisch ermittelt, bei Netzwerkproblemen kann sie jedoch auch fest angegeben werden, dazu # vor SxServerURL entfernen und localhost ggfs. durch IP-Nummer/Rechnername ersetzen.
In der SuperX-Properties wird außerdem das Datenbanksystem (Variable SxDB ) festgelegt, sowie das Logging (Variable logToKonsole ). Bei der Installation von SuperX sollten Sie das Logging auf "all" setzen, im Echtbetrieb sollten Sie das Logging wie beim Servlet auf "none" setzen.
|
Ein Beispiel |
# # Die Adresse des Servlets wird normalerweise automatisch ermittelt, # bei Problemen kann sie hier fest angegeben werden, dazu # vor SxServerURL entfernen und localhost ggfs. durch IP-Nummer/Rechnername ersetzen #SxServerURL=http://IP:8080/superx/servlet/SuperXDBServlet # Der Logging-Level logToKonsole kann eingeschaltet werden: "none","errors"=fehler,"all"=alles) logToKonsole=errors #Wird im Applet in Titelleiste angezeigt SxTitle=Testhochschule #Das verwendete DB-System, möglich sind "Informix" und "Postgres" SxDB=Postgres # HTML-Format Parameterleiste, Feldname in BOLD SxParamStart=<html><body BGCOLOR=\"#ffffff\"><font face=arial,helvetica size=-2> SxParamEnd=</font></body></html> SxParamBoldOn=<b> SxParamBoldOff=</b> |
Wenn der Webserver mehrere Mandanten in unterschiedlichen Datenbank bedient, muss es für jeden Mandanten eine superx.properties geben, die den zusätzlichen Parameter MandantenID enthält, z.B.
MandantenID=7200 (vergl. entsprechendes Kapitel).
Schließlich muss man noch darauf achten, dass ggfs. der Tomcat-Port in der Firewall (standardmäßig Port 8080, evtl. noch 8007 und 8443) freigegeben ist.
Die Homepage von SuperX liegt standardmäßig unter
http://<IP-Nummer des Servers>:8080/superx/
Das XML-Frontend generiert aus XML-Datenströmen die Oberfläche im html-Format. So lässt sich die Oberfläche von SuperX beliebig mit XSLT anpassen, Details dazu finden Sie im SuperX-Entwicklerhandbuch.
|
Vorbemerkung |
Achtung: eine Änderung dieser Parameter ist nur in SuperX-Releases möglich. Wenn Sie SuperX als Teil von Edustore in HISinOne nutzen, sind die im Folgenden beschriebenen Maßnahmen nich tmöglich bzw. führen zu unvorhersehbaren Ergebnissen. |
Das XML-Frontend mit DHTML-Techniken erlaubt es, wahlweise den Themenbaum als Javascript-"Baum" anzuzeigen (SuperX Kernmodul ab Version 3.0rc7-3.5rc2) oder als normales html-Menü (SuperX Kernmodul bis Version 3.0rc6 oder ab Version 4.0). Wenn der Javascript-Baum nicht genutzt werden soll, kann dieser wie folgt ein/ausgeschaltet werden:
|
Abschaltung des |
Editieren Sie die Datei
$SUPERX_DIR/webserver/tomcat/webapps/superx/xml/pageComponents_html_final.xsl
|
Nach einem Tomcat-Neustart wird das html-Menü angezeigt.
Analog können Sie das Javascript-Menü einschalten:
|
Aktivierung des 
|
Editieren Sie die Datei
$SUPERX_DIR/webserver/tomcat/webapps/superx/xml/pageComponents_html_final.xsl
|
|
Aktivierung der Links zu den Masken im
|
Wenn Sie darüber hinaus auch wollen, dass nicht nur die Themen, sondern auch die Masken im linken Menü angezeigt werden, setzen Sie eine weitere Variable auf "true":
Damit erscheinen Links auch die Masken. |
Viele Hochschulen, die SuperX mit LDAP-Anmeldung nutzen oder anderweitig konfigurieren, wollen weitere Steuerungmöglichkeiten über das Aussehen des Menüframes nutzen. Sie können auch steuern, wie der Fuss des linken Navigationsframes aussehen soll; standardmäßig werden folgende Links angezeigt:
|
Hyperlinks unter dem Themenbaum |
|
Editieren Sie Ihre Datei " pageComponents_html_final.xsl ":
Fügen Sie die folgenden Einträge in pageComponents_html_final.xsl vor dem Tag am Ende </xsl:stylesheet> ein:
|
Ausblenden des Passwort-Ändern-Links: |
<xsl:template name="showPasswordChangeLink" > |
|
Ausblenden des Login/Logout-Links: |
<xsl:template name="showLogoutLink" > <xsl:text>false</xsl:text> </xsl:template> |
|
Ausblenden des Applet-Links: |
<xsl:template name="showAppletLink"> |
|
Ausblenden des Reset-Buttons : |
<xsl:template name="showResetLink" > <xsl:text>false</xsl:text></xsl:template> |
Sie können unter diesem Bereich noch weitere HTML-Elemente einbauen. Dafür gibt es ein in der Auslieferung von SuperX befindliches leeres Template menue_fuss :
|
Einblenden weiterer Links oder Texte: |
<xsl:template name="menue_fuss"> |
Sie können auch weitere Templates bearbeiten und Manipulieren, indem sie ein Template aus einer vorhandenen XSL Datei kopieren und in die pageComponents_html_final.xsl kopieren. Dadurch wird Ihr template bevorzugt. Sie können dann den Inhalt erweitern, kürzen oder ändern. Wenn Sie z.B. den Breadcrumb ausblenden möchten kopieren Sie einfach das template des Breadcrumbs und leeren die Ausgabe:
|
Breadcrumb ausblenden: |
<xsl:template name="breadcrumbs_superx"> <xsl:param name="jsessionid"/> </xsl:template> |
Dies können Sie in pageComponents_html_final.xsl mit beliebigen Elementen füllen.
Wenn die Servlet-Engine mehrere SuperX-Mandanten in unterschiedlichen Datenbanken bedienen soll, muss es unter $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB_INF eine Datei mandanten.cfg geben.
Darin müssen die MandantenIDs (typischerweise Hochschulnummern) der einzelnen Mandanten aufgeführt sein. (Jeweils eine ID pro Zeile). Zusätzlich muss es dann nicht eine db.properties geben, sondern für jeden Mandanten eine nach dem Schema db_XXXX.properties, wobei XXXX für die MandantenID steht.
propadmin.x ./db_XXXX.properties.
Nach dem Start von Tomcat können Sie in den Logdateien (meist catalina.out oder localhost.log) kontrollieren, ob für jeden Mandanten ein Datenbank-ConnectionPool aufgebaut wurde.
Unter $SUPERX_DIR/webserver/tomcat/webapps/superx sollte es für jeden Mandanten ein Unterverzeichnis mit dem Namen der MandantenID geben.
z.B.
$SUPERX_DIR/webserver/tomcat/webapps/superx/7200
$SUPERX_DIR/webserver/tomcat/webapps/superx/7300
$SUPERX_DIR/webserver/tomcat/webapps/superx/7400
In jedes der Mandantenunterverzeichnisse muss eine Datei index.htm reinkopiert werden, die die Mandantid übergibt. Der Inhalt z.B.
<html lang="de" xml:lang="de"><head>
<META http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<meta http-equiv="refresh" content="0; URL=../index.jsp?MandantenID=7200" />
<LINK href="/kompass/style/superx.css" type="text/css" REL="stylesheet" />
</head>
<body>
<p align="center">Diese Seite ist umgezogen. Wenn Sie nicht automatisch weitergeleitet werden, klicken Sie <a href="../index.jsp?MandantenID=7200">hier</a></p>
</body>
</html>
Die einzelnen Mandanten können SuperX dann mit der Url
http://rechnername:8080/superx/MANDANTENID
aufrufen, z.B.
http://www.plgr-bw.de:8080/superx/7200
In der web.xml sollte bei einem Mandantensystem bei SuperXmlAbmeldung der init-param mit alt_redirect_url gelöscht werden.Ansonsten wird der MandantenPfad nicht beachtet. Der Pfad weist dann relativ zum Verzeichnis ohne Mandantenbetrieb.
Wenn bestimmte Mandanten das Upload-Servlet zum Hochladen von Dateien per Browser nutzen sollen, muss die web.xml angepasst werden, siehe dazu im Abschnitt zu Upload-Funktion den Punkt Anpassung der web.xml
Im Mandantenbetrieb müssen die Datenbankverbindungen in zwei Steuerungsdateien eingetragen werden: der db_*.properties für die Datenbankverbindung, und der dbforms-config.xml für die dbforms-Anbindung bzw. Saiku .. Nehmen wir an wir haben zwei Mandanten mit dem Kürzel
Diese Datenquellen müssen dann wie im Abschnitt zu dbforms erläutert in der Datei $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/dbforms-config.xml beim Tag <dbConnection …/> eingetragen werden:
|
Das Ende der Datei dbforms-config.xml bei mandantenfähigem Betrieb |
... name="jdbc:apache:commons:dbcp:7200" id="mdt_test1" isJndi="false" default="false" defaultConnection="false"/> <dbconnection conClass="org.apache.commons.dbcp.PoolingDriver" name="jdbc:apache:commons:dbcp:7300" id="mdt_test2" isJndi="false" default="false" defaultConnection="false"/> |
Wichtig ist, dass die Mandanten-ID mit der in der mandanten.cfg (s.o.) übereinstimmt.
Wenn die Konfiguration der Standardberichte wie oben beschrieben erfolgreich war, kann man auch Saiku für den Mandantenbetrieb vorbereiten. Löschen Sie dazu die Datei
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/classes/saiku-datasources/edustore
und fügen Sie im gleichen Verzeichnis für jeden Mandanten eine Datei mit beliebigem Dateinamen, z.B. 7200 hinzu, mit folgendem Inhalt:
type=OLAP
name=7200
driver=mondrian.olap4j.MondrianOlap4jDriver
location=jdbc:mondrian:Jdbc=jdbc:apache:commons:dbcp:7200;Catalog=res:edustore/edustore.xml;JdbcDrivers=org.apache.commons.dbcp.PoolingDriver;DynamicSchemaProcessor=de.superx.saiku.schema.SimpleSchemaProcessor
security.enabled=true
security.type=superx
Danach starten Sie Tomcat neu.
Es ist möglich, die Authentifizierung von Usern über eine LDAP-Datenbank laufen zu lassen.
Die User müssen aber auf jeden Fall in SuperX auch existieren und entsprechende Gruppenzugehörigkeiten und Rechteeinstellungen haben (Tabellen userinfo, groupinfo, user_group_bez, user_masken_bez,group_masken_bez,user_sachgeb_bez,group_sachgeb_bez, user_sichten etc).
Falls Sie ein eigenes Zertifikat für die Verschlüsselung Ihres LDAP-Servers einsetzen, muss dies
importiert werden in die Java Runtime.
Danach müssen Sie das Zertifikat auch Tomcat bzw. der JVM bekannt machen, die Tomcat startet. Erweitern Sie die Umgebungsvariable CATALINA_OPTS um den Parameter:
-Djavax.net.ssl.trustStore=<<Pfad zu den>>/cacerts
also z.B.
-Djavax.net.ssl.trustStore=/usr/local/tomcat/conf/cacerts
Kopieren Sie die Datei superx/WEB-INF/superx
_standalone_
ldap.properties.sam nach superx_standalone_ldap.properties und bearbeiten Sie diese – wenn SuperX beim Serverstart diese Datei findet, wird eine neue SuperX-interne LDAP-Passwortkontrolle aktiviert.
Sie finden auch in der catalina.out einen Hinweis
„Passwortkontrolle via LDAP wird aktiviert“. D.h. es wird nicht mehr auf die Tomcat eigene LDAP security-Technik gesetzt wie bis Kern4.8, da dies nicht kompatibel mit der neuen Spring-Technik ist.
In der sam-Datei ist eine Verbindung zu einem öffentlichen LDAP-Testserver vorkonfiguriert. Dort gibt es einen User „einstein“ mit Passwort „password. Wenn Sie in SuperX einen User „einstein“ anlegen und ein anderes Passwort wie „albert“, können Sie sich nach einer Aktivierung von LDAP mit „einstein“ und „password“ anmelden.
# SuperX LDAP Konfiguration für Passwortkontrolle
#Falls SuperX standalone betrieben wird, können hier LDAP Parameter hinterlegt werden
# Beispielparameter verwenden
# https://www.forumsys.com/tutorials/integration-how-to/ldap/online-ldap-test-server/
# Beispieluser auf diesem System einstein Passwort=password
# Wenn Sie in Superx einen User mit Kennung einstein anlegen, können Sie die Anmeldung via LDAP # testen
LdapUrl=ldap://ldap.forumsys.com:389
#
#Base Definition für die LDAP Suche, kann ggfs. um Gruppen erweitert werden, wie
# ou=superx_user,dc=example,dc=com
LdapBase=dc=example,dc=com
#
#Falls für den LDAP Zugriff ein ServiceUser (mit eigenem Passwort) benötigt wird, kann dies hier angegeben werden
#LdapServiceUserDN=cn=read-only-admin,dc=example,dc=com
#LdapServiceUserPassword=password
#
#
#
# Identifiying Attribute mit dem ein User mittels seiner Kennung gefunden wird (z.B. uid)
# z.B. bei Suchstring uid={0} einfach nur uid
# (ein komplexer Suchstring ist derzeit nicht möglich, passen Sie ggfs. die LdapBase-Definition an
#oder kontaktieren Sie uns unter support@superx-projekt.de
LdapIdentifyingAttribute=uid
Die alte Technik findet sich im Anhang im Kapitel „LDAP Konfiguration vor Kern 5.0“.
Passwortänderung : Falls ein Benutzer in SuperX dazu aufgefordert wird sein Passwort zu ändern, muss die Konstante „Passwortgültigkeit (Tage)“ angepasst werden. Diese Konstante dazu einfach auf einen möglichst hohen Wert setzen wie z.B. „1000000“. Danach noch die Tabelle user_pw leeren (alle Datensätze löschen).
Dieses Kapitel ist umgezogen:
http://www.superx-projekt.de/doku/kern_modul/tomcat/f_ApacheAnbindung.htm
Wenn Sie Apache2 einsetzen, blättern Sie bitte weiter .
Mit Hilfe des Openssl-Paketes sowie können Schlüssel für den Server erzeugt werden. Im Folgenden erläutern wir das Vorgehen unter SuSE Linux 8-9, für andere Distributionen müssen Sie ggf. die Verzeichnisnamen anpassen. Für die Installation verwenden wir zunächst ein selbst signiertes Zertifikat, was zwar den Nachteil hat, dass die Anwender vor dem Aufruf der Webseite eine Warnung erhalten ("Diese Seite stammt aus einer nicht vertrauenswürdigen Quelle..."), der Vorteil ist aber, dass das Vorgehen relativ einheitlich ist und später bei Bedarf leicht um ein öffentliches Zertifikat erweitert werden kann. Wenn die Verschlüsselung mit einem selbst signierten Zertifikat funktioniert, dann ist der Rest relativ einfach.
Wir führen alle Schritte als user root durch, und gehen z.B. davon aus, dass wir uns im Verzeichnis /root befinden.
Zunächst muss ein Zertifikat
erzeugt
werden.
Wenn Sie Ihr Zertifikat bei einer Zertifizierungstelle signieren lassen möchten, müssen eine
Zertifizierungsanfrage
erstellen.
Mit dem oben erstellten CA-Zertifikat können Sie Ihr http-Zertifikat folgendermaßen selbst signieren:
/usr/share/ssl/misc/CA.sh -sign
Es wird eine Datei newcert.pem erzeugt. Nachdem Sie nun ein signiertes Zertifikat für Ihre Anwendung erstellt haben, müssen Sie dieses nur noch in das entsprechende Verzeichnis kopieren und in der Konfigurationsdatei eintragen. Der Apache erwartet den privaten Schlüssel in einer separaten Datei, in solchen Fällen können Sie den privaten Schlüssel wie folgt extrahieren
openssl rsa -in newreq.pem -out newkey.pem
Nun bereiten wir den Neustart des Apache mit ssl-Modul vor. Die Einbindung mit Loadmodule und AddModule muss bei den meisten Distributionen nicht manuell gemacht werden.
|
Apache 1.3.x-SSL-Verschlüsselung unter SuSE Linux |
Unter SuSe Linux müssen Sie zunächst eine Umgebungsvariable setzen. Schreiben Sie in der Datei
/etc/sysconfig/apache:
|
Im Apache muss nun in der Steuerungsdatei httpd.conf der Pfad zum privaten und öffentlichen Schlüssel angegeben werden. Das folgende Beispiel geht davon aus, dass der öffentliche CA-Schlüssel auf der Website des Users superx (Modul public_html des Apache) unter /home/superx/public_html steht, und dass der private Schlüssel des Servers vom User root im Verzeichnis /root/demoCA erzeugt wurde.
|
Auszug aus der |
<VirtualHost <<Ipnr. des Webservers>>:443> SSLCertificateFile /home/superx/public_html/capub.crt
#
Server Private Key: |
Danach müssen Sie in /etc/sysconfig/apache die Systemvariable HTTPD_START_TIMEOUT auf einen sinnvollen Wert setzen, z.B. 10. Sie haben dann beim Start des Apache 10 Sek. Zeit, dass CA-Passwort einzugeben.
Wir geben als root im Verzeichnis /root/demoCA/private ein:
openssl rsa -in cakey.pem -out cakey2.pem
(1x mit der Passphrase bestätigen).
Dann wird ein Schlüssel ohne Passphrase erzeugt. Wenn wir diesen dann wiederum in /etc/httpd/httpd.conf eintragen:
#SSLCertificateKeyFile /root/demoCA/private/cakey.pem
SSLCertificateKeyFile /root/demoCA/private/cakey2.pem
Dann startet der Apache ohne Passwortabfrage. In diesem Fall kann man auch die Variable HTTPD_START_TIMEOUT auf 1 zurücksetzen.
Zum Abschluss können Sie bei einem selbst signierten Zertifikat die oben erstellte Datei /root/capub.crt auf den Webserver kopieren und mit folgendem Link auf Ihrer Webseite verfügbar machen:
<a href="capub.crt" type="application/x-x509-ca-cert">CA-Zertifikat</a>
Die Anwender können dann mit Klick auf Link das Zertifikat importieren und somit im Browser speichern, so dass die Warnung, dass die Quelle nicht vertrauenswürdig ist, nicht mehr kommt. Wir haben auch den Eindruck, dass das Applet dann schneller arbeitet.
Das Modul ssl ist im Apache 2.x nicht mehr separat zu installieren, sondern bereits im Lieferumfang enthalten, das Modul muss nur in den entsprechenden LoadModule und Include-Abschnitten geladen werden.
Wir führen alle Schritte als user root durch, und gehen z.B. davon aus, dass wir uns im Verzeichnis /root befinden.
Zunächst muss ein Zertifikat erzeugt werden. Das öffentliche CA-Zertifikat liegt z.B. in /root/demoCA/cacert.pem und der private Schlüssel liegt in /root/demoCA/private/cakey.pem ..
Nun werden die Schlüssel dem Apache2 bekannt gemacht. Die einzelnen Konfigurationsparameter werden bei SuSE Linux über die Sysconfig gesetzt:
|
Apache2 mit SSL |
SuSE-typisch wird die Konfiguration in einer Datei im Verzeichnis
/etc/sysconfig
abgelegt, nämlich in apache2. Dort setzen Sie in der Direktive |
Bei anderen Linux-Distributionen entfällt die sysconfig . Auch unabhängig von der Distribution wird beim Apache2 nicht mehr die gesamte Konfiguration in einer großen httpd.conf gesammelt, sondern in separaten conf -Dateien. Bei virtuellen Hosts zum Beispiel befinden sich die Konfigurationen in Dateien mit der Endung *.conf im Verzeichnis vhosts.d . Der Startpunkt ist aber immer die httpd.conf (standardmäßig in /etc/apache2 ).
Wenn Sie keine Virtual Hosts nutzen, dann können Sie den Abschnitt, der im Konfigurationsbeispiel /etc/apache2/vhosts.d/vhost-ssl.template beschrieben ist auch in der Datei /etc/apache2/default-server.conf einfügen:
|
/etc/apache2/ |
## |
Danach müssen Sie in /etc/sysconfig/apache2 die Systemvariable HTTPD_START_TIMEOUT auf einen sinnvollen Wert setzen, z.B. 10. Danach wie immer SuSEconfig ausführen.
Sie haben dann beim Start des Apache 10 Sek. Zeit, dass CA-Passwort einzugeben.
Wir geben als root im Verzeichnis /root/demoCA/private ein:
openssl rsa -in cakey.pem -out cakey2.pem
(1x mit der Passphrase bestätigen).
Dann wird ein Schlüssel ohne Passphrase erzeugt. Wenn wir diesen dann wiederum in /etc/httpd/httpd.conf eintragen:
#SSLCertificateKeyFile /root/demoCA/private/cakey.pem
SSLCertificateKeyFile /root/demoCA/private/cakey2.pem
Dann startet der Apache ohne Passwortabfrage. In diesem Fall kann man auch die Variable HTTPD_START_TIMEOUT auf 1 zurücksetzen.
Wenn Sie Ihren Besuchern das öffentliche CA-Zertifikat zum Download anbieten möchten, müssen Sie dieses zuerst in das entsprechende DER-Format konvertieren:
openssl x509 -in demoCA/cacert.pem -out capub.crt -outform DER
Es wird die Datei /root/capub.crt erzeugt. Auf diese Datei wird in der Apache-Variable SSLCertificateFile verwiesen (statt wie oben auf /root/demoCA/cacert.pem)
|
|
#
Server Certificate: |
Wenn Sie Ihr Zertifikat bei einer Zertifizierungstelle signieren lassen möchten, müssen eine Zertifizierungsanfrage erstellen.
Mit dem oben erstellten CA-Zertifikat können Sie Ihr http-Zertifikat folgendermaßen selbst signieren:
/usr/share/ssl/misc/CA.sh -sign
Es wird eine Datei newcert.pem erzeugt. Nachdem Sie nun ein signiertes Zertifikat für Ihre Anwendung erstellt haben, müssen Sie dieses nur noch in das entsprechende Verzeichnis kopieren und in der Konfigu rationsdatei eintragen. Der Apache erwartet den privaten Schlüssel in einer separaten Datei, in solchen Fällen können Sie den privaten Schlüssel wie folgt extrahieren
openssl rsa -in newreq.pem -out newkey.pem
Zunächst erzeugen Sie ein Zertifikat :
mkdir /etc/apache2/ssl
openssl req -x509 -nodes -days 1095 -newkey rsa:2048 -out /etc/apache2/ssl/server.crt -keyout /etc/apache2/ssl/server.key
Das Zertifikat binden Sie in der conf-Datei ein, defaultmäßig /etc/apache2/sites-enabled/000-default.conf :
<IfModule mod_ssl.c>
<VirtualHost _default_:443>
ServerAdmin webmaster@localhost
DocumentRoot /var/www/html
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
SSLEngine on
SSLCertificateFile /etc/apache2/ssl/server.crt
SSLCertificateKeyFile /etc/apache2/ssl/server.key
</VirtualHost>
</IfModule>
Danach aktivieren Sie SSL mit
a2enmod ssl
Sie können unter Ubuntu auch den Apache ssl-virtual host aktivieren
a2ensite default-ssl.conf
Dann können Sie den Port 80 auf den Port 443 umleiten:
<VirtualHost *:80>
ServerName superx-cloud.de
ServerAlias www.superx-cloud.de
Redirect / https://www.superx-cloud.de/
...
</VirtualHost>
<IfModule mod_ssl.c>
<VirtualHost *:443>
ServerAlias www.superx-cloud.de
ServerName superx-cloud.de
...
</VirtualHost>
</IfModule>
Und dann starten Sie Apache neu mit
/etc/init.d/apache2 restart
Mit ACME unter Linux lassen sich Zertifikate von der Initiative Let's encrypt signieren lassen. Die Zertifikate sind 3 Monate gültig, und haben eine eingebaute automatische Verlängerung implementieren. Gehen Sie dazu wie folgt vor:
Clonen Sie das Projekt von GitHub:
git clone https://github.com/Neilpang/acme.sh.git
Es wird ein Verzeichnis "acme.sh" erzeugt, mit dem Script "acme.sh". Dieses kopieren Sie als User root auf den Server, z.B. nach /root.
apt-get install socat
Dann installieren Sie den cronjob zum Aktualisieren:
Der Cronjob prüft jede Nacht um 0:44 Uhr, ob das Zertifikat abgelaufen ist, wenn nicht wird es erneuert. Danach müssen Sie die Shell neu öffnen, und bei zerossl registrieren:
./acme.sh --register-account -m git@superx-cloud.de --server zerossl
Dann erzeugen Sie die Zertifikatsdateien, am Beispiel der Domain "superx-cloud.de" auf einem Ubuntu-Apache, d.h. documentRoot ist /var/www/html :
./acme.sh --issue -d superx-cloud.de -w /var/www/html
Voraussetzung ist das Apache auf Port 80 läuft und die Firewall auf Port 80 frei ist (iptables).
Dann installieren Sie die Dateien in den A p ache, die Beispielverzeichnisse stammen aus der Ubuntu-Apache-Installation. Ggf. müssen Sie das Verzeichnis / etc/apache2/ssl noch erzeugen.
mkdir -p /etc/apache2/ssl
./acme.sh --install-cert -d superx-cloud.de --cert-file /etc/apache2/ssl/server.crt --key-file /etc/apache2/ssl/server.key --fullchain-file /etc/apache2/ssl.crt/server-ca.crt
SSL Aktivieren
Apache ssl-virtual host
ggf.
aktivieren,
u
nter Ubuntu:
a2ensite default-ssl.conf
Darin
ServerName
superx-cloud.de
SSLCertificateFile /etc/apache2/ssl/
superx-cloud.de
.crt
SSLCertificateKeyFile /etc/apache2/ssl/superx-cloud.de.key
SSLCertificateChainFile /etc/apache2/ssl/superx-cloud.de-fullchain.crt
SSLCACertificateFile /etc/apache2/ssl/superx-cloud.de-intermediate.crt
Danach starten Sie Apache neu.
Zum Mailversand von Logmails installieren Sie ein UNIX Mailprogramm. Unter Ubuntu Linux ist dies z.B. s-nail, das ein Binary namens " s-nail " bereitstellt:
apt-get install -y s-nail
Standardmäßig sucht s-nail den SMTP Server auf localhost, typischerweise muss ein externer Mailserver angebunden werden. Dazu legen sie im Homeverzeichnis des Benutzers eine Datei ".mailrc" an. Der Inhalt z.B.
set smtp="smtp://smtp.meinmailserver.de:587"
set from="superx@localhost"
set smtp-auth=login
set smtp-auth-user="meinemailkennung"
set smtp-auth-password=meinpasswort
Hinweis: es gibt auch andere Mailclients wie mutt oder mailx, wir haben s-nail gewählt weil die Syntax der obigen .mailrc-Datei und z.B. bzgl. den Anfügens von Attachments (z.B. für Logdateien) nach dem klassischen "mailx" orientiert ist. Letzteres wird nicht mehr weiterentwickelt.
Sie können den Mailversand dann testen z.B. mit
echo test | s-nail -s Testbetreff s upervisor@meinmailserver.de
Sie können auch Mailverteiler einrichten, mit dem Befehl alias:
alias sxadmin supervisor1@meinmailserver.de supervisor2@meinmailserver.de
Sie können den Alias als Adressaten verwenden, z.B. mit
echo test | s-nail -s Testbetreff sxadmin
Der Vorteil von browser-basierten Webclients ist es, dass prinzipiell keine Installationen auf den Clients notwendig sind, und dass sie plattformübergreifend arbeiten. Nur für das SuperX-Applet muss man das Java-Plugin installiert haben.
Um mit dem Browser komfortabel arbeiten zu können, sollten wenn möglich die aktuellen, gebräuchlichen Browser eingesetzt werden, z.B. Firefox, Netscape, Seamonkey oder den Internet Explorer:
• Mozilla Firefox 1.5 oder höher, Mozilla 1.4 oder höher, Seamonkey 1.0 oder höher
• Internet Explorer 6.0 oder höher
Weiterhin ist es notwendig, dass die Anwender mit Bearbeitungszugriff auch Javascript einschalten (beim IE nennt sich dies "Active Scripting"). Man kann dies auch nur für bestimmte Server (bzw. Sicherheitszonen) tun, so dass Sie nur den Superx-Server freischalten müssen. Außerdem sollten Sie hier die Datenübermittlung zwischen Frames erlauben.
Das SuperX-Applet wird bei jedem Aufruf (je nach Cacheing des Browsers) neu geladen; der Umstieg auf neue Versionen des Applets ist also ohne lokale Installationen möglich. Eine Bedienungsanleitung
zum Java-Client findet sich im
Benutzerhandbuch
.
Für die Installation der Java-Runtime reicht es meist aus, zur Aufruf-Seite vom Applet zu surfen. Es wird dann eine Installationsaufforderung inkl. Download von
http://java.sun.com
gestartet. Bitte nehmen Sie Java von Oracle, für andere Java-Versionen (IBM Java, GNU Java) wurden Probleme berichtet.
Für die Installation der Java Runtime benötigen Sie Administrationsrechte auf Ihrem Rechner.
Das SuperX- oder Joolap-Applet besitzt ein Zertifikat, damit man drucken kann und in die Zwischenablage kopieren darf. Ab Java Version 1.7.51 muss man dieses Zertifikat zu den vertrauenswürdigen Sites hinzufügen:
• Windows: Systemsteuerung öffnen, Linux KDE: Systemeinstellungen
• Auf das Java-Symbol doppelklicken
• Sicherheit wählen
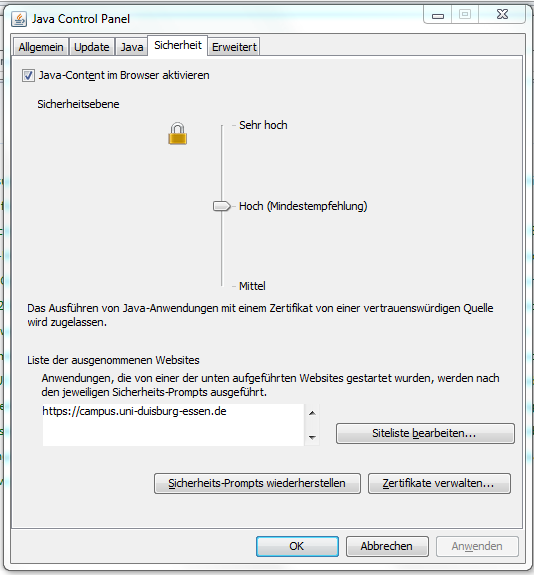
• Siteliste bearbeiten wählen
• Auf Hinzufügen klicken
• Die Webadresse https://... eintragen
• OK wählen
• Anschließend startet das Applet bzw. JOOLAP mit normalem Sicherheits-Prompt und wird nicht mehr abgebrochen.
Bei einigen Windows-Umgebungen (z.B. mit Netscape 6.1, ohne IE, oder mit Windows XP) läßt sich die Policy nicht scriptgesteuert installieren. Man muss dann die Policy dialogisch einrichten. Starten Sie dazu die Anwendung policytool , die sich im Lieferumfang der Java-Runtime befindet. Wenn Sie die Anwendung z.B. unter C:\Programme\Java\JRE\1.6.1_02\bin\policytool.exe installiert haben, dann starten Sie die Anwendung mit Doppelklick und gehen wie folgt vor:
|
Die AWT-Permission "AccessClipboard" muss gesetzt werden. |
|
|
Die Runtime-Permission "queuePrintJob" muss gesetzt werden. |
|
Danach klicken Sie auf "Done" und speichern die Policy im Home-Verzeichnis Ihrer Windows-Kennung, z.B. c:\dokumente und einstellungen\<<Ihre Kennung>>\.java.policy
Die Installationssite von SuperX erkennt, ob es sich um einen Linux-Browser handelt. Die Anwender werden zum Download auf die Seiten von Sun verwiesen.
Unter UNIX / Linux werden zunächst die Dateien der Java-Runtime bzw. des JDK der Firma Oracle installiert (s.o.).
Bei erfolgreicher Anmeldung erscheint folgendes Fenster:
Wenn es Probleme mit dem Start des Applets gibt, kann dies verschiedene Ursachen haben.
Unter Netscape ist aufgefallen, dass bei verschlüsselter Verbindung auf dem Server die Datei $superxdir/webserver/tomcat/webapps/superx/applet/superx_help/superx.hs im gleichen Verzeichnis auch mit dem Namen superx_de_DE.hs existieren muss.
Eine weitere Ursache können Sicherheitseinstellungen sein. Fügen Sie Ihren SuperX-Server zur Liste der vertrauenswürdigen Sites hinzu.
Hier als Beispiel die Einstellung für den Duisburger SuperX-Server im InternetExplorer.
|
Im InternetExplorer und Extras / Internetoptionen, Registerkarte „Sicherheit“ Punkt Vertrauenswürdige Sites. Auf „Sites“ klicken.
|
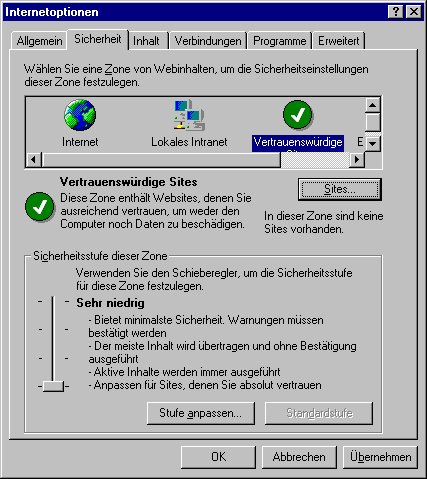
|
|
Danach gibt man wie gezeigt den SuperX-Server ein und klickt auf Hinzufügen und OK. |
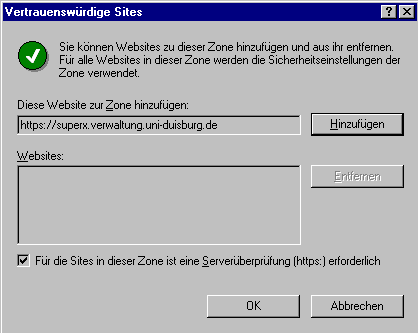
|
Im lokalen Netz kann es durch den Proxy zu Problemen kommen. Man sollte daher den Proxy-Server für lokale Adressen umgehen.
Im InternetExplorer geht das folgendermaßen:
|
Zunächst wählt man im IE-Menü Extras-> Internetoptionen aus und wechselt zur Registerkarte Verbindungen. Dann klickt man auf LAN-Einstellungen. |
|
Sofern „Proxyserver verwenden“ aktiviert ist, sollte man den Menüpunkt „Proxyserver für lokale Adressen umgehen“ ebenfalls aktivieren. |
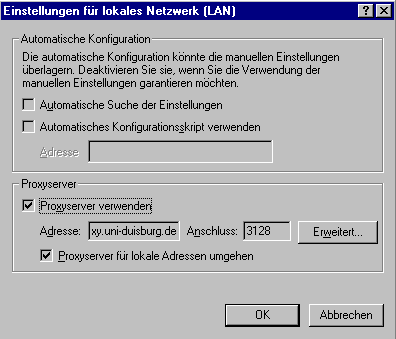
|
Auch Addons für WebBrowser wie "NoScript" können hier Probleme machen. Dabei reicht es z.B. bei "NoScript" nicht in den Einstellungen auf "Skripte allgemein erlauben"zu stellen. In dem Fall muss es deaktiviert werden.
Nach Veränderungen der Einstellungen ist es generell sehr sinnvoll den Cache zu leeren .
Wenn ein neues SuperX-Applet auf dem Webserver installiert wird, ist es möglich dass die Clients dies nicht sofort mitbekommen. Je nach Java-Version und Betriebssystem unterscheiden Sie sich Wege, den Browser-Cache zu leeren. Unter Windows mit Java 1.4.x wird der Browser-Cache geleert, bei Windows ab Java 1.5.x oder unter Linux wird der Java-Cache geleert. Im Zweifelsfall löschen Sie beide Caches.
Beim Browser-Cache sind die Einstellungen des Browsers maßgeblich. Beim Internet Explorer gehen Sie in das Menü "Extras"->"Internetoptionen"
|
In der Registerkarte "Allgemein" sehen Sie im Abschnitt "Temporäre Internetdateien" den Button "Dateien löschen"; klicken Sie darauf, und löschen Sie alle Inhalte. Danach klicken Sie auf "Einstellungen"… |
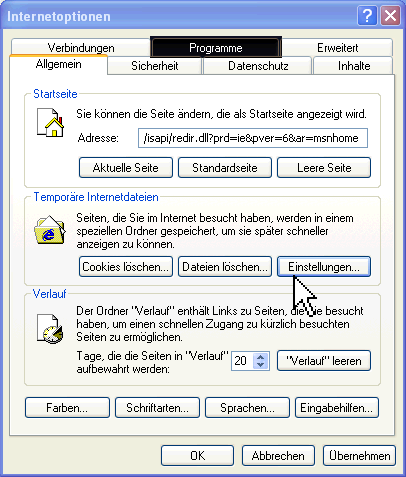
|
|
…und markieren Sie den Knopf "Bei jedem Zugriff auf die Seite". Dann drücken Sie "OK". |
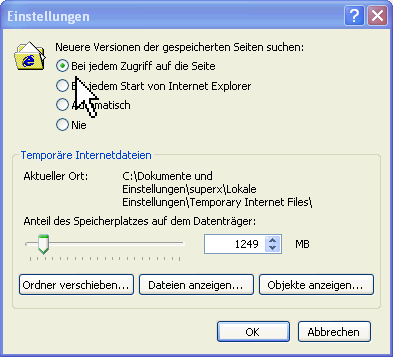
|
Starten Sie den Browser dann neu.
Bei Netscape/Mozilla befindet sich die Einstellung im Menü "Edit" (deutsch "Bearbeiten") -> "Preferences" (deutsch "Einstellungen").
|
Hier drücken Sie den Button "Clear Cache" ("Cache leeren") und kreuzen dann unten den Button "Every time I view the page" ("Bei jedem Zugriff auf die Seite") an. |
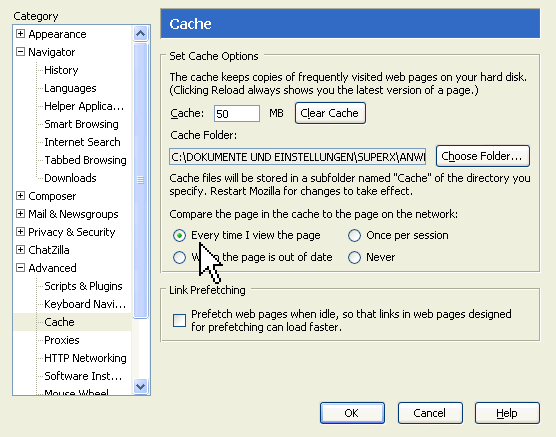
|
Starten Sie den Browser dann neu.
Unabhängig vom Webbrowser wird ein Java Cache gepflegt. Das Leeren des Browser-Cache bringt da keine Besserung. Man sollte bei neuen Versionen der Software in der Systemsteuerung im Java Control Panel im Abschnitt "temporäre Internetdateien" den Cache leeren (siehe Screenshot):
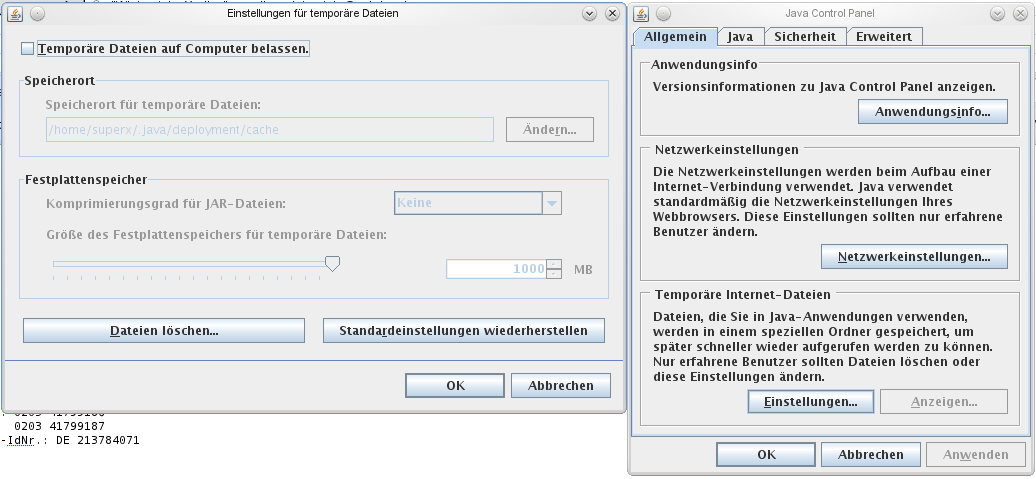
Wenn Sie keine Bandbreiten-Probleme haben, sollten Sie am besten sogar das Häkchen bei "Temporäre Dateien auf Computer belassen" entfernen.
Hinweis für ältere Java Runtimes:
Bei der Java-Runtime Java 1.5.x unter Windows sowie bei der Java Runtime 1.4.x unter Linux wird ein separater, vom Browser unabhängiger Cache genutzt, der manuell geleert werden muss. Löschen Sie also alle Inhalte in den Pfaden:
Unter Windows:
c:\Dokumente und Einstellungen\<<Kennung>>\Anwendungsdaten\
sun\java\deployment\cache\javapi\v.1.0\jar\*
Unter Linux:
/home/<<Kennung>>/.java/deployment/cache/javapi/v1.0/jar/*
Danach starten Sie den Browser neu.
An mehreren Stellen können Sie mit SSL Verschlüsselung in Berührung kommen:
Beim Datenbankzugriff mit SSL
Beim Verschlüsseln im Apache Server
Beim Zugang zu einem SSL-verschlüsselnden LDAP Server
Im folgenden eine Anleitung zum Erzeugen und Bereitstellen von Zertifikaten.
Auf dem Rechner, der verschlüsseln soll, muss das Paket Openssl installiert sein. Ist dies der Fall, kann man als User root ein Zertifikat erzeugen.
Wir führen alle Schritte als user root durch, und gehen z.B. davon aus, dass wir uns im Verzeichnis /root befinden.
Zunächst muss ein Zertifikat erzeugt werden:
openssl req -new -nodes -newkey rsa:2048 -keyout mydomain.key -out mydomain.csr
Sie die jeweiligen Angaben (Land, Organisation etc.). Beim "Common Name" muss der DNS-Servername des Servers angegeben werden. Ein Challenge Passwort ist erst einmal nicht notwendig. Der private Schlüssel ist nicht geschützt, sonst müßten Sie den bei der Nutzung (z.B. Apache Start) manuell eintippen.
Der private Schlüssel liegt in /root/ mydomain.key
Der öffentliche Schlüssel hat das RSA Format. In Java Runtimes und im Browser wird ggf. nur ein X.509 Zeirtifikat erlaubt. Dazu müssen Sie das öffentliche Zertifikat zuerst in das entsprechende DER-Format konvertieren:
openssl x509 -in mydomain.key -out capub.crt -outform DER
Es wird die Datei /root/capub.crt erzeugt.
Alternatives Vorgehen unter Ubuntu mit Ziel Zertifikat für Postgres:
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365
Eine
passphrase
ist nicht hilfreich, wenn Server automatisch neu gebootet werden können soll.
So kann man eine Entfernen:
openssl rsa -in [file1.key] -out [file2.key]
https://knowledge.digicert.com/solution/SO5292.html
Sie können ein neues Zertifikat erstellen und direkt einen Request für eine Zertifizierungsstelle erzeugen. Der Schlüssel sollte mind. 2048 bit haben. Das geht mit dem Befehl:
openssl req -new -nodes -newkey rsa:2048 -keyout mydomain.key -out mein_request.csr
Es wird ein Request in die Datei ./ mein_request.csr geschrieben.
Letzteren übergeben Sie an die Zertifizierungsstelle. Achten Sie dabei darauf, dass die Angabe bei "Common Name" exakt dem Domainnamen entspricht. Wie u openssl req -new -nodes -newkey rsa:2048 -keyout mydomain.key -out mein_request.csr nd in welchem Format Sie die Anfrage an die von Ihnen ausgewählte Zertifizierungsstelle senden müssen, erfahren Sie von der entsprechenden Zertifizierungsstelle.
Wenn Client Programme wie z.B. Java auf einen SSL verschlüsselten Server zugreifen, der über ein selbst signiertes Zertifikat verfügt, dann muss man das Zertifikat in den TrustStore von Java bzw. Tomcat importieren.
Es gibt einen systemweiten Truststore , wenn Sie das systemweiten TrustStore von Java verwenden, liegt dies in $JAVA_HOME/jre/lib/security/cacerts . Dann würde der Befehl lauten:
sudo keytool -import -alias myssl -file /root/capub.crt -keystore $JAVA_HOME/jre/lib/security/cacerts
Ggf. müssen Sie hier das Passwort des keystore eingeben (Standard wenn nicht verändert: changeit) . Danach kommt die Sicherheitsabfrage
Diesem Zertifikat vertrauen? [Nein]: Ja
Zertifikat wurde zu Keystore hinzugefügt.
Wenn Sie für Tomcat einen speziellen Truststore definieren, z.B. durch den Tomcat Start Parameter
-Djavax.net.ssl.trustStore=/usr/local/tomcat/conf/cacerts
dann müssen Sie den Zielpfad für den Import entsprechend anpassen:
sudo keytool -import -alias myssl -file /root/capub.crt -keystore /usr/local/tomcat/conf/cacerts
In der HISinOne-BI kann der TrustStore in der globalen Konfiguration im Parameter KEYSTORE=... gesetzt werden. Das Vorgehen wäre hier analog.
Achtung: Wenn Sie eine eigene Datei als keystore nutzen wollen, gibt es in manchen Tomcat/Java Konstellationen Probleme, z.B. bei Tomcat 7.0.22 und jdk1.7.0_51. Verwenden Sie in diesem Falle besser den Default ($JAVA_HOME/jre/lib/security/cacerts ).
Falls Sie das Zertifikat des Ziel-Server s nicht zur Hand haben, können Sie es auch direkt herunterladen . Gehen Sie im Browser auf die entsprechende URL und klicken Sie vor der URL auf das Schlüsselsymbol. Dort gehen Sie auf "Zertifikat anzeigen" -> Details. Je nach Browser/Version heißen die Menüpunkte unterscheidlich. Bei der Detailansicht des Zertifikats gibt es einen "Exportieren" Button. Hier ein Beispiel für Firefox:
Die Zieldatei bekommt eine Endung "*.crt".
Alternativ geht auch die Linux Kommandozeile:
openssl s_client -connect meinserver.de:443 -servername meinserver.de:443 < /dev/null | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' > meinserver.de.crt
Falls Das Zertifikat in x509 format benötigt wird, bitte folgenden Befehl verwenden:
openssl x509 -in <(openssl s_client -connect ads.hs-karlsruhe.de:636 -prexit 2>/dev/null) > my-ca.crt
Danach können Sie das Zertifikat importieren mit
$JAVA_HOME/bin/keytool -importcert -alias myssl -keystore $JAVA_HOME/jre/lib/security/cacerts -trustcacerts -file ./my-ca.crt
Der Befehl keytool ist recht flexibel, man kann damit auch Zertifikate anschauen ( -list ) oder löschen ( -delete ). Details liefert die Ausgabe von keytool -help .
An einigen Hochschulen gibt es ein Testsystem in dem Entwicklungen getestet werden und ein Produktivsystem in dem die stabilen Entwicklungen dann übertragen werden. Die Schwierigkeit bestand bisher, beide Systeme auf einen vergleichbaren Stand zu halten, damit das Testsystem auch einem reellen Test widerspiegelt. Außerdem gab es keine einfache Möglichkeit größere Änderungen vom Testsystem ins Produktivsystem zu übertragen. Um diese Möglichkeit zu erhalten gibt nun wie in allen anderen Modulen auch im Kernmodul eine Hauptladeroutine mit unload- und update-Funktion.
Über die Bordmittel der Laderoutinen (Unload / Copy / Upload) können also Konfigurationen übertragen werden.
Details zu den Laderoutinen jeweils für
• HISinOne-BI: https://wiki.his.de/mediawiki/index.php/Komponentenverwaltung_der_HISinOne-BI
• SuperX: Modulverwaltung
Im Kontext der Säulenübertragung in HISinOne kann neben der Copy-Funktion auch SVN / Git genutzt werden, Sie müssen dazu nur die Dateien
webapps/superx/WEB-INF/conf/edustore/db/install/rohdaten/unl/*.unl
aus dem SVN-Ignore /GIT-Ignore entfernen, auf dem Entwicklungssystem committen und auf der Zielsäule updaten.
Über die Entladeparameter können Sie steuern, welche Daten übertragen werden sollen. Hier gibt es default-Werte, die Sie in der KERN_ENV selber anpassen können. Falls Sie keine angaben dazu in der KERN_ENV machen, werden die default-Werte verwendet.
UNLOAD_USERRIGHTS
Hier handelt es sich um die Benutzerrechte aus dem Kernmodul. Es werden also die Benutzer, Gruppen, Sichtenrechte... übertragen. Spezielle Rechte wie die Kameralen Rechte des FIN Moduls sind hier nicht mit inbegriffen.
UNLOAD_FIN_USER_KAM
Hierbei handelt es sich nur im die Kameralne Rechte des FIN Moduls.
UNLOAD_KONSTANTEN
Hierbei handelt es sich um die Konstanten.
UNLOAD_UNLOAD_PARAMS
Hierbei handelt es sich um die Entladeparameter.
UNLOAD_REPOSITORY
Hierbei handelt es sich um die Repository Variablen
UNLOAD_HOCHSCHULINFO
Hierbei handelt es sich um die Tabelle Hochschulinfo mit Informationen wie Name, Anschrift... der Hochschule.
UNLOAD_THEMENBAUM
Hierbei handelt es sich um die Menüstruktur des Informationssystems.
UNLOAD_MASKEN
Hierbei handelt es sich um alle Berichte.
UNLOAD_STYLESHEETS
Hierbei handelt es sich um die Styles der Breichte. Achtung: Es werden nur die Datenbankeinträge übertragen keine Dateien aus dem Dateisystem. Die Stylesheets müssen daher extra kopiert werden.
UNLOAD_MAKROS
Hier werdne die Makros übertragen.
UNLOAD_CAPTIONS
Hierbei handelt es sich um die Beschreibungen von Feldern, Erläuterungstexten ...
UNLOAD_SICHTEN
Heirbei handelt es sich um die Sichten
UNLOAD_MAN_CATALOGUE
Hierbei handelt es sich um den Zahlenkatalog des MAN Moduls.
UNLOAD_MAN_ZAHL_WERT
Hierbei handelt es sich um eigene Werte der Hochschule für das MAN Modul.
UNLOAD_KENN_ZAHL_WERT
Hierbei handelt es sich um eigene Werte der Hochschule für das KENN Modul.
Wie üblich muss in der KERN_ENV die DB Verbindung eingerichtet werden und auch die Entladeparameter. Über die Scripte kern_unload.x werden dann die Tabellen aus dem jeweils anderen SuperX entladen und per kern_update.x in das verwendete SuperX eingespielt.
Der Update eines bestehenden SuperX ist nicht trivial: Es kursieren verschiedene SuperX-Versionen, und das System ist offen für Änderungen durch den Benutzer. Deshalb müssen die Dateien unterhalb von $SUPERX_DIR gesichert werden, und die Datenbank muss vorher exportiert werden. Generell gilt beim Upgrade, dass Sie keinesfalls das normale SuperX-Komplettpaket herunterladen und entpacken sollten, weil dadurch individuelle Konfigurationen überschrieben würden.
Stattdessen sollte Sie immer das passende Upgrade- bzw. "Patch"-Paket herunterladen. Die von Ihnen genutzte Version (zu finden in der Datei $SUPERX_DIR/db/install/VERSION) gibt dazu den besten Anhaltspunkt.
Als erstes müssen Sie sich einen Patch von der Seite http://download.superx-projekt.de/ herunterladen. Dabei ist zu beachten welches System und welche Codierung benötigt wird. Informationen über die Änderungen des Patches finden Sie als Link auf der Downloadseite. In dem Patch selber befindet sich auch noch eine patch_xxxx-xx-xx_readme.txt .
Vorbedingung ist, dass das Paket unzip installiert ist.
Legen Sie sich für die Patches ein Verzeichnis auf dem SuperX Server an. Am einfachsten wäre z.B. /home/superx/patches. In dieses Verzeichnis kopieren Sie den Patch.
Um Patches in SuperX einzuspielen gibt es das Script $SUPERX_DIR/db/bin/patch_apply.x . Das Script starten Sie direkt aus dem Patchordner, in dem der zu installierende Patch liegt. Gestartet wird es folgendermaßen:
patch_apply.x <<PatchFile>>
Ein Beispiel:
patch_apply.x patch_2011-06-01_superx_iso.zip
Dabei wird in dem Verzeichnis der Patch entpackt und ausgeführt.
Beim Upgrade des Kernmoduls gibt es ab Version 4.0 ein standardisiertes Vorgehen. Hier das Vorgehen für Kernmodul 4.x oder höher "in short":
Beenden Sie Tomcat und machen Sie eine Sicherung der Datenbank mit
cd $SUPERX_DIR/db/install
dump_it.x
Laden Sie das Kern- Patch-Paket für Ihr DBMS (Postgres, Informix) und Codierung (iso, utf-8) herunter, z.B. kern4.3_superx_iso_POSTGRES_patch.tar.gz , und entpacken Sie es in $SUPERX_DIR
cd $SUPERX_DIR/db/install/upgrade
kern_env_upgrade.x
. ../../bin/SQL_ENV
kern_upgrade.x
Weitere Hinweise:
Um sicher zu gehen empfehlen wir mit dem Script $SUPERX_DIR/db/install/dump_it.x die Datenbank in einer Datei zu sichern und anschließend von dem gesamten $SUPERX_DIR ein Backup anzulegen, bevor Sie mit dem Upgrade beginnen.
Achtung: Fürs Kernmodul 4.9 benötigen Sie Java 1.8 in der aktuellen Version. Java 11 wird derzeit noch nicht unterstützt. Demensprechend benötigen Sie auch Tomcat 8.*.
Bei Oracle gibt es seit 2019 nur noch kommerzielle Pakete vom Java / JDK, mit "Registrierungszwang". Unter Linux installieren Sie OpenJDK 1.8 mit den Paketquellen, also z.B. bei Ubuntu Linux:
apt-get install -y openjdk-8-jdk
Für andere System: der Download der quelloffenen OpenJDK-Pakete befindet sich für die jew. Versionen und Betriebssysteme hier:
Beim Umstieg von Kernmodul 4.x auf 4. 9 gibt es noch eine wichtige Änderung: in der Datei $ SUPERX_DIR /db/bin/SQL_ENV muss die Variable CATALINA_OPTS um den Passus " -DSuperX-DB-PROPERTIES-SET=true -DMODULE_PFAD=$SUPERX_DIR/db/module " erweitert werden. Siehe SQL_ENV .
Außerdem müssen Sie beim Umstieg aufs Kernmodul 4.9 die Datei $WEBAPP/WEB-INF/web.xml erweitern um die neue REST-Schnitstelle .
1. Kern Paket von der Seite http://download.superx-projekt.de/ herunterladen.
2. Tomcat beenden
3. Auf dem Tomcat-Server das Verzeichnis $SUPERX_DIR/webserver/tomcat nach $SUPERX_DIR/webserver/tomcat_old kopieren. Dies dient als Backup Verzeichnis und es werden später noch ein paar Dateien davon benötigt.
4. Verzeichnis $SUPERX_DIR/webserver/tomcat bis auf den Ordner webapps leeren.
5. Verzeichnis $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/lib/ leeren.
1. Kernpaket im $SUPERX_DIR entpacken.
2. (Nur bei Mandantenbetrieb) In der web.xml bei de.superx.servlet.SuperXmlAbmeldung die Parameter init-param löschen.
3. Wenn Sie Kernmodul 3.x installierten und bisher immer das Kernmodul geupgradet haben, haben Sie noch Tomcat Version 4. Um dies umzustellen müssen Sie die Connections-Angaben in der server.xml in die Datei webapps/superx/META-INF/context.xml übertragen (.sam-Datei liegt im gleichen Verzeichnis). Dafür gibt es auch ein Script:
sx_transform.x -IN:$SUPERX_DIR/webserver/tomcat_old/conf/server.xml -XSL:$SUPERX_DIR/db/conf/server_xml2context_xml.xsl -OUT:$SUPERX_DIR/webserver/tomcat/webapps/superx/META-INF/content.xml -method:xml
4. Wenn Sie Kernmodul 4. 9 installierten, haben Sie bereits Tomcat 8 und damit auch obige Datei context.xml. Diese muss daher nur aus dem alten Tomcat Verzeichnis in das neue übernommen werden.
5. Falls Sie UTF-8 Charset benutzen muss in der Datei conf/server.xml bei dem Connector mit dem Port 8080 noch:
URIEncoding="UTF-8"
ergänzt werden. Es sieht dann folgendermaßen aus:
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8" />
6. Achten Sie darauf, dass Tomcat die Variable $JRE_HOME benutzt und diese richtig gesetzt ist. Eventuell $JRE_HOME auf $JAVA_HOME/jre setzen.
7. (Nur bei Mandantenbetrieb) $JDBC_CLASSPATH und $XML_CLASSPATH muss für die Mandanten in der SQL_ENV gesetzt werden.
8. Für den Tomcat-Start e rgänzen Sie auch die Umgebungsvariable CATALINA_OPTS um den Parameter -DSuperX-DB-PROPERTIES-SET=true -DMODULE_PFAD=$SUPERX_DIR/db/module .
Bevor Sie den Upgrade ausführen müssen Sie zunächst in das Verzeichnis $SUPERX_DIR/db/install/upgrade/ wechseln und dort das Script kern_env_upgrade.x starten und danach die SQL_ENV neu laden. Nun muss nur noch das Upgradescript kern_upgrade.x in dem Verzeichnis $SUPERX_DIR/db/install/upgrade/ ausgeführt werden.
Wenn Sie den mitgelieferten Tomcat nutzen ergänzen Sie auch die Umgebungsvariable CATALINA_OPTS um den Parameter -DSuperX-DB-PROPERTIES-SET=true -DMODULE_PFAD=$SUPERX_DIR/db/module.
Wenn Sie den Datenbankserver und Webserver getrennt haben, muss das Kernpacket auch auf dem Webserver entpackt und der ENV UpgradeScript kern_env_upgrade.x gestartet werden.
Wenn der Apache mit mod_jk angebunden ist müssen auch die folgenden Dateien aus dem alten Tomcat übernommen werden:
$SUPERX_DIR/webserver/tomcat/conf/superx_mod_jk.conf
$SUPERX_DIR/webserver/tomcat/conf/workers.properties
Joolap läuft erst ab der Version 1.2 mit dem Kernmodul 4.1 zusammen. Daher prüfen Sie welche Joolap Version Sie einsetzen und aktualisieren diese gegebenenfalls.
Da die web.xml ersetzt wurde, müssen die Einträge für Joolap wieder eingefügt werden. Eine Anleitung finden Sie dazu in dem Joolap-Admin Handbuch .
Wenn Sie nach dem Kernupgrade Joolap nicht aurufen können und in der Datei $SUPERX_HOME/webserver/tomcat/logs/catalina.out steht, dass der ConnectionPool zu der HSQLDB nicht aufgebaut wer den kann, da der Treiber fehlt, muss dieser noch in das Tomcat Verzeichnis koppiert werden. Kopieren Sie dann bitte die Datei $SUPERX_HOME/joolap/lib/joolap.jar nach $SUPERX_HOME/webserver/tomcat/lib .
Danach bitte den Tomcat neu starten.
Vor der ersten Verwendung von Saiku sollten die Konfigurationen aus dem Kapitel Verwendung von Mondrian / Saiku geprüft werden. Wichtig ist, dass sie die Datei $WEBAPP/WEB-INF/classes/edustore/edustore.xml sichern bzw. sogar versionieren.
Bei dem Upgrade von einem Modul werden die Cubes und Dimensionen des jeweiligen Moduls in Mondrian automatisch mit aktualisiert.
Wenn Sie einen mandantenfähige SuperX-Installation upgraden, müssen Sie auf einen Schlag alle Mandanten aktualisieren, es ist nicht möglich einzelne Mandanten mit der älteren Version arbeiten zu lassen.
Der Datenbank-Upgrade bei mandantenfähigen Installationen verhält sich genauso wie der Upgrade einer Einzelplatz-Installation - mit einer Ausnahme: Die Umgebung für den Mandanten wird nicht in der Datei $SUPERX_DIR/db/bin/SQL_ENV gespeichert, sondern in einer speziellen Mandaten-Datei, z.B. $SUPERX_DIR/db/bin/SQL_ENV_PHHD .
Da das Upgrade-Script diesen Dateinamen nicht kennt, muss normalerweise eine Änderung manuell vollzogen werden: In der Datei müssen alle Nennungen von der Datei " superx*.jar " geändert werden nach " superx4.2jar " (z.B. in Variable JDBC_CLASSPATH ).
Dafür gibt es aber ein Script kern_env_upgrade.x. Dieses Script nimmt einige Änderungen automatisch vor. Zudem Startet es auch automatisch das Script upgradeMandantendir.x falls die Variable MANDANTENID gesetzt ist und es einen Ordner mit der MandantenID unter $WEBAPP gibt.
Der
Upgrade der Webapplikation
entspricht dem Vorgehen wie oben gezeigt, mit einer Ausnahme: Sie müssen wie gehabt über das Script
$SUPERX_DIR/webserver/tomcat/webapps/superx/upgradeMandantendir.x <<MANDANTID>>
jeden einzelnen Mandanten aktualisieren. Im Kernmodul 3.5 wurde korrigiert, dass die der Datei
$SUPERX_DIR/webserver/tomcat/webapps/superx/<<MANDANTID>>/xml/anmeldung.htm
das versteckte Feld "mandantid" nicht mehr überschrieben wird, Sie können also sofort loslegen.
In dem Ordner $WEBAPP/$MANDANTENID/xml muss bei Mandantensystemen in der index.htm den JSP Seiten die MandantenID übergeben werden. Hier ein Beispiel für die 3 JSP Seiten mit der MandantenID PHHD:
• header_wiki.jsp?MandantenID=PHHD
• anmeldung_wiki.jsp?MandantenID=PHHD
• welcome_wiki.jsp?MandantenID=PHHD
Dies wird bei dem Script upgradeMandantendir.x automatisch gesetzt.
Allgemeine Hinweise siehe Datenschutzdokumentation .
Verwenden Sie nach Möglichkeit nicht die Standardkennungen (superx, admin und testuser), die bei Auslieferung im SuperX-Kernmodul enthalten sind. Richten Sie eine bzw. mehrere neue Administrator-Kennungen an und arbeiten mit diesen. Die Standardkennungen superx, admin, testuser sollten aus der SuperX-Tabelle userinfo gelöscht werden.
Um das logging im Applet abzuschalten, setzen Sie in $WEBAPP/applet/superx.properties „ logToKonsole“ auf „ none“ .
Falls Sie das Applet nicht benötigen löschen Sie das Verzeichnis
$WEBAPP/applet
Außerdem wird die Sicherheit erhöht, wenn ein Zugriff auf das nur vom Applet benutzte Servlet SuperXDBServlet unterbunden wird.
Bearbeiten Sie dazu Ihre Datei $WEBAPP/WEB-INF/web.xml
|
Kommentieren Sie das Servlet aus mit den Zeichen <!-- und -->
Ergänzen Sie ein Eintrag |
<!-- ************************* SUPERXDBSERVLET ************************************ -->
<servlet>
|
Starten Sie danach Tomcat neu.
Das Applet genügt von seiner Anlage her nicht mehr den modernen Sicherheitsanforderungen und wird mit dem Kernmodul 3.5 durch das XML-Frontend ersetzt. Wenn Sie das Applet dennoch einsetzen wollen: Zur Erhöhung der Sicherheit ist es möglich, eine DSA-public/private-Key-Kontrolle zu installieren. Dabei wird jeder Befehl, der vom Applet ans Servlet geschickt wird, mit dem einen Key signiert. Im Servlet wird mit Hilfe des anderen, nur dort bekannten Keys kontrolliert, ob der ankommende Befehl eine gültige Signatur aufweist.
Im Applet können Sie den Info-Button anklicken, in der erscheinenden Infobox wird angegeben, ob public/private key Kontrolle aktiv ist oder nicht.
Zur Erhöhung der Sicherheit ist es möglich, dass die Datenbankverbindung von Tomcat zur Datenbank mit einem eingeschränkten User durchgeführt wird. Dies wird von ZENDAS (Zentrale Datenschutzstelle der baden-württembergischen Universitäten) für den Produktivbetrieb nachdrückliche empfohlen.
Richten Sie dazu einen entsprechenden eingeschränkten User in Ihrer Datenbank ein und geben Sie diesen beim Propadmin bei eingeschränkter User an. Details dazu siehe Kapitel Datenbankverbindung über einen eingeschränkten User für mehr Sicherheit .
Exkurs:
Wenn Sie die höchste Sicherheit wollen, aber der Zuständige für die Userverwaltung trotzdem das XML-Frontend benutzen können soll, könnten Sie folgendermaßen vorgehen:
• Richten Sie für den regulären Betrieb einen eingeschränkten User mit minimalen Rechten ein, wie oben beschrieben und deaktivieren Sie alle Datenbankformulare, indem Sie nach jedem Komponentenupgrade das Verzeichnis $WEBAPP/edit leeren.
• Erzeugen Sie einen weiteren eingeschränkten Datenbankuser, der zusätzlich die Kernkomponententabellen bearbeiten darf.
• Richten Sie einen zweiten Tomcat ein, der mit diesem zweiten eingeschränkten Datenbankuser arbeitet.
• Sorgen Sie (z.B. per Firewall) dafür, dass nur der für die Userverwaltung zuständige Mitarbeit Zugriff auf den zweiten Tomcat hat.
Entfernen Sie temporäre Dateien, die sich auf dem Webserver befinden (z.B. mit Endung ~ oder #Untitled#). In $SUPERX_DIR/db/bin steht das Skript remove_tmp.x zur Verfügung. Es entfernt automatisch alle Dateien mit den Endungen ~ , tmp und bak sowie #Untitled#- Dateien aus dem aktuellen Verzeichnis und dessen Unterverzeichnissen. Optional kann auch ein Pfad angegeben werden, in dem die Dateien gelöscht werden sollen, z.B.: remove_tmp.x $WEBAPP
IP Adressen gelten laut DSGVO als Personenbezogene Daten. Da aus den Logdateien auch Statistiken erstellt werden können müssen die Benutzer diesem zustimmen, ander n falls darf die IP Adresse nicht mit geloggt werden. Leider ist bei Apache und Tomcat bisher noch nichts implementiert, über das die IP Adressen anonymisiert werden können. Hier werden ein paar Beispiele aufgelistet, wie die IP Adressen aus dem Logfile gelöscht werden können:
• Ein Script von SuperX lautet anonym_ip.x und liegt unterhalb von db/bin/. Als ersten Parameter kann eine Datei oder ein Verzeichnis angegeben werden. Die Datei oder die Dateien in dem Verzeichnis (nicht rekursiv) werden nach IP (v4 und v6) gesucht und mit „*.*.*.*“ ersetzt. Das Script kann somit per Cronjob ausgeführt werden und regelmäßig in den Logdateien die IP Adressen anonymisieren.
• Es gibt auch ein Python Script von https://www.privacyfoundation.ch/en/services/anonip.html (GITHub: https://github.com/DigitaleGesellschaft/Anonip ) Das Script ist aber nicht offiziell in Apache oder Tomcat zu verwenden und muss manuell eingepfle werden. Im Internet gibt es dazu diverse Anleitungen, die das Anonymisieren direkt oder erst im nächtlichen Logrotate durchführt.
•
Mit sed selber ein Script schreiben. Der Befehl ist einfach:
sed 's/[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}/\*\.\*\.\*\.\*/g' access.log
Das könnte man per Cronjob regelmäßig ausführen. Um Logeinträge OnTheFly zu bearbeiten wird es komplizierter.
• Eine Möglichkeit wäre noch access Log f iles ganz abschalten.
Wenn Sie nicht das gesamte Kernmodul inkl. Tomcat benötigen, sondern nur ein kleines Paket, um regelmäßige Administrationsaufgaben zu erledigen, haben wir ein Clientpaket "geschnürt", das die wichtigsten Werkzeuge zur mit dem DWH beinhaltet. Insbesondere Windows-Anwender können dieses Paket benutzen, um mit dem DWH zu arbeiten, z.B. Masken entwickeln, Tabellen entladen etc. Dazu enthält das Paket ein paar Werkzeuge.
Das Client-Paket wird außerdem für das Entladen aus HIS-Systemen unter Windows genutzt.
Laden Sie das Paket client<<Versionsnummer>>_<<Codierung>>.zip und speichern Sie es lokal auf der Festplatte.
Entpacken Sie dieses Archiv in einem separaten Verzeichnis, z.B.
c:\Programme\edustore_client
,
und benennen Sie die Dateien um; unter Windows:
bin\client_env_sam.bat
nach
bin\client_env.bat
bzw. unter Unix:
bin/client_env.x.sam
nach
bin/client_env.x
Passen Sie die Parameter in der Datei an, und sorgen Sie bei Bedarf dafür, daß die Datei beim Aufruf der Shell ausgeführt wird (unter DOS autoexec.bat , unter Linux / bash die ~/.bashrc ).
Folgende Parameter müssen Sie wahrscheinlich anpassen:
JAVA_HOME
(Der Pfad zur JRE)
CLIENT_DIR
(das Verzeichnis, in dem Sie den Client entpackt haben)
Folgende Parameter sind wichtig, aber meist korrekt vorbelegt:
JDBC_CLASSPATH (der Pfad zu Ihrem jdbc-Treiber)
DB_PROPERTIES (der Pfad zu den Datenbankparametern)
Wenn die Datei fertig eingerichtet ist, wird sie wie folgt in die aktuelle Shell geladen:
Unter DOS:
client_env.bat
Unter Unix:
. client_env.x
Mit dem Clientpaket können Sie u.a. auf die DWH-Datenbank zugreifen. Um dies zu tun, werden die Verbdingsdaten in einer properties-Datei gespeichert, die standardmäßig im Verzeichnis
conf
gespeichert wird. Starten Sie zunächst den
propadmin
mit
propadmin.bat
(DOS)
bzw.
propadmin.x
(Linux)
Dort geben Sie die Parameter für den DB-Zugriff ein. Das Passwort wird verschlüsselt
gespeichert. Danach sind die Kommandozeilen-Werkzeuge verfügbar. Unter Unix sind alle dort genannten Scripte nutzbar, unter DOS nur eine Auswahl (erkennbar daran, dass es eine Datei mit der Endung ".bat" im bin-Verzeichnis gibt).
Im Clientpaket befinden im Ordner tools die Anwendungen Jedit sowie die sqlWorkbench sowie das Access-Frontend . Diese Tools dienen zur Abfragenentwicklung. Details dazu finden Sie im Entwicklerhandbuch.
Sie können mit dem Clientpaket auch Berichtsausgaben automatisch vom Server herunterladen. Dazu müssen Sie zunächst eine Kennung einrichten, die die entsprechenden Rechte besitzt. Wenn Sie die Kennung in HISinOne pflegen, müssen Sie sich einmalig in den Grunddaten- und Basisberichten anmelden, und danach muss der Administrator dieser Kennung ein "echtes" Passwort zuweisen.
Wenn dies geschehen ist, können Sie sich zunächst im Browser einen Link zusammenbasteln, der den Bericht ohne Login-Dialog anzeigt. Die URL dafür lautet:
http(s)://Servername:Port/superx/servlet/SuperXmlTabelle?tid=<<Maskennummer>>&kennung=<<Kennung>>&passwort=<<Passwort>>&<<ggf. weitere Parameter>>
wobei die Maskennummer für die eindeutige Nummer der Maske steht. Sie erfahren die Maskennummer, indem Sie die jeweilige Modulbeschreibung konsultieren, oder indem Sie einfach die Maus über den Link halten, dann wird die Nummer im Browser unten in der Statusleiste angezeigt.
Neben der Maskennummer muss die Kennung und das Passwort übergeben werden, sowie je nach Maske weitere Felder.
Einfaches Beispiel: Das Prüfprotokoll in der Komponente Stellen, Personal:
http://localhost:8080/superx/servlet/SuperXmlTabelle?tid=19220&kennung=superx&passwort=anfang12
Wenn diese Link im Browser funktioniert, können Sie die Datei wie folgt im Excel-Format herunterladen:
DOS (Achtung: die Zeichen "=" und "&" müssen mit Caret-Zeichen ("^") vorangestellt werden, außerdem muss die URL in Anführungszeichen gesetzt werden, sonst klappt die Parameterübergabe in DOS nicht):
wget.bat "http://solomon:8080/superx/servlet/SuperXmlTabelle^?tid^=19220^&kennung^=superx^&passwort^=anfang12" pruefprotokoll.xls
Unix:
wget.x 'http://localhost:8080/superx/servlet/SuperXmlTabelle?tid=19220&kennung=superx&passwort=anfang12' pruefprotokoll.xls
Die Datei wird im gleichen Verzeichnis gespeichert.
Sicherheitshinweis: wenn Sie Passworte im Klartext in Browser-Adressleisten oder in Login-Shells eintippen, werden diese an verschiedenen Stellen gespeichert. Im Browser ist es die Chronik bzw. der Cache, in der Shell ist es die Eingabehistorie. Dies macht es anderen Anwendern leicht, die Passworte auszuspähen. Sie sollten daher die Passworte in Shellscripte verlagern, die ohne Login-Shell ablaufen. Diese Shellscripte wiederum dürfen nicht von unbefugten Personen eingesehen werden, stellen Sie die Leserechte im Dateisystem entsprechend her..
Im Tandem mit dem obigen Berichtsdownload können Sie auch Berichtsausgaben per Mail versenden. Dafür sind im Pakt Scripte zum Verschicken von Dateien per Email
sendmail.bat (für Windows)
sendmail.x (für Linux)
Es sind die folgenden Parameter vorgesehen:
sendmail.bat --to test@test.de --from system@super-ics.de --host smtp.strato.de --ssl (optional wenn SSL verwendet werden soll) --username system --password geheim --subject "COB Prüfprotokoll" --msg "Hier erhalten Sie Ihre Protokolle" (optional) --msgfile c:\nachricht.txt (optional) --attach c:\protokoll.xls (optional)
Die Parameter sind selbsterklärend. Der Parameter "--subject" kennzeichnet die Betreffzeile, und in den Mailtext selbst kann man "--msg Nachricht" oder mit "--msgfile Dateiname" auch den Inhalt von Textdateien kopieren. Außerdem wird mit dem Parameter "--attach Dateiname" eine Datei angehängt.
Im folgenden werden zentrale Arbeitsschritte beim Betrieb von SuperX beschrieben. Für einen Blick auf den Hintergrund sollten Sie sich ggf. die Bestandteile anschauen.
Zuächst zeigen wir, wie die Frontends funktionieren, und dann beschreiben wir die Werkzeuge für die Administration von SuperX.
SuperX verfügt über unterschiedliche Benutzeroberflächen, hier "Frontends" genannt. Das SuperX-Applet dient dem allgemeinen Berichtswesen und liefert vordefinierte Ergebnistabellen. Die Installation des Applets auf den Clients ist in der Installationsanleitung beschrieben. Die Funktionsweise des Applets ist ausführlich in dem Benutzerhandbuch dokumentiert.

|
Das XML-Frontend liefert komplexe Berichte, die aus mehreren Ergebnistabellen zusammengestellt werden, und die flexibel für verschiedene Ausgabegeräte und –formate aufbereitet werden können. Im Gegensatz zum Applet sind keinerlei Installationsschritte notwendig, es genügt ein html4-fähiger Browser. Derzeit ist das XML-Frontend noch im Betastadium. |

|
Joolap bietet die Möglichkeit, multidimensionale Auswertungen zu machen und Statistiken flexibel den eigenen Bedürfnissen anzupassen. Joolap wird mit einer eigenen Dokumentation ausgeliefert. |
Die Verwaltung des Organigramms und des Themenbaums sowie grundlegende User- und Gruppenverwaltung lässt sich mit Hilfe eines graphischen Administrationswerkzeugs SuperXAdmin (Betaversion 1.0) sowie über ein Access-Frontend erledigen. Es gibt neben der Shell-Zugang über UNIX zwei Administrationswerkzeuge für das Kernmodul: Browser-basierte Formulare im XML-Frontend , die auf die DBFORMS-Technologie zurückgreifen. Außerdem wurde ein Access-Frontend entwickelt, dass über ODBC-Verknüpfung einen direkten Zugriff auf die SuperX-Tabellen liefert. Das Browser-basierte Frontend hat den Vorteil, dass es auch über eine http-Verbindung arbeitet und somit höhere Sicherheitsstandards erfüllt. Das Access-Frontend eignet sich besser für die direkte Bearbeitung einzelner Tabellen und für die Entwicklung von Abfragen. Die Funktionalität ist ansonsten identisch, deshalb wird im folgenden nur die Oberfläche des Browser-Frontends beschrieben. Lediglich die Abfragenbearbeitung mit dem Access-Frontend wird gesondert dargestellt.
Mit folgenden UNIX-Kommandos können Sie die Auslastung des Servers feststellen:
|
free -m |
Zeigt den genutzten Arbeitsspeicher an |
|
top |
Zeigt die Prozesse und deren Prozessor/RAM-Auslastung an |
|
ps fax | grep superx |
Zeigt an welche Prozesse überhaupt laufen (unter AIX: |
|
kill -9 <<ProzeßID>> |
Beendet einen Prozeß |
Für die Administration des DataWarehouse sind Shellscripte vorbereitet, die flexible Werkzeuge zur Datenbankadministration bereitstellen. Die Shellscripte werden in den Update-Scripten aufgerufen, können aber auch zur manuellen Administration benutzt werden. Die wichtigsten Bereiche sind die Masken-Verwaltung und die Ladescripte im Umgang mit Tabellen sowie allgemeine Scripte.
Alle Scripte befinden sich unter $SUPERX_DIR/db/bin, deshalb muss dieser Pfad inder Umgebungsvariable PATH enthalten sein. Die Scripte wurden unter UNIX entwickelt (ohne Endung oder Endung .x ), einige davon sind auch nach DOS portiert worden (erkennbar an der Endung .bat ).
Einige Scripte lauten "sx_auto_"..., dies bedeutet, dass die Scripte ohne Sicherheitsabfrage ausgeführt werden.
Voraussetzung für den Ablauf der Scripte ist die Eintragung der korrekten Umgebungsvariablen in $SUPERX_DIR/db/bin/SQL_ENV bzw. $SUPERX_DIR\db\bin\sql_env.bat . Wenn der Client jdbc verwendet wird, muss ausserdem die korrekte DB_PROPERTIES gesetzt sein.
Das Script $SUPERX_DIR/db/bin/SQL_ENV steuert die Umgebung und ist für den Betrieb der Scripte unverzichtbar. Einige Variablen sind vorbelegt, Beispiele sind auf Kommentar gesetzt. Da die Umgebung von dem System abhängt, muss jeder Anwender die Werte manuell pflegen. Bei einem Update des SuperX-Kernmoduls wird diese Datei nicht überschrieben, lediglich sein SQL_ENV.sam im gleichen Verzeichnis. Von dort müssen relevante Änderungen dann in die "richtige" SQL_ENV manuell übernommen werden. Informix- und Postgres-spezifische Variablen sind in dem Kapitel zur Installation und Konfiguration der Datenbankserver beschrieben.
Folgende Variablen sind auf jeden Fall zubelegen:
|
SUPERX_DIR |
Der Installationspfad von SuperX |
|
DATABASE |
Das Datenbanksystem ("POSTGRES" / "INFORMIX") |
|
DBNAME |
Der Name der Datenbank (standardmäßig "superx"). |
|
SX_CLIENT |
Die Clientanwendung (bei Postgres "psql", bei Informix "dbaccess"). Ein client namens "jdbc" ist generisch und dient dem Zugriff auf beliebige DB-Systeme, für die jdbc-Treiber existieren. |
|
MAILPROG |
Das Mailprogramm unter UNIX, z.B. mutt oder mail x ; dies muss sich im PATH des users superx befinden. |
|
LOGMAIL/ERRORMAIL |
Die superx-weite Mailadresse, an die Logdateien von ETL-Scripten geschickt werden. |
|
JAVA_HOME |
Installationspfad der Java-Runtime. Das Unterverzeichnis bin muss in den PATH aufgenommen werden. |
|
JAVA_OPTS |
Java-Runtime-Optionen, z.B. RAM |
|
CATALINA_OPTS |
Tomcat
-Runtime-Optionen, z.B. RAM |
|
DB_PROPERTIES |
Der Pfad zur
DB_PROPERTIES
, standardmäßig
$SUPERX_DIR/webserver/ |
|
EDUSTORE_XML_ GENERATE |
Die edustore.xml wird für Saiku verwendet und beinhaltet die Würfel und Dimensionen, welche angezeigt werden. Bei einem Upgrade kann diese mit allen verfügbaren Daten gefüllt werden. Dafür wird dann diese Variable auf „true“ gesetzt. Bei manueller Anpassung der edustore.xml, diese Variable auf „false“ setzen. |
|
MANDANTID |
Mandantennummer (Hochschulnummer) bei mandantefähigen Installationen |
|
Die folgenden Umgebungsvariablen sind nur für den JDBC-Client sowie für Postgres relevant: |
|
|
LOGGING_PROPERTIES |
Logging-Parameter für den jdbc-Client. Voreingestellt ist "WARNING", mehr Ausgaben erhält man mit "FINE" |
|
PG_HOST |
Name des Postgres-Servers (für Postgres unter Windows) |
|
Die folgenden Umgebungsvariablen werden wahrscheinlich nicht geändert (sollten sie auch nicht): |
|
|
DBDELIMITER |
Standardmäßig "^" |
|
PATH |
Der PATH wird erweitert um das Verzeichnis |
|
JDBC_CLASSPATH |
Der Pfad zu den relevanten jdbc-Treibern und Hilfsprogrammen. |
|
XML_CLASSPATH |
Der Pfad zu den XML-Tools (Xalan, Xerces & co). |
|
FM_DEBUG |
Wenn FM_DEBUG = true gesetzt wird, werden bei Freemarker Scripten von DOSQL die *.tmp.sql-Dateien nicht gelöscht. |
Die Datei sollte unter UNIX in jedem Aufruf der shell "gesourced" werden, z.B. durch den Befehl:
. ~/db/bin/SQL_ENV
(Leerzeichen zwischen Punkt und Tilde!) in der Datei
~/.bashrc
.
Wenn Sie unter Windows den jdbc-Client nutzen, dann müssen Sie die Datei als erstes in der DOS-Shell aufrufen, bzw. in definierten Tasks am Anfang aufrufen.
Die SuperX Shellscripte lassen sich auch in der HISinOne-BI unter Linux nutzen. In der Distribution befindet sich eine Beispiel-SQL_ENV für die Nutzung in HISinOne:
webapps/superx/WEB-INF/conf/edustore/db/bin/SQL_ENV_his1.sam
Der Unterschied ist in der Verzeichnisstruktur: Unter SuperX gibt es den Ordner $SUPERX_DIR, der normalerweise ganz oben liegt, z.B. in /home/superx. Unter HISinOne liegt der Ordner unterhalb der Webanwendung, z.B. in
/var/lib/tomcat7/webapps/superx/WEB-INF/conf/edustore
Weiterhin muss man die Umgebungsvariable WEBAPP umsetzen, z.B.:
SuperX: /home/superx/webserver/tomcat/webapps/superx
HISinOne: /var/lib/tomcat7/webapps/superx
Zum Absetzen beliebiger SQL-Kommandos werden die Befehle DOSQL und DOQUERY genutzt.
Shellvariablen setzen und SQL-Anweisung(en) in der der Datei (als Parameter) in der SuperX-Datenbank ausfuehren.
|
Syntax |
DOSQL "Dateiname mit sql-Anweisung(en)" header (true,false)(optional) Ausgabedatei(optional) |
|
Beispiel |
DOSQL "/home/superx/db/isql/test.sql" false "^" output.txt |
Das Ergebnis kann mit Feldüberschriften (header=true) in eine Datei Ausgabedatei ausgegeben werden.
Wenn FM_DEBUG = true gesetzt wird, werden bei Freemarker Scripten von DOSQL die *.tmp.sql-Dateien nicht gelöscht.
Shellvariablen setzen und eingegebene SQL-Anweisung (als Parameter) in der SuperX-Datenbank ausfuehren.
|
Syntax |
DOQUERY "sql-Anweisung" header (true,false)(optional) Delimiter(optional) Ausgabedatei(optional) |
|
Beispiel |
DOQUERY "select name from userinfo" false "^" output.txt |
Das Ergebnis kann mit Feldüberschriften (header=true) in eine Datei Ausgabedatei ausgegeben werden.
Transformiert eine xml-Datei mit einer übergebenen XSL-Datei und gibt das Ergebnis in einen Ausgabekanal aus (stdout oder Datei). Dabei wird der in SuperX integrierte XML-Parser Xerces und der XML-Prozessor Xalan benutzt.
|
Syntax |
sx_transform.x IN:<xml-Datei> -XSL:<xsl-Datei> -OUT:<Ausgabedatei> -method:<Ausgabeformat (text, xml,html,rtf,pdf)>(optional) <Parameter>(optional) |
|
Beispiel |
sx_transform.x -IN:myxml.xml -XSL:myxsl.xsl -OUT:output.htm -method:html |
Als Parameter kann ein spezielles Ausgabeformat gewählt werden, z.B. TEXT (siehe Xalan-Doku). Bei rtf wird der RTF-Construktor Jfor auferufen, bei pdf wird FOP aufgerufen. Die *.fo-Datei wird nach tmp.fo geschrieben und dann nach pdf transformiert. Wir gehen also nich davon aus, dass .fo-Dateien die Eingabequellse darstellen.
Der PropAdmin ist ein kleines Werkzeug, um den Zugriff auf jdbc-Datenbanken zu testen und die Verbindungsparameter in einer übergebenen properties-Datei zu sichern. Wenn keine graphische Umgebung eingerichtet ist, müssen Sie die alle Verbindungsparameter manuell in die db.properties eintragen. Nur das Passwort kann mit dem propadmin bearbeitet werden.
(Musterdateien für Postgres und Inofrmix liegen vor in
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/db-postgres.properties
bzw.
db-informix.properties
). Wenn als weiterer Parameter kein Dateiname übergeben wird, dann wird die Umgebungsvariable DB_PROPERTIES ausgewertet.
|
Syntax UNIX |
propadmin.x -nogui(optional) <Dateipfad zu db.properties>(optional) |
|
Syntax DOS |
propadmin.bat <Dateipfad zu db.properties>(optional) |
Wenn die Default-Dateiencodierung der aktiven Locale für die Passwort-Verschlüsselung nicht ausreicht, wird eine Fehlermeldung ausgegeben. Unter Windows / DOS ist die Vorbelegung Cp1252 bei deutscher Codepage ausreichend, unter Unix wird die deutsche Locale benötigt.
Ältere Systeme arbeiten in der Regel mit der Zeichencodierung ISO-8859-1 bis ISO-8859-9 . Dieser Zeichensatz wird auch LATIN-1 genannt. Die UNIX-Locale de_DE@euro entspricht z.B. ISO-8859-9 und enthält das EUR-Symbol.
Mit dem Wechsel von ISO-Codierung zu UTF8 bleibt oft der Bedarf bestehen, Dateien hin- und herzucodieren. Seit es, weil beim Entladen aus einer entfernten Datenbank noch das ISO-System genutzt wird, oder bei der Migration eines Systems. Nach unserer Erfahrung sollten Umlaute in Dateinamen unbedingt vermieden werden.
SuperX bietet unter UNIX Shellscripte zur Erfassung und Änderung der Zeichencodierung (Verzeichnis $SUPERX_DIR/db/bin). Im Wesentlichen werden dabei die Unix-Kommandos file und recode genutzt, die Shellscripte machen den Umgang mit umfangreichen Dateilisten komfortabler. Bei der Verarbeitung von Dateilisten sollte man die Scripte sehr vorsichtig einsetzen, es finden keine Sicherheitsüberprüfungen statt.
|
Achtung: nur unter Linux getestet |
Die Scripte wurden bisher nur unter Linux getestet, andere UNIXe wie Solaris und AIX11 verhalten sich ggf. anders als erwartet. Daher bitte mit Vorsicht benutzen. |
Das Script zeigt die Encodierung einer Datei an.
|
Syntax |
sx_show_encoding.x <Datei> |
|
Beispiel |
sx_show_encoding.x $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/web.xml |
|
Ausgabe |
/hopme/superx/webserver/tomcat/webapps/superx/WEB-INF/web.xml: XML ISO |
Das Script nutzt verschiedene UNIX-Tools, je nach System kann die Ausgabe variieren. Bei XML-Dateien wird auch der Dateiinhalt (XML-Header) ausgewertet.
Das Script ändert die Encodierung einer Datei von ISO nach UTF-8:
|
Syntax |
sx_recode_iso2utf.x <Datei> |
|
Beispiel |
sx_recode_iso2utf.x $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/web.xml |
|
Ausgabe |
--keine-- |
Das Script nutzt das UNIX-Kommando recode . Darüberhinaus werden bei XML-Dateien auch die XML-Header "encoding=..." geändert, so wird z.B. aus
<?xml version="1.0" encoding="ISO-8859-1"?>
der Header
<?xml version="1.0" encoding="UTF-8"?>
Andere Inhalte der Datei unterhalb der ersten Zeile werden keinesfalls geändert.
Das Script ändert die Encodierung einer Datei von ISO nach UTF-8:
|
Syntax |
sx_recode_utf2iso.x <Datei> |
|
Beispiel |
sx_recode_utf2iso.x $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/web.xml |
|
Ausgabe |
--keine-- |
Das Script nutzt das UNIX-Kommando recode . Darüberhinaus werden bei XML-Dateien auch die XML-Header "encoding=..." geändert, so wird z.B. aus
<?xml version="1.0" encoding="UTF-8"?>
der Header
<?xml version="1.0" encoding="ISO-8859-1"?>
Andere Inhalte der Datei unterhalb der ersten Zeile werden keinesfalls geändert.
Das Script listet alle ISO-Dateien im übergebenen Verzeichnis auf (inkl. Unterverzeichnisse).
|
Syntax |
sx_list_isofiles.x <Pfad> |
|
Beispiel |
sx_list_isofiles.x webserver/tomcat/webapps/superx/WEB-INF |
|
Ausgabe |
webserver/tomcat/webapps/superx/WEB-INF/lib/LocalStrings_de.properties webserver/tomcat/webapps/superx/WEB-INF/lib/hierhin_den_informix_treiber_kopieren.txt [...] webserver/tomcat/webapps/superx/WEB-INF/db.properties |
Die Ausgabe kann in eine Datei umgeleitet werden, welche wiederum für das Script sx_recode_isofiles.x als Eingabedatei genutzt werden.
sx_list_isofiles.x webserver/tomcat/webapps/superx/WEB-INF >iso.txt
Das Script konvertiert alle Dateien in der übergebenen Dateiliste von ISO nach UTF-8:
|
Syntax |
sx_recode_isofiles.x <Datei> |
|
Beispiel |
sx_list_isofiles.x iso.txt |
|
Ausgabe |
--Keine-- |
Die Eingabedatei ist in der Regel die Ausgabe des Scriptes sx_list_isofiles.x .
Das Script listet alle UTF-8-Dateien im übergebenen Verzeichnis auf (inkl. Unterverzeichnisse).
|
Syntax |
sx_list_utf8files.x <Pfad> |
|
Beispiel |
sx_list_utf8files.x webserver/tomcat/webapps/superx/WEB-INF |
|
Ausgabe |
webserver/tomcat/webapps/superx/WEB-INF/lib/LocalStrings_de.properties webserver/tomcat/webapps/superx/WEB-INF/lib/hierhin_den_informix_treiber_kopieren.txt [...] webserver/tomcat/webapps/superx/WEB-INF/db.properties |
Die Ausgabe kann in eine Datei umgeleitet werden, welche wiederum für das Script sx_recode_utf8files.x als Eingabedatei genutzt werden.
sx_list_isofiles.x webserver/tomcat/webapps/superx/WEB-INF >utf.txt
Das Script konvertiert alle UTF-8 Dateien in der übergebenen Dateiliste von UTF-8 nach ISO:
|
Syntax |
sx_recode_utf8files.x <Datei> |
|
Beispiel |
sx_recode_utf8files.x utf.txt |
|
Ausgabe |
--Keine-- |
Die Eingabedatei ist in der Regel die Ausgabe des Scriptes sx_list_utf8files.x .
In SuperX werden ständig Tabellen erstellt / geladen / entladen. Zu diesem Zweck wurden Shellscripte entwickelt.
Entlädt die Inhalte der Tabelle nach <<Dateiname>>(optional) oder <<name>>.unl
|
Syntax |
sx_unload_table.x <<name>> <<Dateiname>>(optional) |
|
Beispiel |
sx_unload_table.x userinfo |
Löscht die Inhalte der Tabelle <<name>>, und lädt die Inhalte einer Datei in die Tabelle mit sx_upload_records . Wenn kein Dateiname übergeben wurde, wird als Name <<name>>.unl angenommen.
|
Syntax |
sx_upload_table.x <<name>> <<Dateiname>>(optional) |
|
Beispiel |
sx_upload_table.x userinfo |
Lädt die Inhalte einer Datei in die Tabelle, ohne vorherige Inhalte zu löschen. Wenn kein Dateiname übergeben wurde, wird als Name <<name>>.unl angenommen.
|
Syntax |
sx_upload_records.x <<name>> <<Dateiname>>(optional) |
|
Beispiel |
sx_upload_records.x userinfo |
Bei Postgres als DB-System wird eine Java-Klasse ( de.superx.bin.UnlFileConverter ) aufgerufen, die die Unload-Datei entsprechend einer Spezifikation aufbereitet (siehe $SUPERX_DIR/db/conf/unldescr* ).
Wenn der jdbc-Client benutzt wird, können umfangreiche Parameter übergeben werden (Import mit Spaltenüberschriften, Ausgabe von Fehlerprotokollen). Vergleichen Sie die Kommentare im Script.
Entlädt das Schema einer Tabelle in einem vorgegebenen Format.
|
Syntax |
sx_schema.x sx_schema <Tabelle> <format (pg|ids|ansi|xml|HIS))>(optional) <Ausgabedatei> (optional) |
|
Beispiel |
sx_schema.x userinfo ids myschema.sql |
|
Die Formate |
Die Formate sind entweder sql-Scripte für die jeweiligen Datenbanktypen (Postgres, Informix, ANSI), die aus der Umgebungsvariable DATABASE ausgelesen werden, oder xml bzw. ein xml-Format in Anlehnung an die Datenbank-DTD der HIS GmbH. |
Bisherige SuperX-Implementationen sind an den Hochschulen entstanden und haben dementsprechend eine große Vielfalt von Update-Scripten, die jeweils die Vorlieben und Bedingungen der jewieligen Hochschule wiederspiegeln. Daraus ergibt sich für "Neulinge" ein sehr verwirrendes Bild. Außerdem gestaltet sich der Entwurf eines Moduls recht aufwändig, weil die ETL-Funktionen (Extraction -> Transformation -> Loading) manuell programmiert werden müssen. Eine weitere Anforderung ist, daß SuperX auf zwei Datenbankplattformen lauffähig sein muss, Informix und Postgres.
Das Ergebnis ist: SuperX ist (auf Datenbankseite) sehr fehleranfällig, schwer wartbar und praktisch nicht updatebar.
Mit SuperX Version 2.1 wurde die Verwaltung der Module (Installieren / Aktualisieren / sichern und die zugehörogen Logdateien) in zentrale Shellscripte verlagert, die sich ebenfalls in $SUPERX_DIR/db/bin befinden. Die Shellscripte sind dabei nur die operativen "Hüllen" um die eigentlichen SQL-Scripte. Diese wiederum werden zum Teil "von Hand" erzeugt (um z.B. hochschulspezifische Erweiterungen oder Anpassungen vorzunehmen), und zum Teil automatisch aus einer zentralen Steuerdatei ($SUPERX_DIR/db/module/<<Modulname>>/conf/<<Modulname>>.xml ) jeweils für Postgres und Informix erzeugt.
Das Script erzeugt die Installationsdateien für ein Modul, jeweils für Postgres und Informix, nach dem Schema
<<Modulname>>_<<Scriptaktion>>_<<Kürzel für Datenbanksystem>>.sql
Z.B. wird für das BAU-Modul aus der Datei $BAU_PFAD/conf/bau.xml das Script bau_load_pg.sql erzeugt, das die Rohdaten unter Postgres lädt, oder die Datei bau_trans_ids.sql für das Script, das die Bau-Tabellen unter Informix transformiert
|
Syntax |
module_scripts_create.x <<Modulename>> <<Modulpfad>> <<Datenbanksystem(optional)>> <<Versionsnr.(optional)>> |
|
Beispiel |
module_scripts_create.x BAU $BAU_PFAD INFORMIX 1.0 |
Im Grunde handelt es sich um XML-Transformationen. Die Stylesheets für dieses Script befinden sich im Verzeichnis $SUPERX_DIR/db/conf , und die XML-Datei für das Module in $SUPERX_DIR/db/module/<<Modulname>>/conf . Wenn die Datei nicht gefunden wird, bricht das Script ab.
Die folgende Abbildung zeigt die Arbeitsweise:
|
Das Script |
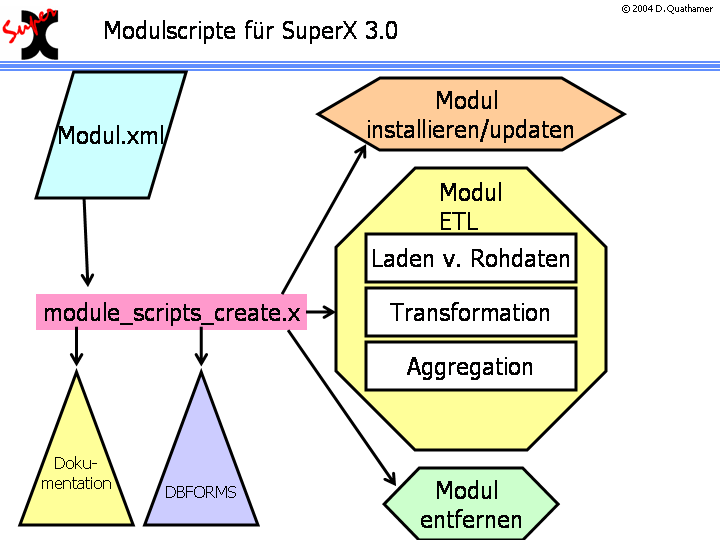
|
Installiert ein Modul <<Modulname>> in der Datenbank, wobei die Installationsdateien sich im <<Modulpfad>> befinden.
|
Syntax |
module_install.x <<Modulename>> <<Modulpfad>> |
|
Beispiel |
module_install.x BAU $BAU_PFAD |
Löscht die Komponenten eines Moduls <<Modulname>> in der Datenbank, wobei die Installationsdateien sich im <<Modulpfad>> befinden.
|
Syntax |
module_drop.x <<Modulename>> <<Modulpfad>> |
|
Beispiel |
module_drop.x BAU $BAU_PFAD |
Das Entladescript lautet
$SUPERX_DIR/db/module/<<Komponentenname>>/rohdaten/<<Komponentenname>>_unload.x.
Die Entladeparameter werden in folgender Datei festgelegt:
$SUPERX_DIR/db/module/<<Komponentenname>>/rohdaten/<<Komponentenname>>_ENV
Entladeroutine bei mandantenfähigen Installationen:
$SUPERX_DIR/db/module/<<Komponentenname>>/rohdaten<<Mandantid>>/<<Komponentenname>>_ENV
Dokumentation zu den jew. Parametern finden Sie in den jeweiligen Administrationshandbüchern der Module. Meist kann man Start-Semester oder -Jahre für das Entladen festlegen. Immer muß man auch das Datenbank-Vorsystem festlegen (Hostname, Kennung etc) sowie, bei HIS-Systemen, die Versionsnummer.
Installiert eine neue Version eines Moduls <<Modulname>> in der Datenbank, wobei die Installationsdateien sich im <<Modulpfad>> befinden.
|
Syntax |
module_update.x <<Modulename>> <<Modulpfad>> |
|
Beispiel |
module_update.x BAU $BAU_PFAD |
Aktualisiert ein Modul <<Modulname>> in der Datenbank, wobei die Installationsdateien sich im <<Modulpfad>> befinden.
|
Syntax |
module_etl.x <<Modulename>> <<Modulpfad>> |
|
Beispiel |
module_etl.x bau $BAU_PFAD |
Die folgende Abbildung zeigt, wie die Komponenten zusammenhängen (klicken Sie auf die Grafik, um sie zu vergrößern):
|
Das Modul wird zunächst nach $MODULPFAD/tmp gesichert, danach werden die Rohdaten geladen, die Daten vorbereitet, transformiert, und nachbereitet. Danach werden die Hilfstabellen erzeugt und, bei erfolgreichem durchlaufen, das Standdatum aktualisiert. |
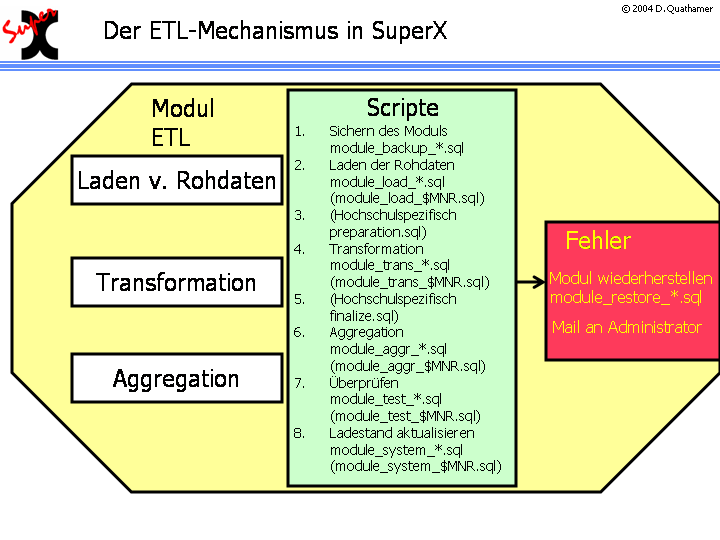
|
Bei Fehlern im ETL-Prozeß wird die Sicherung wiederhergestellt, und eine Mail an den Administrator verschickt. Außerdem werden die übernommenen Daten überprüft; wenn z.B. Schlüssel fehlen oder Rohdaten falsch zu sein scheinen, wird dies als Attachment an die Log- oder Fehlermail angehängt.
In der Praxis wird dieses Script nicht direkt von Cronjobs ausgeführt, sondern von einem Shellscript, das vorher die Umgebung einrichtet. Das folgende Beispiel zeigt das Update-Script für Bau unter Informix:
|
bau_update.x |
#!/bin/sh
. /home/superx/db/bin/SQL_ENV |
Weil Buisy mit "," als Dezimaltrenner arbeitet, wird ausnahmsweise DBMONEY auf "," gesetzt. Außerdem ist es möglich, für jedes Modul unterschiedliche Mailadressen zuzuweisen. Die Mailadressen werden in der SQL_ENV eingetragen.
Im allgemeinen ETL-Prozeß wird standardmäßig auch die Tabelle protokoll in einem festzulegendem Rhythmus (Konstante Löschung Protokoll (Tage) ) gelöscht. Beim Vorgabewert 90 werden bei jeder ETL-Routine Einträge, die älter als 90 Tage sind, gelöscht.
Zusätzlich lassen sich im ETL-Prozeß hochschulspezifische Scripte ausführen (und überwachen). Dazu müssen Dateien mit einem gewissen Namensschema im Stammverzeichnis des Moduls vorhanden sein. Es gibt einen vereinfachten und einen erweiterten Modus für hochschulspezifische Transformationen.
|
Einfacher Modus |
Wenn im Modulpfad die Datei "preparation.sql" existiert, wird sie nach dem LOAD-Schritt ausgeführt. Wenn im Modulpfad die Datei "finalize.sql" existiert, wird sie nach dem TRANS-Schritt ausgeführt.
|
|
Erweiterter Modus: |
Wenn im Modulpfad Dateien nach dem Schema |
Der erweiterte Modus erlaubt die beliebige Anpassung eines Modus an eigene Bedürfnisse, z.B. Schlüsselumsetzung o.ä. Gleichzeitig erlaubt er einen echten mandentenfähigen Betrieb der ETL-Scripte.
Hinweis: bei mandantenfähigen Installationen steht vor der Endung .log immer die MandantID.
Fürs Kernmodul lauten die Dateien bei der Installation:
$SUPERX_DIR/db/install/L_*.log
Beim Upgrade:
$SUPERX_DIR/db/install/upgrade.log
Für alle anderen Komponenten:
$SUPERX_DIR/db/module/<<Komponentenname>>/L_<<Komponentenname>>_<<Installationsschritt>>.log
Für alle Module sind die Dateien wie folgt benannt:
Entladeroutine:
$SUPERX_DIR/db/module/<<Komponentenname>>/rohdaten/<<Komponentenname>>_unload.err
Entladeroutine bei mandantenfähigen Installationen:
$SUPERX_DIR/db/module/<<Komponentenname>>/rohdaten<<Mandantid>>/<<Komponentenname>>_unload.err
Laderoutine:
$SUPERX_DIR/db/module/<<Komponentenname>>/L_<<Komponentenname>>_<<Ladeschritt>>.log
• wobei <<Ladeschritt>> wie folgt aufgebaut ist:
• 1. Unload (Entladen aus Vorsystem)
• 2. Load (CSV-Upload)
• 3. Transformation (Schlüsselharmonisierung, Prüfroutinen)
• 4. Aggregation (Aufbau der Hilfstabellen)
• 5. System (Ladedatum aktualisieren, Datenbank-Wartung)
Wenn die Laderoutine erfolgreich ist, werden alle Schritte hintereinander ausgeführt und geloggt. Wenn nicht, dann wird der jew. Schritt zuende geführt, und dann die Laderoutine gestoppt. Wenn also z.B. beim LOAD ein Fehler auftritt, dann wird der Schritt "Transformation" gar nicht erst begonnen. So ist sichergestellt daß die Auswertungen trotz Fehler laufen.
Da die Laderoutinen oft mit Freemarker Scripten arbeiten, werden diverse SQL-Scripte nur zur Laufzeit generiert und ausgeführt, und danach wieder gelöscht. Um die Laderoutinen transparenter "beobachten" zu können, können Sie die die Löschung der Scripte mit dem Parameter
FM_DEBUG="true"
export FM_DEBUG
Wenn FM_DEBUG = true gesetzt wird, werden bei Freemarker Scripten von DOSQL die *.tmp.sql-Dateien nicht gelöscht. Sie können den Parameter in der aktuellen Shell setzen, oder permanent in der SQL_ENV .
Die Masken-Verwaltung ist detailliert im Entwicklerhandbuch SuperX beschrieben. Hie rnur ein paar Hinweise zur Verwaltung der Masken. Zum Erzeugen und Verändern von Masken gibt es unter UNIX eine Kommandoschnittstelle, die auf dem Gebrauch folgender Skripte beruht. Die Skripte stehen unter dem Verzeichnis
$SUPERX_DIR/db/masken
und erzeugen oder verwenden Dateien in dem gegenwärtigen Arbeitsverzeichnis. Nach dem Einspielen der Datenbank sollten Sie darauf achten, den Dateien Ausführungsberechtigung ( chmod 750 sx_* ) zu geben.
Wenn Sie eine Maske suchen, sollten die die Felder tid oder name in der Tabelle maskeninfo durchsuchen. Das folgende Script macht dies automatisch:
sx_search_mask
|
Aufruf: |
sx_search_mask <String> |
|
Aktion: |
sx_search_mask sucht die Masken, deren Name <String> enthält |
|
Ausgabe: . |
tid, name der gefundenen Masken |
Um eine Maske zu sichern, müssen Sie die entsprechenden Einträge in den Tabellen
1. felderinfo ,
2. masken_felder_bez ,
3. maskeninfo ,
4. sachgeb_maske_bez ,
5. maske_system_bez
selektieren und sichern. Für dies gibt es das Script sx_select_mask .
sx_select_mask
|
Aufruf: |
sx_select_mask <TID> |
|
Aktion: |
sx_select_mask entlädt alle Metadaten aus den Tabellen maskeninfo, felderinfo, masken_felder_bez, sachgeb_maske_bez, maske_system_bez zur Maske mit tid = <TID>. |
|
Ausgabe: |
Fünf Dateien:
|
Um eine Maske neu einzufügen, müssen Sie die entsprechenden Einträge in den Tabellen
1. felderinfo ,
2. masken_felder_bez ,
3. maskeninfo ,
4. sachgeb_maske_bez ,
5. maske_system_bez
einfügen. Dafür gibt es das Script sx_insert_mask .
sx_insert_mask
|
Aufruf: |
sx_insert_mask <TID> [<neue TID>] [j] |
|
Aktion: |
sx_insert_mask lädt den Inhalt der fünf Dateien
in die jeweiligen Tabellen der SuperX-Datenbank. Mit "j" wird die Sicherheitsabfrage umgangen.
|
Falls <neue TID> nicht angegeben wird, werden die Metadaten wieder mit der alten TID in die Datenbank eingespielt (=Update).
Falls <neue TID> angegeben wird, werden die Metadaten mit der neuen TID in die Datenbank eingespielt (=Insert). Dabei werden alle TIDs in den abhängigen Tabellen angepasst. So können Masken sehr einfach kopiert werden. Eine neue TID bekommt man durch die Wahl der nächsten Zehnerzahl, die größer als die größte vorkommende Nummer ist. Die größte vorkommende Nummer erhält man durch Ausführung des folgenden SQL-Ausdrucks mit Hilfe des Kommandos DBACCESS:
select max(tid) from maskeninfo;
|
! |
Um den Austausch von Abfragen innerhalb der Hochschulen zu erleichtern ("
Abfragen-Pooling
" über die SuperX-Website), sollten die Masken immer im Nummernkreis xxxx0000 bis xxxx9990 liegen, wobei xxxx der von der HIS verwandten Hochschulnummer entspricht. Die Zehnerschritte ergeben sich daraus, dass die dazwischen liegenden Nummern für die Maskenfelder (Tabelle
felderinfo
) reserviert sind
14
.
|
Wie im Abschnitt Userverwaltung beschrieben, kann die neue Maske Benutzern oder Gruppen zugänglich gemacht werden.
Um eine Maske zu löschen, müssen Sie die Einträge in den oben genannten Tabellen entfernen. Dafür gibt es das Script sx_delete_mask
sx_delete_mask
|
Aufruf: |
sx_delete_mask <TID> |
|
Aktion: |
sx_delete_mask löscht alle Metadaten aus den Tabellen maskeninfo , felderinfo , masken_felder_bez , sachgeb_maske_bez und maske_system_bez zur Maske mit tid = <TID>. |
1. Selektieren der Metadaten der betreffenden Maske: sx_select_mask <TID>
2. Editieren der fünf Metadaten-Dateien ,,<TID>_..."
3. Abspeichern der neuen Metadaten: sx_insert_mask <TID>
Neben der Ausführung im Browser gibt es eine "Kommandozeilenversion" des Aufrufs: sx_jasper.x
|
Aufruf: |
sx_jasper.x -JRXML:<JRXML-Datei> -XML:<Datei mit XML-Datenquelle> -db_properties:Pfad_zur_db.properties -IGNORE_PAGINATION:<true oder false> und optional -JASPER:<Jasper-Datei> -JRPRINT:<Jrprint-Datei> -OUT:<Ausgabedatei> |
|
Aktion: |
sx_jasper.x führt einen JasperReports-Task aus. Die Datenquelle kann entweder xml sein (Parameter -XML), oder eine Datenbankverbindung in der Datei db.properties. Das Ergebnis wird in eine Datei <Ausgabedatei> ausgegeben. Wenn keine Ausgabedatei angegeben wird, wird der jrxml-Dateiname verwendet, und eine PDF-Ausgabe erzeugt. |
Neben der Ausführung im Browser gibt es eine "Kommandozeilenversion" des Aufrufs: sx_transform.x
|
Aufruf: |
sx_transform.x -IN:<xml-Datei> -XSL:<xsl-Datei> -OUT:<Ausgabedatei> -method:<Ausgabeformat (text,xml,html,pdf,rtf)>(optional) -param:<Parameter>(optional) |
|
Aktion: |
sx_transform.x transformiert eine XMl-Datei via XSL. Wenn pdf als Ausgabeformat angegeben ist, dann wird eine PDF-Datei erzeugt. |
Die Masken des XMl-Frontends erscheinen bei der Anmeldung von Benutzern, die Administratorrechte haben (z.B. voreingestellte User
superx
und
admin
).
aufruft. Nach der Anmeldung erscheint die folgender Themenbaum:
http://rechnername:8080/superx/xml/
|
im XML-Frontend
|
|
Nach Anklicken eines Unterpunkts (wie Institution suchen) erscheint auf der rechten Seite ein Dialog zur Suche des jeweiligen Eintrags.
Meist wird das Organigramm aus anderen HIS-Systemen gefüllt, z.B. HISCOB. Wenn die Hochschule das Organigramm allerdigns selbst pflegt, gibt es die Möglichkeit, die Einsträge in einem einfachen Browser-Formular zu bearbeiten. Wenn man den Punkt Institution suchen anklickt und das Formular abschickt, erscheint z.B. folgendes Bild:
|
Ohne Einschränkung werden alle Institutionen im Organigramm angezeigt. |
|
|
Die Bearbeitungsmaske ermöglicht die Änderung der Bezeichnung (Drucktext wird normalerweise nicht angezeigt) und der übergeordneten Institution ("Parent") sowie der Gültigkeit. |
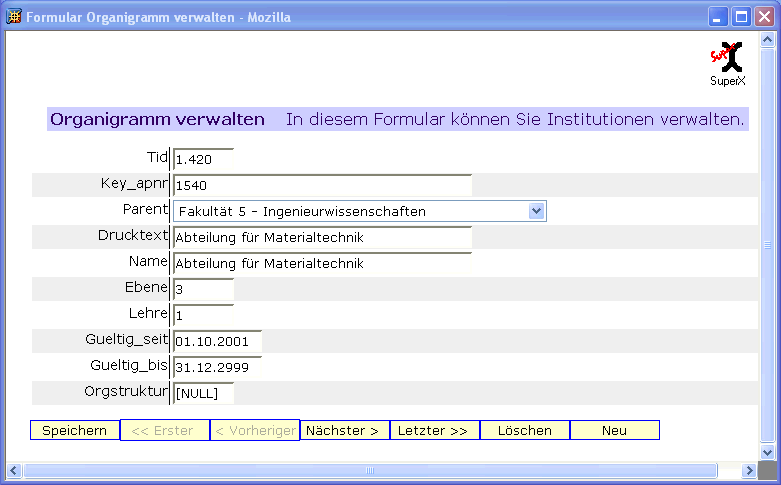
|
Hier kann man nun den Namen, Drucktext, die Key-Apnr, Ebene, das Lehrekennzeichen, ggfs. Kennzeichen Orgstruktur und den Gültigkeitszeitraum bearbeiten.
Wenn man den Button Neu anklickt, erscheint der gleiche Dialog, bei dem man den Namen, key-apnr etc. der neuen Organisationseinheit eingeben kann.
Anklicken des löschen -Buttons entfernt eine Organisationseinheit aus dem Organigramm.
Wenn eine Organisationseinheit verschoben werden soll, z.B. Philosophie von Fachbereich 1 nach Fachbereich 6, geht dies über die Zuweisung des "Eltern"-Elements.
Wenn Sie alle Änderungen gemacht haben, können Sie diese durch Anklicken des speichern -Buttons in die Datenbank übernehmen.
Wenn man den Punkt Themenbaum-Eintrag suchen anklickt und das Formular abschickt, erscheint z.B. folgendes Bild:
|
Es erscheint eine Liste mit Einträgen im Themenbaum. Sie können jeden Eintrag bearbeiten. |
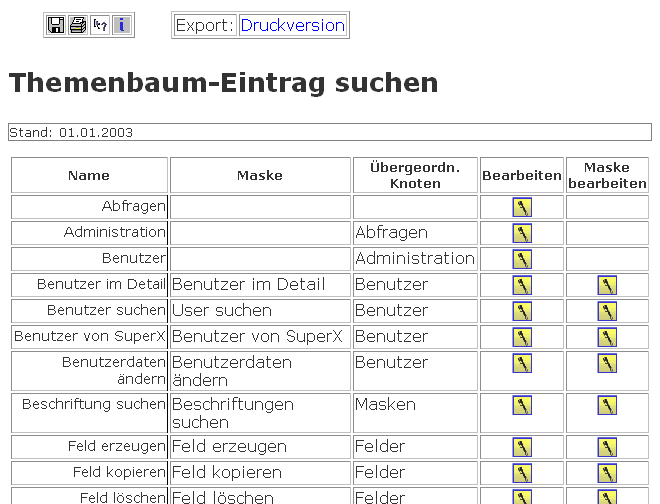
|
|
Das folgende Bild zeigt die Bearbeitungsmaske. Es können Bezeichnungstexte und übergeordnete Elemente geändert werden. Beachten Sie, dass nach jeder Änderung in der jeweiligen Spalte rechts auf "Speichern" geklickt werden muss. |
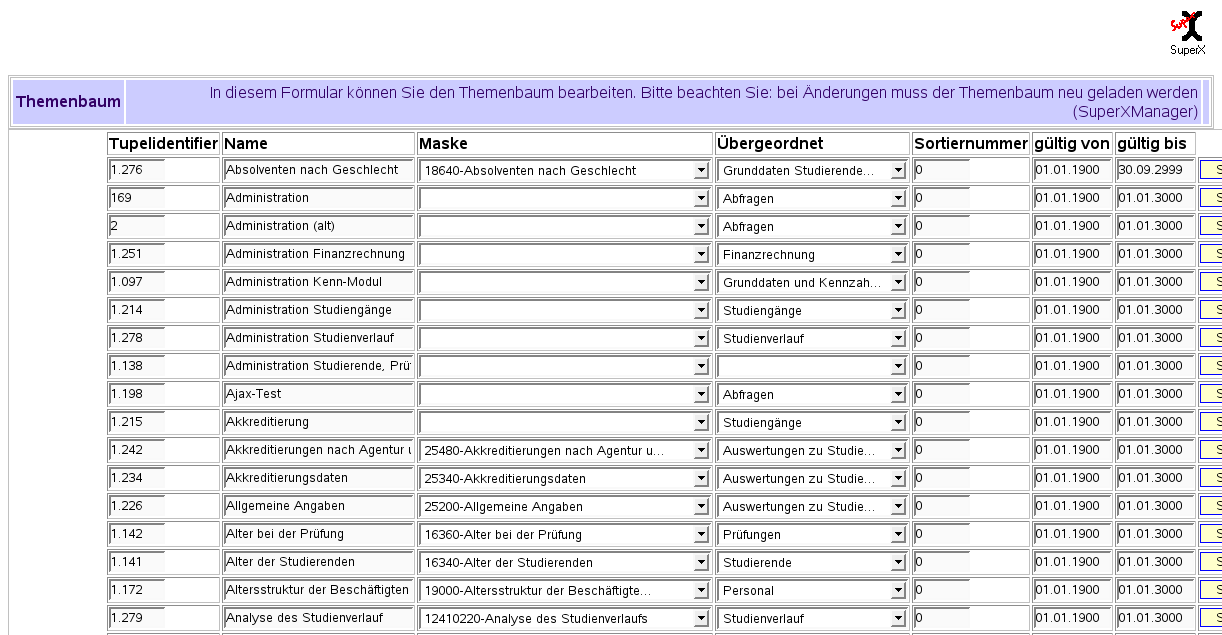
|
Die Bezeichnungen von Maksen werden hier nicht vorgenommen, sondern nur in der Tabelle maskeninfo.
Ein Eintrag kann in der jeweiligen Zeile durch Anklicken von löschen entfernt werden.
Wenn Sie eine neue Kategorie wie Administration, Studierende oder Haushalt oder neue Masken einhängen wollen, wählen Sie unten Neu .
Neu seit Kernmodul3.5rc2 ist die Spalte sort sort . Diese ermöglicht eine andere als die alphabetische Sortierung, die der Standard ist. Sie können Sie mittels Formular oder auch direkt in der Datenbank bearbeiten.
Ein Beispiel für eine nicht-alphabetische Sortierung
|
Themenbaumknoten |
sortnr |
|
Personal, Stellen |
1000 |
|
Studierende, Prüfungen |
2000 |
|
Finanzrechnung |
3000 |
|
Kostenrechnung |
4000 |
Innerhalb einzelner Knoten wird wieder alphabetisch sortiert. Wenn Sie aber z.B. Abfragen unter Kostenrechnung anders sortieren möchten, könnten Sie Sortiernummern von 4001 bis 4999 nutzen.
(Intern wird zuerst nach sortnummer und dann nach der Bezeichnung sortiert, wobei die Hierarchie im Baum aber bewahrt bleibt.)
Tipp: Um Einträge im Themenbaum unsichtbar zu machen, besteht der einfachste Weg darin, ihr Gültigkeitsdatum (gültig bis) auf einen Wert kleiner als heute zu setzen.
Ab Kernmodul 4.7 lassen sich Themenbaum-Knoten auch mit Icons versehen. In der CSS-Klasse können Sie Iconf-fonts zuweisen.
Bei „HTML CSS class“ dazu einfach „icon“ + Leerzeiche + gewünschtes Icon-font eintragen. Beispiel: „icon icon-magic“.
Welche Icons zur Verfügung stehen und welcher Code dafür eingegeben werden muss erfahren Sie auf Ihrem SuperX Server unter <<Server-Adresse>>/superx/xml/fonts.html.
In SuperX lassen sich User- und Gruppenrechte komfortabel durch das XML-Frontend einrichten. Ausführliche Informationen zu den Tabellen und Relationen finden Sie im Kapitel Userverwaltung .
Wenn Sie im Bereich Administration den Bereich Benutzer wählen, sehen Sie folgende Oberfläche:
|
Themenbaum-Menü zur Userverwaltung |
|
Wenn Sie einen neuen Benutzer einrichten wollen, klicken Sie auf User einrichten . Anschließend werden Sie nach Angaben zur Kennung für den neuen Benutzer gefragt:
|
Die User-tid wird automatisch hochgezählt. Die Benutzerkennung ist der Login-Text, und eine Gruppe kann ausgewählt werden. Der Name der Person muss angegeben werden. Wenn Sie das Feld "Inst-Rechte" leer lassen, hat der User Rechte auf alle Institutionen. |

|
Die Gültigkeit kann ebenfalls eingeschränkt werden. Das Klappmenü "nur Lehre" wird bei den Orgranigramm-Rechten ausgewertet (obsolet mit 3.0).
Klicken Sie zum Abschluss auf "Abschicken". Der Benutzer wird dann mit dem verschlüsselten Passwort angelegt.
|
Wenn Sie einen Benutzer löschen wollen, wählen Sie im Themenbaum die Abfrage "User löschen" und dort die Kennung in der Combobox. |
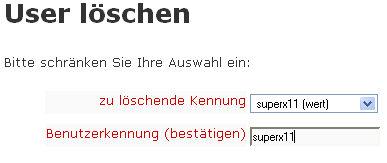
|
Bestätigen Sie Ihre Auswahl einmal, indem Sie die Kennung eintippen.
Im Formular User suchen erhalten Sie je nach Einschränkung eine Liste mit Benutzern.
|
Wir schränken z.B. ein auf die Gruppe Administratoren. |
|
|
Es erscheinen zwei User, die voreingestellten Administratoren. Sie können sich Details zur Person ansehen, oder die Person bearbeiten. |
|
|
In der Bearbeitungsmaske können Sie Kennung und Namen ändern, sowie das Passwort ändern. Danach müssen Sie oben rechts auf die Diskette zum Speichern klicken. |
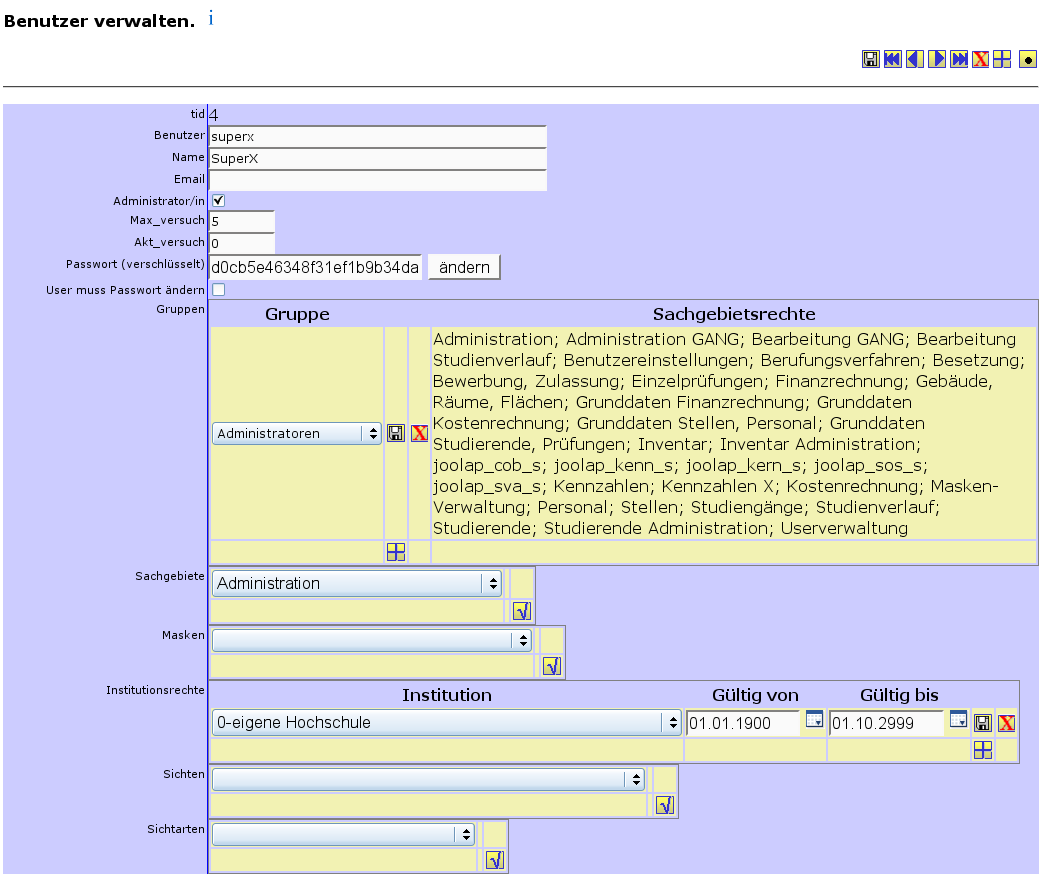
|
Bei den Gruppen, Sachgebiete, Masken, Institutionen, Sichten und Sichtarten handelt es sich um Unterformulare, d.h. Sie brauchen Änderungen hier nicht mit dem Diskettensymbol oben rechts zu speichern.
Das Häkchen Administrator/in hat keinen Effekt auf die sichtbaren Sachgebiete und Masken im Themenbaum. Es bewirkt folgendes:
• Leserecht für alle Sichten
• Ausführungsrecht für Administrationsmasken im Kernmodul, z.B. User löschen
• Recht, im SuperXManager den Cache zu leeren und die SQL-Protokollierung anzuzeigen
• Recht, JasperReports-Templates zu generieren (erst ab Kernmodul 4.0rc2, oder HISinOne 2.0)
• Leserechte für alle Bäume und Würfel in Joolap
Für die Gruppen Administratoren und Bearbeiter musste bei Einsatz des SuperX-Kernmoduls 3.0 immer das Häkchen bei "Administration" gesetzt werden, denn nur diese Personen durften im Kernmodul 3.0 die DBForms überhaupt nutzen. Im Kernmodul 3.5 oder höher ist dies nicht mehr notwendig, da reicht es aus wenn die User der Gruppe "Administratoren" (Name darf nicht geändert werden) angehören, bzw. im GANG-Modul den Gruppen GANG Bearbeiter oder GANG Administratoren .
Wenn Sie einen Gastzugang ermöglichen wollen, tragen Sie für eine beliebige Userkennung (z.B. public, gast, anonym o.ä) über die Benutzerverwaltung das Passwort „notsecret“ (ohne Anführungszeichen) ein. Das Passwort wird verschlüsselt in der Datenbanktabelle „userinfo.passwd_sha“ abgelegt.
Sie können dann Links wie z.B.
http://localhost:8080/superx/servlet/SuperXmlTabelle?tid=71190&navi=true&kennung=public
erstellen, die Authentifizierung erfolgt mit dem internen Passwort „notsecret“.
Falls Sie sonst standardmäßig LDAP für die Anmeldung verwenden, können Sie ab kern4.9.1 den Parameter login=superx ergänzen, dann erfolgt die Anmeldung nicht über LDAP, sondern eben mit „notsecret“ gegen die SuperX-Datenbanktabelle userinfo. Beispiel:
http://localhost:8080/superx/servlet/SuperXmlTabelle?tid=71190&navi=true&kennung=public&login=superx
Der Aufruf des normalen Themenbaums für Gastuser ist auch möglich mit,z.B.
http://localhost:8080/superx/servlet/SuperXmlAnmeldung?kennung=public
Im Bereich Gruppenverwaltung erhält man die Möglichkeit, Gruppen zu löschen, neue Gruppen anzulegen und Stammdaten zu ändern.
Wenn man eine neue Gruppe einrichten will, wählt man im Menü Administration->Benutzer->Gruppe einrichten .
|
Sie können eine Nummer vergeben, den Namen festlegen (darf nicht bereits existieren), die zugehörigen Mitglieder auswählen, und Rechte für Sachgebiete und Masken vergeben. In den Listen sind auch mehrere Einträge auswählbar, jeweils mit der Taste "Strg" und einem Mausklick (beim Mac die Apfel-Taste). |
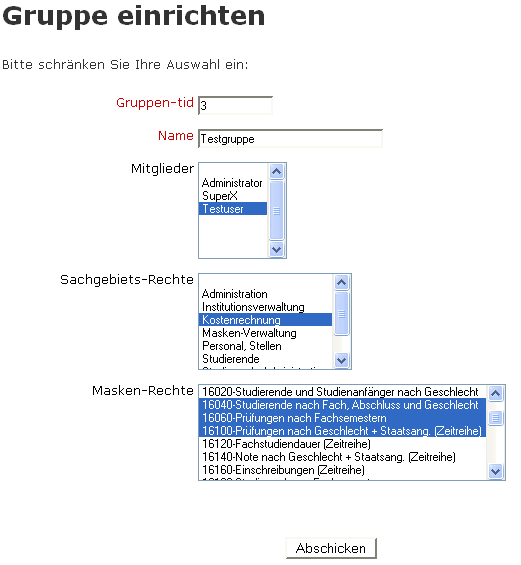
|
Sie können auch direkt im Tabellenformular arbeiten, im Menü "Tabelle suchen"-> Tabelle groupinfo .
|
Hier können Sie Gruppenbezeichnungen ändern, Gruppen löschen (Vorsicht!) und neu anlegen. |
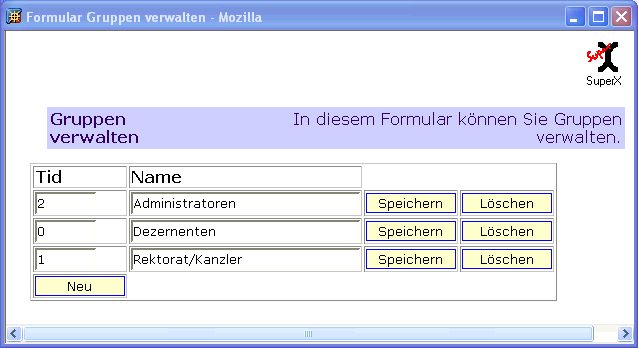
|
Im Formular Gruppe suchen erhalten Sie je nach Einschränkung eine Liste mit Gruppen.
|
Wir schränken z.B. ein auf die Gruppe(n) des Users superx . |
|
|
Es erscheint ein Eintrag mit der Gruppe Administratoren, die zwei User enthält. Sie können die Gruppe bearbeiten. |
|
|
In der Bearbeitungsmaske können Sie den Namen der Gruppe ändern. Danach müssen Sie unten "Speichern" anklicken. |
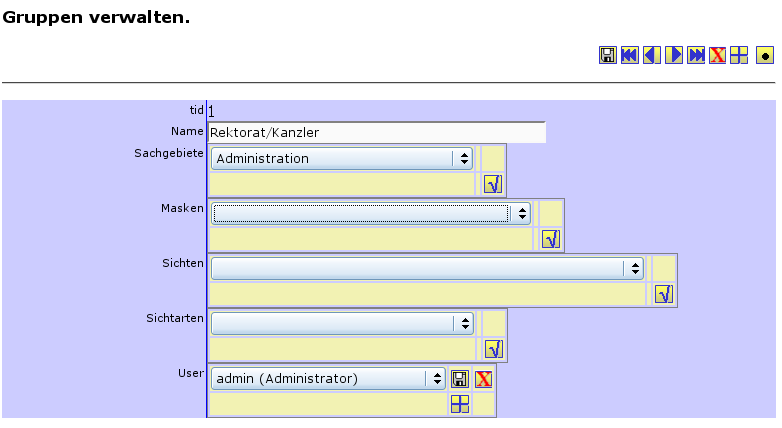
|
Bei den Gruppen, Masken, Sichten, Sichtarten und Usern handelt es sich um Unterformulare, d.h. Sie brauchen Änderungen hier nicht mit dem Diskettensymbol oben rechts zu speichern.
Im XML-Frontend im Menü Administration -> Benutzer -> Gruppe löschen können Sie eine Gruppe löschen und die jeweiligen Rechte für Sachgebiete und Masken entfernen. Auch die Zuordnungen von Usern zur Gruppe (nicht aber die User selbst) werden gelöscht.
|
Sie müssen lediglich den Namen der Gruppe auswählen und einmal zur Sicherheit bestätigen, indem Sie den Namen eintippen. |

|
Einzelne Berichte/Masken Benutzern oder Gruppen zuzuordnen verschafft mehr Kontrolle als die Berichte über Sachgebietsrechte zu vergeben. Dabei muss aber beachtet werden, dass eventuelle Rechte auf Sichten extra vergeben werden müssen und ist damit auch etwas aufwendiger.
Wenn Sie einen Bericht frei geben, rufen Sie diesen als Administrator ein mal auf. Die Auswahlfelder, welche als Buttons angezeigt werden können Sichten sein. Z.B. in dem Bericht „Alter der Studierenden“ die Buttons Studiengang, Fächer und Abschluss.
Wenn Sie auf einen Button wie Studiengang klicken, sehen Sie in der Box oben, dass Sie die Sicht ändern können. Dies ist daher ein Button der Rechte auf eine Sicht benötigt. Das gleiche auch bei dem Button Fächer.
Bei dem Button Abschluss fehlt die Auswahl der Sicht. Dies ist nur eine Liste und keine Sicht.
Sie müssen also für die Buttons Studiengang und Fächer dem Benutzer, dem Sie explizit diese Maske zuordnen rechte auf die verwendeten Sichten geben. Wenn Sie unter Administration → Masken → Felder → Feld suchen bei „Feld der Maske“ „Alter der Studierenden“ raus suchen und abschicken, Sehen Sie die Felder der Maske „Alter der Studierenden“.

Klicken Sie hier jeweils für Studiengang und Fächer auf Bearbeiten. In dem neuen Fenster sehen Sie unter „Relation“ den verwendeten SQL und auch die Sichtarten.
Sie müssen dem Benutzer auf mindestens eine Sicht oder besser noch auf die ganze Sichtart das Recht vergeben.
Wie unter Maskenrechte vergeben beschrieben, können Sie die benötigten Sichtarten für Masken herausfinden. Sie können nun einfach die Sichtart in dem entsprechenden Berechtigungsfeld raus suchen und dazu das Recht vergeben. Sie können aber auch nur das Recht auf eine spezielle Sicht dieser Sichtart vergeben. Um heraus zu finden welche Sichten sich hinter einer Sichtart verstecken gehen Sie auf Administration → Masken → Sicht suchen. Dort wählen Sie die Sichtart aus und klicken auf Abschicken.
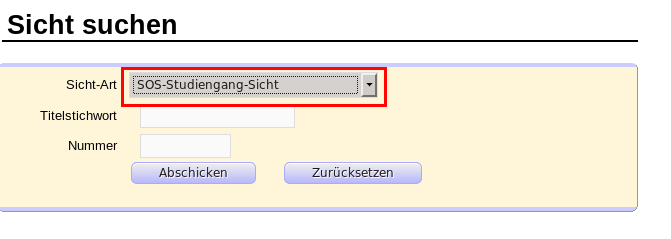
Die Ergebnistabelle zeigt alle Sichten der angegebenen Sichtart an.
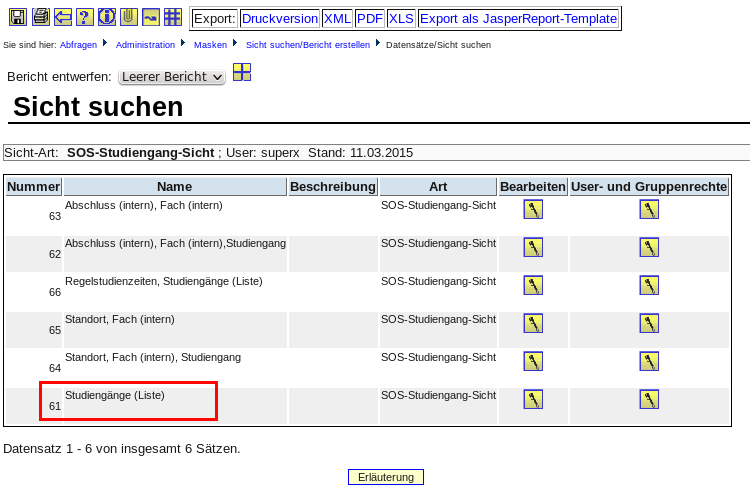
Sie können daraus nun auch speziell eine Sicht aussuchen und in der Rechtevergabe das Rechte auf eine einzelne Sichten vergeben. Dazu merken Sie sich einfach die Nummer. Das hat dann den Effekt, dass in manchen Berichten im Ergebnis nach dem Baum dieser Sicht aufgebaut wird.
Unter der Benutzer Info befinden sich Berichte, die ausführliche Informationen für die Benutzer und Gruppenverwaltung ausgeben.
In diesem Bericht erfahren Sie auf welche Berichte bestimmte Benutzer zugreifen dürfen. Es werden auch Berichte angezeigt, welche über Gruppen- oder Sachgebietsrechte erteilt worden sind.
In dem Bericht können Sie ein oder mehrere Benutzer wählen und bei bedarf die Ausgabe auf eine Gruppe und/oder ein Sachgebiet begrenzen.
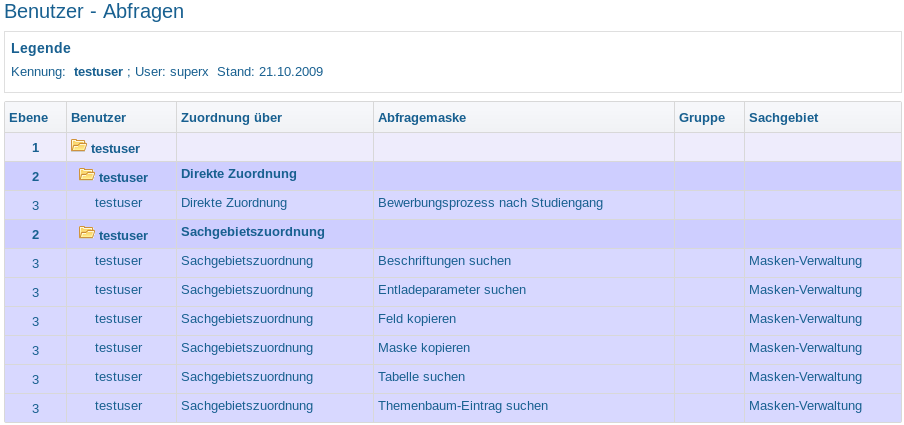
So würde dann z.B. das Ergebnis aussehen. Dem testuser aus diesem Beispiel wurde ein Bericht direkt zugeordnet und hat Rechte auf 6 weitere über das Sachgebiet Masken-Verwaltung. Wie Sie sehen erfahren Sie hier die Berechtigungen der Benutzer auf Berichte recht einfach und Übersichtlich.
In diesem Bericht erfahren Sie welche Institutionsrechte die Benutzer haben.
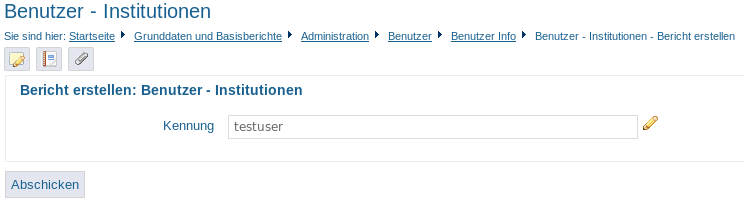
In dem Bericht gibt es nur die Auswahl des Benutzers.

Als Ergebnis erhalten Sie alle Institutionen auf die der Benutzer Rechte besitzt.
In diesem Bericht erfahren Sie auf welche Sichten die Benutzer Rechte haben.
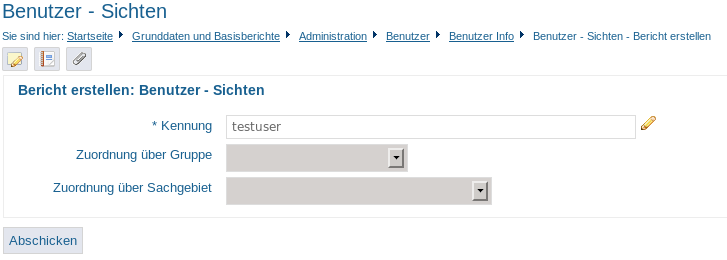
In dem Bericht können Sie ein oder mehrere Benutzer wählen und bei bedarf die Ausgabe auf eine Gruppe und/oder ein Sachgebiet begrenzen.
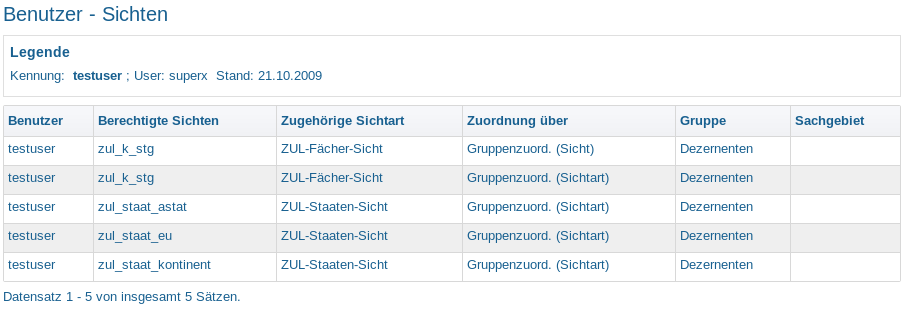
Als Ergebnis erhalten Sie alle Sichten auf die der Benutzer Rechte besitzt.
In diesem Bericht können Sie in Erfahrung bringen, in welchen Gruppen ein Benutzer ist oder welche Benutzer in einer Gruppe ist. In dem folgenden Beispiel wurde eine Gruppe gewählt und es wird nach den zugeordneten Benutzern gesucht.
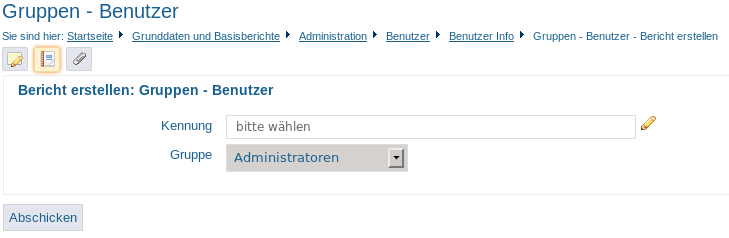
Als Ergebnis erhalten Sie dann die Zuordnung Gruppe – Benutzer.
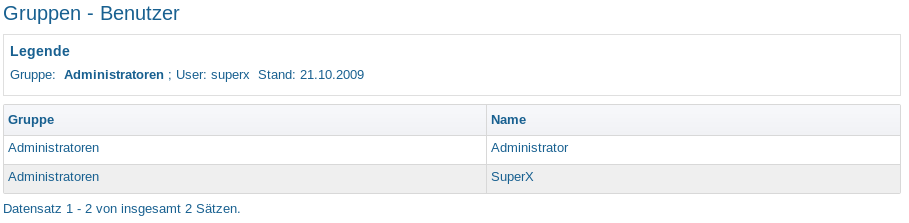
In diesem Bericht werden die Sachgebiete aufgelistet, dessen Rechte einer Gruppe zugeordnet wurden.
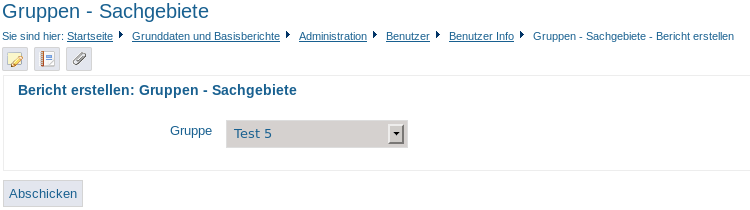
Als Ausgabe erhalten Sie eine Tabelle mit Gruppe – Sachgebiet.
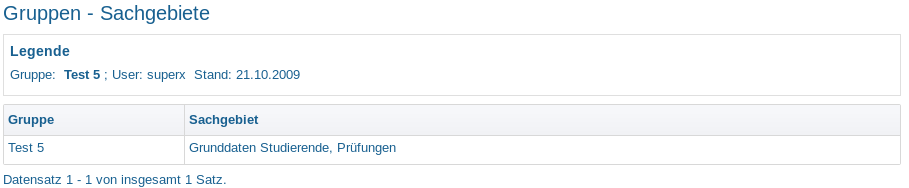
Die DBFORMS dienen der Dateneingabe in SuperX, z.B. für die Konfiguration. Alle DBFORMS lassen sich direkt aus einer Maske aufrufen und sind daher nur für die Personen sichtbar, die auch das jeweilige Maskenrecht haben.
Wenn die User das Recht auf das Sachgebiet des jeweiligen DBFORMS haben (Tabelle sachgeb_dbform_bez ), bekommen sie Leserecht, sofern das DBFORM "stand-alone" arbeitet, d.h. nicht mit Pflichtparameter aus einer Maske aufgerufen wird, sondern direkt über die Maske "Tabelle suchen".
Wenn die User einer Gruppe zugeordnet sind, die Rechte auf Sachgebiete mit dem Namen "Administration*" oder "Bearbeitung*" haben, bzw. wenn sie als Einzeluser Recht auf ein solches Sachgebiet haben, bzw. wenn sie das Admin-Häkchen haben, bekommen sie auch Schreibrecht (Daten einfügen, löschen, neu erzeugen). Beim Modul GANG sind das z.B. die Sachgebiete "Administration GANG" und "Bearbeitung GANG".
In fast jedem SuperX-Modul gibt es die Möglichkeit, hochschuleigene Filter anzulegen. Die Maskenfelder dazu lauten "Filter Studierende", "Filter Personal" etc. Hier ein Beispiel:
|
Der Button "Filter Studierende": |
|
Hinter dem Namen des Filters verbirgt sich eine SQL-where-Bedingung. Die Bedingung wird vor dem Hintergrund der jeweiligen Hilfstabelle formuliert, hier z.B. die Hilfstabelle "Studierende" im SOS-Modul. Die zugehörige Tabelle finden Sie auf der Seite der Datenbankbeschreibung des Moduls, hier z.B.
http://www.studio-fuer-textdesign.de/superx/doku/sos_modul/sos.html
Dort schauen Sie rechts in der Spalte "Hilfstabellen", welche Tabellen es gibt. Die gesuchte Tabelle lautet sos_stg_aggr
http://www.studio-fuer-textdesign.de/superx/doku/sos_modul/sos.html#tab_sos_stg_aggr
Wenn Sie z.B. einen Filter "nur weibliche Studierende"erzeugen wollen, wählen Sie zunächst im Maskenfeld "Geschlecht den gewünschten Wert:



Der Wert für weiblich ist "2". Dann wäre die Bedingung:
|
Filter "nur weiblich" |
geschlecht=2 |
Den Inhalt des Filters können Sie in der Tabelle "Hochschul-Repository" einpflegen: Gehen Sie im Browser in das Menü "Administration->Tabelle suchen", geben Sie beim Stichwort "repository" ein, und klicken Sie auf "Suchen". Sie erhalten einen Datensatz :
Hier klicken Sie auf "Bearbeiten". Sie erhalten ein Datenbankformular, wo Sie rechts nach Variablen suchen können. Am besten suchen Sie eine Variable, die es schon gibt, indem Sie den Modulnamen eingeben, z.B. hier "SOS". Sie erhalten verschiedene Beispielfilter, allen ist gemeinsam, daß sie im Feld "Art der Variable" den Wert "SOS_STUD_FILTER" haben. Wenn Sie einen neuen Filter eingeben wollen, gehen Sie unten auf den Button "Neu". Dann geben Sie die Werte ein:
|
Vergeben Sie einen eindeutigen Namen, z.B. "SOS_nur_weib", im Feld "Inhalt" schreiben sie die where Bedingung, und die Beschriftung erscheint dann in der Maske. Wichtig ist der Wert bei "Art der Variable", das Sachgebiet, der Schalter "Aktiv", und die Gültigkeit. Wenn Sie das Formular mit "Einfügen" abschicken, erscheint wieder die komplette Liste, der Datensatz ist am Ende angefügt. |
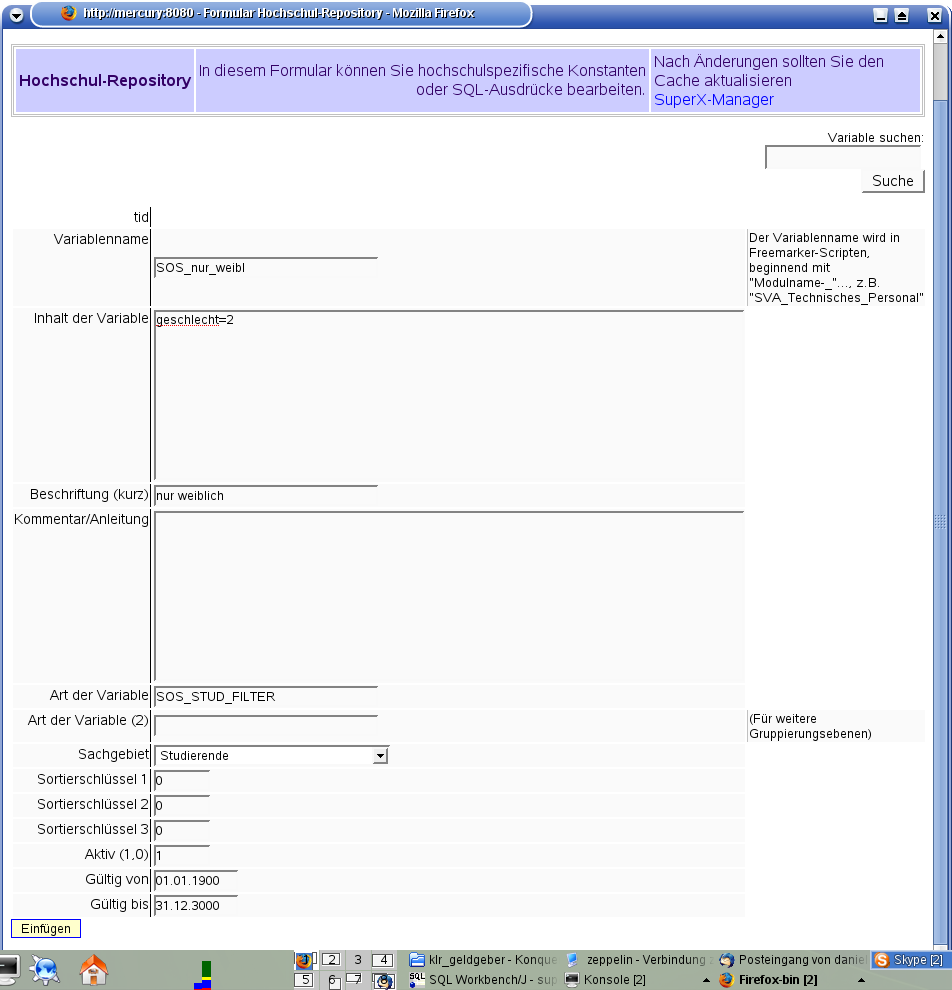
|
Danach gehen Sie im Manager auf Cache leeren, und öffnen eine Studierenden Maske erneut:
|
Der Filter ist nun sichtbar und nutzbar - in allen Masken zu Studierenden. |

|
Sie können auch komplexere Filter einbauen, z.B. "nur Haupthörer, ohne 1. Hochschulsem., ausl. Staatsangehörigkeit", indem Sie die where-Bedingungen mit "and" verknüpfen. Achten Sie bei der Syntax darauf, dass die SQL-Syntax nicht zerstört wird. Bei alphanumerischen Feldern müssen Sie z.B. immer ein einfaches Hochkomma um die Werte setzen.
Die Access-Datenbank enthält die Tabellen des Kernmoduls als Verknüpfungen und ermöglicht so ein leichtes Administrieren der Datenbank. Die Installation ist in der Installationsanleitung für ODBC-Quellen beschrieben. Die folgende Abbildung zeigt das Hauptmenü:
|
Das Frontend eignet sich zur Verwaltung von Usern, Gruppen, Sachgebieten und Masken sowie deren relationalen Verküpfungen (blaue Linien). Darüberhinaus sind Formulare für das Systeminfo, den Themenbaum und das Organigramm vorgesehen. |
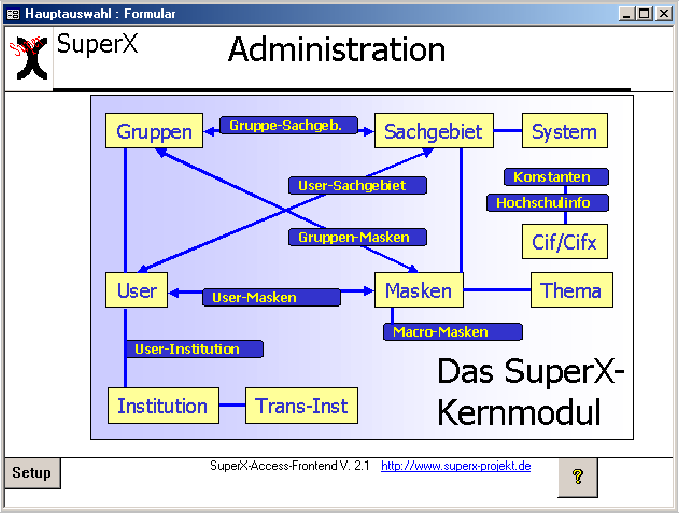
|
Probleme mit der Bedienung von Access gibt es immer dann, wenn Tabellen keine Primärschlüssel haben oder wenn die Felder mit den Primärschlüsseln nicht gefüllt sind. Mit der Version 2.1 erhalten alle Tabellen in SuperX (außer Datentabellen und Hilfstabellen, weil diese normal nicht manuell bearbeitet werden) Primärschlüssel. Wenn ein Access-Dialog nach Primärschlüsseln fragt, nehmen Sie im Zweifelsfall alle Spalten, die jeweils angeboten werden. Ansonsten empfehlen wir die Java-basierte SQLWorkbench .
Das Access-Frontend ist insbesondere für die Änderung von Masken und Feldern gut geeignet.
Durch die odbc- und jdbc-Treiber können beliebige Datenbankfrontends eingesetzt werden. Gute Erfahrungen gerade mit Tabellen ohne Primärschlüssel haben wir mit der SQLWorkbench von Thomas Kellerer gemacht. Exemplarisch für andere jdbc-Clients haben wir dieses Programm näher beschrieben.
Die SQLWorkbench von Thomas Kellerer arbeitet mit dem jdbc-Treiber jeweils von Postgres oder Informix. Beim ersten Aufruf der Workbench können Sie Profile für Treiber und Datenbanken eingeben. Musterprofile für viele gängige Datenbanksysteme liegen vor. Leider ist der Informix-Treiber nicht dabei, deshalb muss dieser "von Hand" registriert werden. Gehen Sie dazu über File->Connect in das Feld "Manage Drivers". Dort können Sie einen Namen vergeben und die jdbc-Parameter übertragen. Die folgende Abbildung zeigt ein Beispiel:
|
Der Dialog zur Einrichtung von Datenbanktreibern am Beispiel Informix. |
|
Im Dialog File -> Connect können Sie dann eine Datenquelle eintragen, und die Verbindungsparameter vervollständigen (Username, Passwort). Autocommit sollten Sie immer einschalten.
Die SQLWorkbench ist ein hervorragendes Administrations- und Entwicklungswerkzeug, daher haben wir die Version 94 in das SuperX-Clientpaket 30final integriert. Darin sind die Profile und Treibereinstellungen für Informix, Postgres und Joolap bereits voreingestellt, Sie müssen lediglich Servernamen und Ports ändern.
Achtung bei Postgres
: Beim Verbinden mit Postgres Datenbanken müssen Sie im Verbindungsprofil das Häkchen bei "Autocommit" setzen - sonst werden Datenbankänderungen nicht automatisch committed.
Und für Postgres 10 oder höher gilt:
Damit die Workbench richtig funktioniert müssen Sie den aktuellen JDBC-Treiber von
https://jdbc.postgresql.org/
einbinden
(im Dialog Datenbank verbinden -> Manage Drivers.
Interessant ist der Datenbank-Explorer (Tools -> Database Explorer), der es ermöglicht, die Datenbank nach Tabellen / Prozeduren etc. zu durchsuchen. Wenn eine Tabelle ausgewählt ist, kann sie auch über die Registerkarte "Data" editiert werden. Achten Sie darauf, dass Sie das Feld Max. Rows auf einen sinnvollen Wert setzen, z.B. 2000. Die SQLWorkbench ist gerade für die Arbeit mit Tabellen ohne Primärschlüssel geeignet, weil jede Äderung intern als Update formuliert wird. Der Nachteil ist, dass nicht mehrere Zellen über Zwischenablage geändert / eingefügt werden können.
Sehr praktisch für die Entwicklung von SQL-Abfragen ist die Möglichkeit, zu jeder Tabelle einen select-String zu formulieren.
|
Markieren Sie die Tabelle im Database Explorer, und gehen Sie über das Kontextmenü auf Show table data, und wählen Sie ein Editorfenster aus. Der Select-String wird dann angezeigt. |
|
Seit den Versionen 93 lassen sich bei Informix auch Felder vom Typ text anzeigen und editieren.
Das Tool bietet außerdem eine Makrofunktion, und in neueren Versionen auch ETL-Funktionen über einen "Data Pumper", was es natürlich für SuperX besonders interessant macht. Weitere Tipps und Hilfen erhalten Sie im (gelungenen, aber englischen) Benutzerhandbuch der Workbench.
Jeder Benutzer von SuperX sollte ein geheimes Paßwort benutzen, welches nicht einfach erraten werden kann. Paßwörter wie Vornamen, Stellung im Beruf o.ä. dürfen unter keinen Umständen verwendet werden. Zum Ändern des Paßworts kann im Applet und im XML-Frontend ein Paßwortänderungsdialog aufgerufen werden.
Im Kernmodul befindet sich eine Abfrage "User einrichten", mit der Sie einen User einrichten und ggf. auf bestimmte Institutionsrechte oder Gültigkeitszeiträume einschränken können. Außerdem können Sie den User einem Sachgebiet oder einer Gruppe zuordnen.
Bearbeitungsformulare zur Benutzerverwaltung befinden sich im XML-Frontend . Ausführliche Informationen finden Sie im Kapitel UserverwaltungTabellen . Hier eine Anleitung für die direkte Änderung in der Datenbank:
1. Erstellen eines Eintrags in der Tabelle userinfo . Neue Tid merken.
2.
Setzen des Startpassworts z.B. "anfang12". Mit dem Befehl
update userinfo set passwd_sha="0533a66a3e9bea16f3139bfe4f6ce50ced591dea" where tid=<Neue Tid>
Der User muss aufgefordert werden, sein Passwort beim ersten Start zu ändern.
3.
Dem User Rechte für Institutionen geben durch Einträge in die Tabelle
user_institution
.
Ggfs. Gruppenzugehörigkeit eines Benutzers festlegen.
4. (Eintrag in Tabelle user_group_bez - siehe Abschnitt Userverwaltung)
5. Falls durch die Gruppenrechte noch nicht abgedeckt: Dem User Rechte für ganze Sachgebiete und/oder einzelne Abfragen geben (Einträge in die Tabellen user_sachgeb_bez bzw. user_masken_bez )
Sie können einen User zwingen, sich nach der Anmeldung ein neues Passwort zu geben. Dazu wird dem Feld kennwort in der Tabelle userinfo der Wert "ändern" gegeben. Es erscheint dann nach der ersten Anmeldung eine Aufforderung, das Passwort zu ändern.
N ach mehreren fehlerhaften Login Versuchen wir ein Account gesperrt. Man kann als SuperX-Adminstrator im XML-Frontend ein beliebiges neues Passwort für den Benutzer vergeben. Gehen Sie dazu wie folgt vor:
• Öffnen Sie das Formular Administration > Benutzer verwalten → User suchen, und wählen Sie beim jew. Benutzer den Bearbeiten -Button
• Wählen Sie beim Passwort den Button "ändern". Es öffnet sich ein Eingabefeld rechts daneben, in dem Sie das Passwort ändern.
• Dann können Sie mit dem Feld rechts daneben das Passwort verschlüsseln
• Danach speichern Sie das Formular.
• Wenn die Anzahl der fehlerhaften Logi n Versuche hochgezählt wurde, wird es automatisch wieder auf 0 gesetzt.
Hier ein Screenshot:
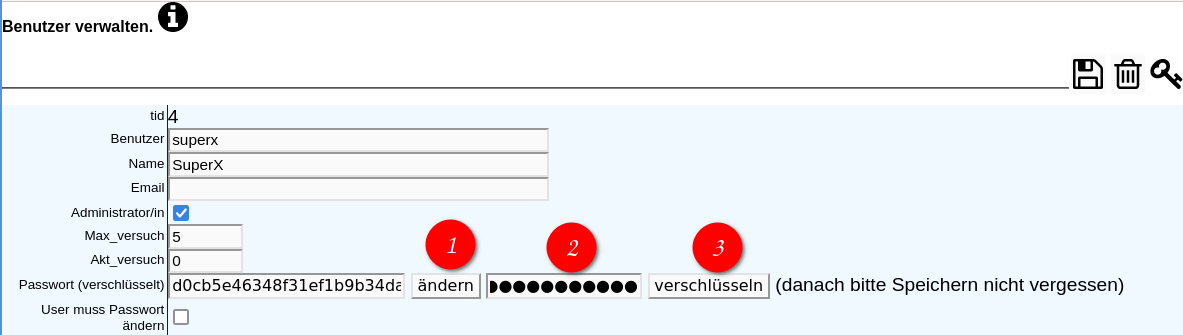
Man kann auch die Checkbox „User muss Passwort ändern“ aktivieren, damit er bei der nächsten Anmeldung ein neue Passwort vergeben muss.
• Rechte für Institutionen gibt oder entfernt man durch Hinzufügen/Löschen von Einträgen in der Tabelle user_institution
• Gruppenzugehörigkeit wird über die Tabelle user_group_bez definiert, ggfs. dort Einträge hinzufügen oder löschen
• individuelle Rechte für Sachgebiete und/oder Masken über die Tabellen user_sachgeb_bez bzw. user_masken_bez anpassen
Die Stammdaten (Name, email, etc) befinden sich in der Tabelle userinfo .
Es gibt im Kernmodul eine Abfrage "User löschen" (im Themenbaum unter Administration -> Benutzerverwaltung). Wenn Sie den User "von Hand" löschen wollen:
Die tid des Benutzers aus der Tabelle userinfo heraussuchen.
Folgende Befehle ausführen.
delete from user_masken_bez where userinfo_id=<tid des Users>;
delete from user_sachgeb_bez where userinfo_id=<tid des Users>;
delete from user_institution_bez where userinfo=<tid des Users>;
delete from userinfo where tid=<tid des Users>;
Bei der Installation des SuperX-Kernmoduls werden in die Tabelle konstanten vier Einträge zur Einstellung der Passwortsicherheit gemacht.
|
Name der Konstante |
Kommentar |
default-Wert |
|
Passwortgültigkeit (Tage) |
Gibt an, für wie viele Tage das Passwort gültig sein soll. Sobald die Gültigkeit abgelaufen ist, muss der Anwender bei der nächsten Anmeldung ein neues Passwort vergeben. |
180 |
|
Passwort Groß- u. Kleinb. |
Müssen Groß- und Kleinbuchstaben im Passwort vorkommen (0=nein, 1=ja) |
1 |
|
Passwort erfordert Ziffer |
Müssen Ziffern im Passwort vorkommen (0=nein, 1=ja) |
1 |
|
Passwortlänge (Minimum) |
Geben Sie hier die minimale Passwortlänge an |
8 |
Beim Upgrade einer älteren Kernmodul-Installation (vor Kernmodul 3.0rc7) sind folgende Vorbelegungen aktiv:
|
Name der Konstante |
default-Wert |
|
Passwortgültigkeit (Tage) |
360 |
|
Passwort Groß- u. Kleinb. |
0 |
|
Passwort erfordert Ziffer |
0 |
|
Passwortlänge (Minimum) |
6 |
Die Zentrale Datenschutzstelle der baden-württembergischen Universitäten (Zendas) macht folgende Empfehlung:
|
Passwortgültigkeit (Tage) |
90-180 |
|
Passwort Groß- u. Kleinb. |
1 |
|
Passwort erfordert Ziffer |
1 |
|
Passwortlänge (Minimum) |
8 |
Um die Konstanten zu ändern, gehen Sie als Administrator in die Anwendung, gehen Sie in das Menü "Administration"->"Tabelle suchen" und suchen Sie die Tabelle "konstanten". In der Zeile klicken Sie auf den "Bearbeiten"-Button, und suchen dort die Konstante Passwortgültigkeit (Tage) etc.
Um kurzfristig die Gültigkeit aller User auf unendlich zu setzen (z.B. bei Testbetrieb), müssen sie in der Datenbank folgenden Update ausführen: update user_pw set pw_gueltig_bis=date_val('01.01.3000');
Der SuperX-Administrator kann erzwingen, dass der Benutzer sein Passwort ändern muss, indem er im XML-Frontend den entsprechenden User bearbeitet und bei "User muss Passwort ändern" ein Häkchen setzt. Neue User werden in der Maske "User einrichten" defaultmäßig so eingestellt, dass sie ihr Passwort nach der ersten Anmeldung ändern müssen.
Sie können in SuperX durch Einträge in den Tabellen zur Gruppenverwaltung einzelne Gruppen anlegen, mit Leserechten für Abfragen und Institutionen versehen. Die zugehörigen Tabellen werden in der Gruppenverwaltung erläutert.
Ausführliche Informationen zur Gruppenverwaltung finden Sie im Kapitel Userverwaltung .
1. Erstellen eines Eintrags in der Tabelle groupinfo . Neue Tid merken.
2. Der Gruppe Rechte für Sachgebiete und/oder einzelne Masken geben (Einträge in die Tabellen group _sachgeb_bez bzw. group_masken_bez )
Gruppenrechte für Sachgebiete und einzelne Masken werden in den Tabellen group_sachgeb_bez bzw. group_masken_bez festlegt. Dort ggfs. Einträge machen oder löschen.
Der Gruppenname kann in der Tabelle groupinfo geändert werden.
Die tid der Gruppe aus der Tabelle groupinfo heraussuchen.
Folgende Befehle ausführen.
delete from group_masken_bez where groupinfo_id=<tid der Gruppe>;
delete from group_sachgeb_bez where groupinfo_id=<tid der Gruppe>;
delete from groupinfo where tid=< tid der Gruppe>;
SuperX-Sichten sind hierarchische Zusammenstellungen von Dimensionen, z.B. von alternativen Kostenstellenhierarchien. Die Sichten können in einem eigenen Formular verwaltet werden, außerdem können die Berechtigungen für Sichten eingeschränkt werden.
Nach der Anmeldung als Administrator im XML-Frontend können Sie im Themenbaum die Abfrage Administration -> Sicht suchen wählen, und abschicken.
|
Im Kernmodul ist nur eine Sicht enthalten, eine alternative Hierarchie, die den Themenbaum aufbaut. |
|
Sie können mit Klick auf den "Bearbeiten"-Button die Sicht in einem Datenbank-Formular bearbeiten. Die folgende Abbildung zeigt das Formular.
Wenn Sie Sichten für die Anwender ausblenden wollen, ist es nicht ausreichend, die Datensätze zu löschen - sie würden beim nächsten Update aus dem Quellsystem wieder eingespielt. Stattdessen sollten Sie die Sichten in der Konstante "Aktiv" ganz unten im Formular auf "0" setzen und dann im SuperXManager den Cache aktualisieren.
Wenn es pro Sichtart mehrere Sichten gibt, kann deren Sortierung im Feld "Sortiernummer" beeinflusst werden. Die erste Sicht in der Sichtart ist auch immer die Sicht, die im Browser-Client standardmäßig beim Aufruf der Maske angezeigt ist wird.
Weitere Details zur Anpassung von Sichten finden Sie im SuperX-Entwicklerhandbuch.
Um die Berechtigung von Sichten zu vereinfachen, werden mehrere Sichten in SuperX zu "Sichtarten" zusammengefasst. Sie können Berechtigungen auf beiden Ebenen vergeben.
Mit Klick auf den Button "User- und Gruppenrechte" können Sie die Rechte für die Sicht / Sichtart vergeben.
|
Wie beid er Userverwaltung finden Sie hier einige Unterformulare: User bzw. Gruppen, die die Sicht sehen dürfen. |
|
|
Im unteren Teil des Formulars können Sie User- und Gruppenrechte für ganze Sichtarten festlegen. |
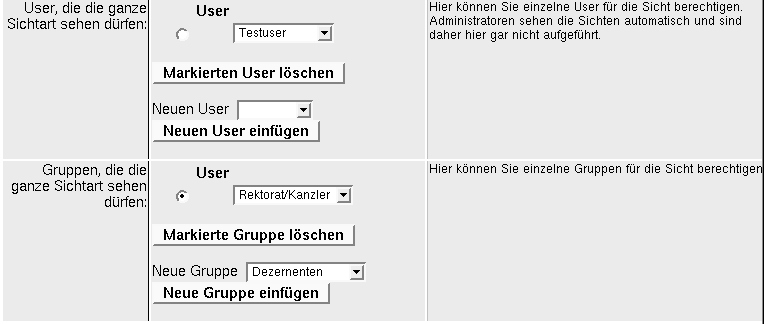
|
Wie bei der Userverwaltung handelt es sich um Unterformulare, d.h. Sie brauchen die Änderungen jeweils nicht zu manuell zu speichern.
Bei der Installation des jew. Moduls erhalten alle User, die Rechte auf das Sachgebiet haben, z.B. "Finzanzrechnung", auch Rechte auf alle Sichten im Bereich Finanzrechnung. Man kann diese Rechte auch nachträglich für einzelne Sichten entfernen, indem man wie folgt vorgeht:
• Im XML-Frontend anmelden als Administrator, und zur Maske "Tabelle suchen" gehen, dort die Tabelle " sachgeb_sichtarten " bearbeiten
• In der Tabelle den Eintrag z.B. für die Zuordnung des Sachgebiets Finanzrechnung zu FIN-Kostenstellen-Sichten löschen.
• Dann in die Tabelle sachgeb_sichten gehen und Bearbeiten
• Dort einen neuen Datensatz mit dem Sachgebiet "Finanzrechnung" und der regulären Sicht FIN-Kostenstellen erzeugen
• Dann einen neuen Datensatz mit dem Sachgebiet "Finanzrechnung" und z.B. einer internen Sicht "FIN-Kostenstellen intern" erzeugen
Damit haben alle User mit Recht auf das Sachgebiet Finanzrechnung automatisch auch Recht auf die beiden Sichten: reguläre Sicht und die interne Sicht FIN-Kostenstellen.
Weitere Sichten können einzelnen Usern/Gruppen dann über die Maske "Sicht suchen"->User und Gruppenrechte vergeben werden (s.o.).
Danach im Manager den Cache leeren und neu anmelden.
Oben wurde dargestellt, wie Leserechte für Sichten vergeben werden. Für eine spezielle Form von Sichten ist es darüber hinaus auch möglich, innerhalb einer Sicht bzw. Hierarchie auf einzelne Knoten einzuschränken: für Kostenstellen-Sichten (erkennbar an der Sichtart "XXX-Kostenstellen-Sicht"). Dies wollen wir an einem Beispiel verdeutlichen:
Angenommen wir haben eine "Fakultät 1 für Geisteswissenschaften". Innerhalb dieser Fakultät gibt es Lehreinheiten, und darunter Institute bzw. Professoren. Ein Auszug aus dem Beispielbaum:
• Fakultät 1 für Geisteswissenschaften
◦ Lehreinheit Geschichte
▪ Institut für Frühgeschichte
• Prof. Meyer
◦ Lehreinheit Philosophie
▪ Institut für Humanistische Philosophie
• Prof.'in Schulze
Der Beispielbaum bildet das Organigramm der Hochschule, in HISinOne entspricht dies der Tabelle orgunit . Dies ist gleichzeitig die Grundlage für die Zuweisung von Benutzerrechten. Eine Person kann einem oder mehreren "Knoten" im Organigramm zugeordnet werden. So könnte man z.B. einstellen , daß Prof.'in Schulze nur ihre eigene Kostenstelle sehen darf, nicht die übergeordneten.
Die Berechtigung gilt normalerweise systemweit, d.h. in allen Auswertungen, egal ob im Haushalts,- Personal-, Flächen,- Inventar- oder KLR-Bereich, sind diese Rechte wirksam.
Nun kann es notwendig sein, bereichsspezifisch alternative Berechtigungen zu implementieren. An dieser Stelle kommen alternative Hierarchien ins Spiel, wie im Folgenden an einem Beispiel gezeigt wird.
Neben der Berechtigung innerhalb der regulären Sicht bzw. dem Organigramm kann es notwendig sein, auch Rechte innerhalb von alternativen Hierarchien zu vergeben. Hier verfolgen wir folgendes Konzept:
1. Ein Anwender darf jeden Knoten auf und unterhalb seiner berechtigten Knoten sehen
2. Dies gilt auch bei alternativen Hierarchien, d.h. wenn ein Knoten für den jew. User sichtbar ist, kann dieser auch in der alternativen Hierarchie die "Kinder" des jew. Knotens sehen.
Wenn z.B. Prof.'in Schulze im Personal-Modul nur die eigenen Kostenstellen sehen darf, im KLR-Modul aber die ganze Fakultät (z.B. wenn sie zeitweise die Rolle einer KLR-Beauftragten in der Fakultät innehält), dann könnte der Administrator bzw. Controller eine spezielle Hierarchie aufbauen, z.B. mit dem Namen "KLR-Baum für Prof.'in Schulze", und diesen Baum bzw. diese Sicht der Frau zuweisen. In dieser Sicht ist der Baum ganz anders aufgebaut:
Fakultät 1 für Geisteswissenschaften
◦ Prof.'in Schulze
▪ Lehreinheit Geschichte
• Institut für Frühgeschichte
◦ Prof. Meyer
▪ Lehreinheit Philosophie
• Institut für Humanistische Philosophie
Dadurch, daß der Person Prof.'in Schulze die eigene Kostenstelle, und in dieser Hierarchie darunter alle Kostenstellen der Fakultät liegen, darf Frau Prof.'in Schulze, wenn sie für diese Hierarchie berechtigt ist, auch alle anderen Kostenstellen der Fakultät sehen. Da die Hierarchie nur im KLR-Modul existiert, sind die "normalen" Kostenstellenrechte in den anderen Modulen nicht tangiert, d.h. im Personal- oder Haushaltsmodul dürfte die Person weiterhin nur ihre "eigene" Kostenstelle sehen.
Durch die Funktionalität, alternative Hierarchien anzugeben und Berechtigungen themenbezogen zu steuern, können also beliebige Berechtigungskonzepte realisiert werden, und der Administrator bzw. Controller kann durch den Aufbau des Baums steuern, wo welche Kostenstelle für wen sichtbar sein soll.
Angemeldeten Benutzern wird oben ein Menü angezeigt, über das z.B. in die Verschiedenen Systeme geleitet werden kann:
Nach der Installation/dem Upgrade werden erst mal „Standardberichte“ und „Datenanalyse“ (→Saiku) angezeigt. Mitgeliefert werden aber auch die Einträge für Management, Joolap und das Applet. Da diese werden aber seltener verwendet und sind daher deaktiviert. Über das Feld „aktiv“ können diese aber auf „1“=aktiv gesetzt werden („0“ steht für inaktiv). Die Daten für das Menü kommen aus der Tabelle sx_repository . Folgende Felder werden hier verwendet:
• id: Dieses Feld muss in dieser Tabelle eindeutig sein. Am besten den Präfix:“WELCOME_“ verwenden und danach mit einen sinnvollen Namen in Großbuchstaben ergänzen.
• c ontent: Hier den Link eintragen, zu dem der Menüeintrag verweisen soll.
• c aption: Hier den Text eintragen, der im Menü stehen soll.
• c omment: Neu ist, dass ein icon-Font integriert wurde. Damit können Icons besser implementiert werden. Diese Icons werden dann neben dem Menü-Eintrag angezeigt. Welche Icons zur Verfügung stehen und welcher Code dafür eingegeben werden muss erfahren Sie auf Ihrem SuperX Server unter <<Server-Adresse>>/superx/xml/fonts.html.
• a rt: Hier muss „WELCOME_LINK“ eingetragen werden, damit dieser Eintrag als Menü-Punkt erkannt wird.
• s ort1: Über diese Nummer wird die Sortierung festgelegt. Das Menü fängt mit dem Eintrag an, der die niedrigste Nummer hat und geht dann immer höher.
• gueltig_von, gueltig_bis: Hier kann angegeben werden in welchem Zeitraum der Menü-Punkt angezeigt wird. Wenn es immer gelten soll für gueltig_von „01.01.1900“ und für gueltig_bis „01.01.3000“ eintragen. Dies sind auch die Standard-Einträge, falls das Feld leer gelassen wird.
Als Startseite steht nun ein Portal zur Verfügung. Hier kann dem Benutzer alle möglichen Informationen mitgeteilt werden. Dabei kann unterteilt werden zwischen Informationen die nur angemeldete Benutzer sehen oder Informationen die alle sehen dürfen, also auch schon vor der Anmeldung:
Es können auch Zeitlich begrenzte Informationen ausgegeben werden, wie z.B. wenn Wartungsarbeiten anstehen oder eine Mitarbeiter Schulung angeboten wird.
Für die Portlets stehen aktuell nur die Farben grün und rot zur Verfügung. Diese können aber leicht erweitert werden.
Die Portlets werden in der Tabelle sx_portlet gepflet. Hier stehen folgende Felder zur verfügung:
• name: Der Name des Portlets wird als Überschrift ausgegeben.
• type: Hier wird der Ausgabe-Typ eingetragen. Bisher wird nur „HTML“ unterstützt.
• class: Hier kann eine CSS Klasse für das Portlet eingetragen werden. Bisher gibt es die Klassen „green“ und „red“. Damit kann die Hintergrundfarbe gewählt werden. Mit eigenen CSS Klassen kann hier noch wesentlich mehr gemacht werden.
• icon: Neu ist, dass ein icon-Font integriert wurde. Damit können Icons besser implementiert werden. Diese Icons werden dann neben dem Portlet angezeigt. Welche Icons zur Verfügung stehen und welcher Code dafür eingegeben werden muss erfahren Sie auf Ihrem SuperX Server unter <<Server-Adresse>>/superx/xml/fonts.html.
• content: Hier steht der Inhalt, der in dem Portlet ausgegeben wird. Bei type=“HTML“ bitte auch HTML Syntax verwenden.
• visible: false=wird nicht angezeigt, all=wird auch nicht angemeldeten Besuchern angezeigt, wenn das Feld leer gelassen wird=wird nur angemeldeten Benutzern angezeigt.
• gueltig_von, gueltig_bis: Hier kann angegeben werden in welchem Zeitraum das Portlet angezeigt wird. Wenn es immer gelten soll für gueltig_von „ 01.01.1900“ und für gueltig_bis „ 01.01.3000 “ eintragen. Dies sind auch die Standard-Einträge, falls das Feld leer gelassen wird.
Auf der Startseite und allen Unter-Seiten muss ab 25.5.2018 gem. DSVGO ein Impressum und eine Datenschutzerklärung verlinkt werden. Diese sind server- und hochschulspezifisch und werden daher im Hochschul-Repository mit Beispielinhalten ausgeliefert.
Diese sollten angepasst werden:
• Öffnen Sie Abfragen → Administration → Hochschul-Repository
• Klicken Sie auf Abschicken. Sie erhalten je einen Datensatz für "IMPRINT" (Impressum) oder "PRIVACY" (Datenschutzerklärung), hier z.B. Impressum.
• Klicken Sie beim jew. Eintrag auf Bearbeiten:
• Sie erhalten ein Datenbankformular. B earbeiten Sie den Inhalt im Feld " Inhalt der Variable " .
Der Editor ist ein "WYSIWYG"-Editor, Sie können hier HTML Code verwenden und auch Styles mit angeben.
Details zu den Inhalten siehe z.B. Wikipedia
Über die Repository Variable CUSTOM_CSS kann eigener CSS Code in der Startseite Verwendet werden (zukünftig auch im gesamten SuperX). Das CSS wird nach den CSS Dateien von SuperX geladen und wird daher auch höher priorisiert behandelt. Dadurch können vorhandene Styles über die Repository-Variable verändert oder neue ergenzt werden, falls das Aussehen verändert werden soll.
Z.B. kann das Menü in grau verändert werden mit folgendem Code:
.nav a {
background: #ffffff;
border: 1px solid #777777;
color: #333333;
}
.nav a:hover {
background-color: #cccccc;
}
.icon {
font-family: sans-serif;
}
Das würde dann folgendermaßen aussehen:
Mondrian ist ein freier, quelloffener, in JAVA geschriebener OLAP Server der ab Kernmodul Version 4.7 in SuperX implementiert wurde. Saiku bildet dazu die Oberfläche, über die per Drag&Drop die gewünschten Zeilen und Spalten gewählt werden können um eine Tabelle zu generieren.
Wenn auf das Kernmodul mit Mondrian aktualisiert wird, gibt es einiges zu beachten:
• Cubes und Dimensionen der verwendeten Module in die edustore.xml übertragen
• In der context.xml muss die connection raus
• Benutzern müssen die Rechte für die Würfel erhalten
In der $WEBAPP/WEB-INF/web.xml müssen für Saiku einige Anpassungen vorgenommen werden. Es empfiehlt sich die Vorlage web.xml.superxonly zu verwenden und eventuelle eigene Anpassungen dort hin zu übertragen. Weitere Anpassungsmöglichkeiten in der web.xml werden im Kapitel Einrichten der SuperX-Servlets unter Tomcat erläutert.
Zuerst sollte geprüft werden, ob die Verzeichnisse edustore, saiku-datasources und saiku-repository unterhalb von $WEBAPP/WEB-INF/classes vorhanden sind. Zusätzlich sollte in dem Verzeichnis edustore die edustore.xml liegen und je Modul die edustore_<<MODUL>>.xml .
Die edustore.xml ist das Herzstück von Mondrian. Hier stehen die Cubes und Dimensionen, die verwendet werden dürfen. Es ist ratsam immer eine Kopie von einer funktionierenden Version anzulegen.
In dem selben Verzeichnis liegen für alle Module Vorlagen mit deren Cubes und Dimensionen um die edustore.xml damit zu erweitern/aktualisieren. Eine leere Vorlage (das Grundgerüst) bietet die edustore_kern.xml . Diese kann verwendet werden um die edustore.xml neu aufzubauen. Dazu einfach die edustore_kern.xml nach edustore.xml kopieren. Danach kann mit z.B.
edustore_xml_upgrade.x $WEBAPP/WEB-INF/classes/edustore/edustore_sva.xml
Bei einem Modul Upgrade kann die edustore.xml mit den neuen Würfeln und Dimensionen automatisch aktualisiert werden ( Variable in SQL_ENV ). Wenn die edustore.xml manuell bearbeitet wurde, ist es ratsam, das aktualisieren bei einem Upgrade auszustellen.
die Cubes und Dimensionen des SVA Moduls eingefügt werden. Mit dem selben Befehl werden auch Cubes und Dimensionen aktualisiert, falls diese erweitert wurden z.B. in einer neuen Modulversion.
Bis Kernmodul Version 4.5/ 4.6 wurde der JNDI Connection Pool von Tomcat für die DBForms und Saiku verwendet. Die Konfiguration fand in der Datei $WEBAPP/META-INF/context.xml statt . Ab Kernmodul 4. 7 wird der SuperX Connection Pool (dbcp) mitverwendet. Um eventuelle Probleme zu vermeiden sollte die dbconnection aus der $WEBAPP/META-INF/context.xml gelöscht werden.
<Resource name="jdbc/superx" auth="Container"
type="javax.sql.DataSource"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="org.postgresql.Driver"
url="jdbc:postgresql://localhost:5432/superx_tk46"
username="superx"
password="anfang12"
maxActive="7"
maxIdle="5"
maxWait="1"
removeAbandoned="true"
removeAbandonedTimeout="10"
/>
In der $WEBAPP/WEB-INF/dbforms-config.xml sollte ganz am Ende die dbconnection folgendermaßen aussehen:
<dbconnection conClass="org.apache.commons.dbcp.PoolingDriver"
name="jdbc:apache:commons:dbcp:default"
isJndi="false"/>
In der $WEBAPP/WEB-INF/classes/saiku-datasources/edustore sollte die location folgendermaßen angegeben werden:
location=jdbc:mondrian:Jdbc=jdbc:apache:commons:dbcp:default;Catalog=res:edustore/edustore.xml;JdbcDrivers=org.apache.commons.dbcp.PoolingDriver;DynamicSchemaProcessor=de.superx.saiku.schema.SuperxDynamicSchemaProcessor
Hier die Standard edustore Datei:
type=OLAP
name=default
driver=mondrian.olap4j.MondrianOlap4jDriver
location=jdbc:mondrian:Jdbc=jdbc:apache:commons:dbcp:default;Catalog=res:edustore/edustore.xml;JdbcDrivers=org.apache.commons.dbcp.PoolingDriver;DynamicSchemaProcessor=de.superx.saiku.schema.SuperxDynamicSchemaProcessor
# location=jdbc:mondrian:Jdbc=jdbc:apache:commons:dbcp:default;Catalog=res:edustore/edustore.xml;JdbcDrivers=org.apache.commons.dbcp.PoolingDriver;DynamicSchemaProcessor=de.superx.saiku.schema. Simple SchemaProcessor
#location=jdbc:mondrian:Jdbc=jdbc:postgresql://localhost:5432/dev_java8_eduetl?ApplicationName=saiku2;username=postgres;password=postgres;Catalog=res:edustore/edustore.xml;JdbcDrivers=org.postgresql.Driver;DynamicSchemaProcessor=de.superx.saiku.schema.SuperxDynamicSchemaProcessor
# some security configuration for roles, first enable it
security.enabled=true
# there are 3 different types of security:
# "one2one" (try and map spring user roles to mondrian roles),
# "mapping" (define the mapping of spring and mondrian roles manually)
# "passthrough" (will pass username + password of logged in user to connection, e.g. jdbc user + password)
security.type=superx
# security.type=mapping
# security.mapping=springRole=mondrianRole1;springRole2=mondrianRole2
Bei name soll der Mandanten Name angegeben werden. Wenn es keine Mandanten gibt, einfach default eintragen.
Achtung: in dem Verzeichnis $WEBAPP/classes/saiku-datasources keine Backup Dateien von der edustore Datei anlegen. Saiku verwendet alle Dateien aus diesem Verzeichnis als Datasource!
In der $WEBAPP/WEB-INF/classes/mondrian.properties können auch weitere Parameter wie Timeout bestimmt werden. Hier muss auch der JDBC und Postgres/Informix Treiber hinterlegt sein.
mondrian.jdbcDrivers=org.hsqldb.jdbcDriver,org.postgresql.Driver
Wenn ein Benutzer einen Würfel in Saiku öffnen dürfen soll brauch t er bzw. seine Gruppe dazu die Rechte auf das jeweilige Sachgebiet . Die Sachgebiete und Würfel erfahren Sie im über:
SELECT F.thema,F.name,S.name as sachgebiet
FROM fact_table F, sachgebiete S
where S.tid=val(F.sachgebiete_id)
and F.name like '%cube'
and S.name not like 'joolap%'
order by 1;
Das Logging in Mondrian / Saiku wird über die $WEBAPP/WEB-INF/log4j.properties gesteuert. Wir empfehlen für Saiku f o lgende Einträge zu übernehmen:
# Saiku
log4j.appender.saiku=org.apache.log4j.DailyRollingFileAppender
log4j.appender.saiku.File=saiku.log
log4j.appender.saiku.Append=false
log4j.appender.saiku.DatePattern='.'yyyy-MM-dd
log4j.appender.saiku.layout=org.apache.log4j.PatternLayout
log4j.appender.saiku.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %-30.40c{1}(%-4.6L) - %m%n
# Trace MDX and SQL statements
log4j.category.mondrian.mdx=DEBUG, saiku
log4j.category.mondrian.sql=DEBUG, saiku
Bei Fehlern kann dann die angegebene Datei geprüft werden. Der Dateiname saiku.log kann natürlich auch anders genannt werden. Hier empfehlen wir auch einen absoluten Pfad zu verwenden. Fehler im Zusammenhang mit Tomcat werden aber auch in der tomcat/logs/catalina.out geloggt. Daher diese Datei auch immer im Auge behalten.
Hier stehen ein paar Tipps zu Problemen, die wir bereits hatten und eine Lösung gefunden haben.
Siehe Kapitel
Wenn die gesamte Webapplikation nicht mehr läuft/aufrufbar ist, kann dies mehrere Ursachen haben. In diesem Kapitel geht es speziell um die Fehler, die Saiku verursacht. Hier ein paar Fehlermeldungen aus der catalina.out mit den passenden Lösungsvorschlägen dazu. Zwei Punkte sollten aus Erfahrung immer durchgeführt werden, wenn ein Problem auftritt:
• Kapitel Drop Tables ein mal die jcr- Tabellen löschen.
• Kapitel Saiku data Verzeichnis löschen .
Im Zweifelsfall sollten Sie die folgenden Maßnahmen durchführen, und danach Tomcat neu starten.
Bei folgender Fehlermeldung in der catalina.out :
WARN org.apache.jackrabbit.core.data.db.DbDataStore - Can not init data store, driver=org.postgresql.Driver url=jdbc:postgresql://localhost:5432/superx?ApplicationName=jcr user=superx schemaObjectPrefix=jcr_ tableSQL=datas tore createTableSQL=CREATE TABLE jcr_datastore(ID VARCHAR(255) PRIMARY KEY, LENGTH BIGINT, LAST_MODIFIED BIGINT, DATA BYTEA)
org.apache.commons.dbcp.SQLNestedException: Cannot create PoolableConnectionFactory (FATAL: database "superx" does not exist)
in der Datei $WEBAPP/superx/WEB-INF/saiku/repository/configuration.xml die Datenbank-Parameter prüfen.
Bei folgender Fehlermeldung in der catalina.out:
WARN org.springframework.web.context.support.XmlWebApplicationContext - Exception encountered during context initialization - cancelling refresh attempt
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'sessionResource' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'userServiceBean' while setting bean property 'userService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'userServiceBean' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'datasourceServiceBean' while setting bean property 'datasourceService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'datasourceServiceBean' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'connectionManager' while setting bean property 'connectionManager'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'connectionManager' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'repositoryDsManager' while setting bean property 'dataSourceManager'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'repositoryDsManager' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Invocation of init method failed; nested exception is org.saiku.service.util.exception.SaikuServiceException
in der Datei $WEBAPP/superx/WEB-INF/saiku/ saiku-beans .xml die Datenbank-Parameter prüfen.
Bei folgender Fehlermeldung in der catalina.out müssen sehr wahrscheinlich einige Tabellen gelöscht werden.
Vorsicht: beim Droppen werden vorhandene, in Saiku gespeicherte Abfragen gelöscht.
Diese werden bei dem nächsten Tomcat N eustart wieder erstellt und gefüllt.
WARN org.springframework.web.context.support.XmlWebApplicationContext - Exception encountered during context initialization - cancelling refresh attempt
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'sessionResource' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'userServiceBean' while setting bean property 'userService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'userServiceBean' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'datasourceServiceBean' while setting bean property 'datasourceService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'datasourceServiceBean' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'connectionManager' while setting bean property 'connectionManager'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'connectionManager' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'repositoryDsManager' while setting bean property 'dataSourceManager'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'repositoryDsManager' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Invocation of init method failed; nested exception is org.saiku.service.util.exception.SaikuServiceException
at org.springframework.beans.factory.support.BeanDefinitionValueResolver.resolveReference(BeanDefinitionValueResolver.java:359)
at org.springframework.beans.factory.support.BeanDefinitionValueResolver.resolveValueIfNecessary(BeanDefinitionValueResolver.java:108)
Folgende Tabellen löschen:
drop table jcr_journal_global_revision;
drop table jcr_journal_journal;
drop table jcr_journal_local_revisions;
drop table jcr_version_binval;
drop table jcr_version_bundle;
drop table jcr_version_names;
drop table jcr_version_refs;
drop table jcr_wsp_default_binval;
drop table jcr_wsp_default_bundle;
drop table jcr_wsp_default_names;
drop table jcr_wsp_default_refs;
drop table jcr_wsp_security_binval;
drop table jcr_wsp_security_bundle;
drop table jcr_wsp_security_names;
drop table jcr_wsp_security_refs;
Im data Verzeichnis unterhalb von $WEBAPP/WEB-INF/saiku/repository/ liegen auch Konfigurationsdateien, welche automatisch angelegt werden. Wenn sich jedoch mal etwas ändert (an der Datenbank…) kann dies zu Problemen führen. Dann am besten dieses Verzeichnis ein mal löschen.
Bei dem Wechsel der Mondrian Version 3 zu Version 4 hat sich auch das Format der edustore.xml in $WEBAPP/WEB-INF/classes/edustore/ geändert.
Hier die Versionen zu Releases:
• SuperX Kernmodul 4.7 / HisinOne-BI 8.0 verlangt Mondrian Schema 3
• HisinOne-BI 2017.06 oder höher verlangt Mondrian Schema 4
Wenn hier noch das jeweils falsche Format vor liegt, kommt es zu folgendem Fehler:
WARN org.springframework.web.context.support.XmlWebApplicationContext - Exception encountered during context initialization - cancelling refresh attempt
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'sessionResource' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'userServiceBean' while setting bean property 'userService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'userServiceBean' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'datasourceServiceBean' while setting bean property 'datasourceService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'datasourceServiceBean' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'connectionManager' while setting bean property 'connectionManager'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'connectionManager' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Cannot resolve reference to bean 'repositoryDsManager' while setting bean property 'dataSourceManager'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'repositoryDsManager' defined in ServletContext resource [/WEB-INF/saiku/saiku-beans.xml]: Invocation of init method failed; nested exception is org.saiku.service.util.exception.SaikuServiceException
Zur Fehlerbehebung ein mal die $WEBAPP/WEB-INF/classes/edustore/ edustore.xml aktualisieren und Tomcat neu starten.
Wenn eine Dimension leer ist und folgende Fehlermeldung erscheint:
InvalidHierarchyException: Mondrian Error:Hierarchy '[bluep_stichtag_s.Stichtag (Studierende)]' is invalid (has no members)
kann zunächst aus Datenbank mit folgendem SQLdie Information geholt werden, ob wirklich keine Daten zu finden sind:
SELECT * FROM dim_bp_apnr where dimension_bp_id=(select tid from dimension_bp where apnr='bluep_stichtag_s');
'bluep_stichtag_s' kann mit jeder beliebigen Dimension ersetzt werden.
Wenn kein Datensatz heraus kommt, sollte zunächst geprüft werden, ob in der cube Tabelle etwas drin steht.
Wenn eine Cube Tabelle leer ist, ist eventuell das Modul veraltet. In SOS gab es z.B. für Fleda früher einen Filter:
and 0 < (select count(*) from db_version where his_system='edudata')
der heute nicht mehr gültig ist und nicht mehr greift. Dadurch bleibt die Tabelle sos_stg_aggr leer. Das ist aber nur bis SOS Version 0.9. Ab SOS Version 1.0 wurde der Filter für Saiku angepasst.
Wenn die Umlaute in Saiku kaputt sind und ein ISO System vorliegt, kann es helfen die edustore.xml nach UTF-8 zu konvertieren. Da Saiku in UTF-8 läuft, tritt dieses Problem schon mal auf.
Die edusore.xml liegt hier:
$WEBAPP/WEB-INF/classes/edustore /edustore.xml
Die Abfragemasken liefern die Daten aus den Basissystemen an das SuperX-Frontend aus. Einige Abfragen zur Administration sind im Kernmodul enthalten, die Abfragen zu den Basissystemen sind in den jeweiligen Modulen enthalten. Die Abfragen in der Administration erlauben es, neue Masken anzulegen, zu kopieren und zu löschen. Im Folgenden finden Sie allgemeine Hinweise für die Verwaltung der Masken.
Die Masken lassen sich über UNIX, über Access und in Zukunft über ein Java-Frontend administrieren. Unter UNIX geschieht dies über Scripte. Für Windows-Nutzer gibt es ein Access-Frontend, das sich derzeit im Betatest befindet.
Die Masken lassen sich im SuperX-Applet verwalten, weitergehende Möglichkeiten bietet aber das XML-Frontend (Möglichkeit der Editierung von großen text -Feldern bei Postgres als Datenbanksystem). Nach der Anmeldung haben Administratoren das Recht, Masken zu löschen, zu kopieren und erzeugen. Die einzelnen Felder der Masken lassen sich direkt in der Datenbank oder z.B. mit MS Access verändern. Im Applet sind nur grundlegende Verwaltungsoperationen möglich. Sie sind als Ersatz für die UNIX- Scripte gedacht.
|
Folgende "Abfragen" zur Maskenverwaltung gibt es im Sachgebiet Administration: |
|
|
Darunter im Ast "Felder" gibt es noch folgende Abfragen: |
|
|
Darüberhninaus gibt es (nur unter Postgres) die Masken zur Pflege von Masken bzw. Feldern |
|
Maske
erzeugen
. Hier kann eine neue Maske erzeugt werden, und die wichtigsten Zuordnungen der Maske werden angegeben, z.B. Sachgebiet, Themenbaum-Parent etc. Die Felder der Maske selbst in den dazugehörigen Tabellen (z.B. maskeninfo) werden nicht gefüllt oder im Applet administriert. Dazu dienen die Datenbank-Frontends selbst. (s.u.).
Bei der Nummer der Maske (tid) sollten Sie das Nummernschema von SuperX einhalten, um in Zukunft
Abfragen-Pooling
zu ermöglichen.
Maske kopieren . Wie im UNIX - Script wir eine Maske in eine neue Maske kopiert, und alle zugehörigen Tabellen werden aktualisiert. Zusätzlich wird auch der Eintrag im Themenbaum gemacht.
Maske löschen . Wie im UNIX-Script werden Masken aus allen dazugehörigen Tabellen entfernt. Zusätzlich wird auch der Eintrag im Themenbaum gelöscht. Zur Sicherheit muss die Nummer der Maske manuell eingegeben werden.
Maske suchen
.
Sie können Masken suchen und im XML-Frontend komfortabel editieren. Schränken Sie Ihre Auswahl auf ein Sachgebiet ein, und drücken Sie "Abschicken". Sie erhalten eine Liste mit "Treffern", und rechts befinden sich jeweils Buttons zum ansehen bzw. editieren einer Maske.
Die Maske läuft nur unter Postgres, weil Informix kein direktes Bearbeiten von Blob-Feldern mit sql unterstützt.
Feld suchen . Sie können analog zu "Maske suchen" auch Felder suchen und bearbeiten.
Die Abfragen sind selbsterklärend; das Erzeugen neuer Masken, Löschen vorhandener Masken und Kopieren vorhandener Masken ist nur für Userkennungen möglich, die in der Tabelle userinfo im Feld administration den Wert 1 haben. Natürlich sollten die Abfragen sehr vorsichtigt benutzt werden, sie sind die einzigen Abfragen in SuperX, die tatsächlich Änderungen an der Datenbank vornehmen können.
Das Access-Frontend ermöglicht die bequeme Änderung von Abfragen (für die Eingabe neuer Masken und Felder empfehlen wir eher die Abfragen im normalen Themenbaum). Es befindet sich im SuperX-Clientpaket in tools\access\superx_frontend_sam.mdb . Benennen Sie die Datei um nach superx_frontend.mdb . Danach können Sie unter Masken die einzelnen Masken von SuperX anwählen und öffnen. Sie erhalten im Formular maskeninfo ein Formular, das Eingaben oder Änderungen in der Tabelle maskeninfo ermöglicht.
|
Das Formular ermöglicht es, Masken zu ändern und zu erzeugen. Sie können eine TID vergeben und einen Namen eintragen. |
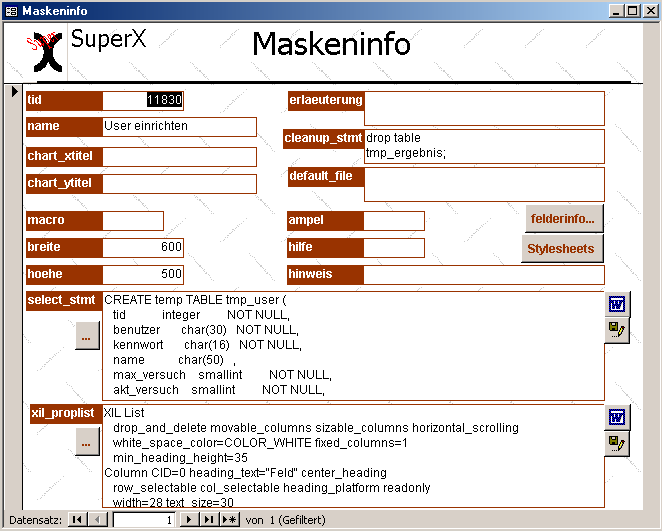
|
Mit dem Button Felderinfo gelangen Sie zu den Feldern dieser Maske. Sie können die Felder dort bearbeiten. Bein Hinzufügen neuer Felder müssen Sie allerdings die jeweiligen tids manuell in die Tabelle masken_felder_bez eintragen.
Analog funktioniert die Bearbeitung der individuellen Stylesheets für eine Maske.
Ein großer Nachteil des 'alten' SuperX war die unvollständige Übermittlung von Fehlermeldungunen bei der Ausführung von Abfragen. Mit dem neuen SuperX gestaltet sich die Entwicklung von Abfragen wesentlich einfacher. Es gibt mehrere Wege, Abfragen zu enwickeln und zu debuggen.
Als Entwickler sollten Sie sich eine einene Servlet-Engine mit Tomcat lokal
installieren
und das Logging in der Datei
$SUPERX_DIR/webserver/tomcat/webapps/superx/web-inf/web.xml
aktivieren
(Achtung: dies sollten Sie nur bei lokalen Tomcats tun, nicht im Echtbetrieb, da sonst die Performance leidet). Durch das Logging können Sie genau sehen, an welcher Stelle eine Abfrage abbricht, u.U. übermittelt der JDBC-Treiber auch die Fehlermeldung. Sie können die Protokollierung auch in eine Datei umleiten. So können Sie auch einzelne SQL-Statements aus der LOG-Datei kopieren und in
dbaccess
von Hand ablaufen lassen.
Viele Abfragen in SuperX arbeiten mit temporären Tabellen. Diese sind zwar unter Informix kennungs- und sitzungsabhängig ist, aber es kann beim Abbruch einer Abfrage passieren, daß temporäre Tabellen erhalten bleiben. Beim nächsten Start der Abfrage führt dies also zu einer Fehlermeldung, wenn die temporäre Tabelle neu erzeugt werden soll. So kann es also passieren, dass kein User eine Abfrage mehr ausführen kann, oder gar dass Tomcat abstürzt. In diesem Falle muss man Tomcat einmal beenden und wieder neu starten. Auch deshalb ist es im Echtbetrieb also ratsam, für die Entwicklung von Abfragen einen "eigenen" Tomcat lokal zu installieren.
Ein weiterer einfacherer Weg des SQL-Debugging besteht darin, sich die Fehlermeldungen im Applet anzeigen zu lassen; dazu muss das Logging in der Datei superx.properties eingeschaltet werden. Danach können Sie sich die SQL-Statements in der Java-Konsole anschauen. Diese können Sie (unter Windows) in der Systemsteuerung -> Java Plugin x.x aktivieren. Unter Netscape 6.x mit Linux erreichen Sie die Java-Konsole über das Menü Tools -> Java Console. Sie können auch das SuperX-Applet auspacken ( jar -xvf superx.jar ) und dann SuperX als Anwendung starten mit java superx >logdatei.txt . In diesem Falle sehen Sie die Fehlermeldungen direkt auf der Konsole oder in der DOS-Box bzw. in der angegebenen Logdatei.
Die Statistiken in SuperX ist nicht immer für Außenstehende "selbsterklärend", und insbesondere bei Kennzahlen und kondensierten Werten sollten die Konzepte mit einem Glossar versehen sein.
Die Oberfläche des Systems bietet drei Möglichkeiten der Dokumentation:
• Dialogelemente auf den Masken können mit einem "Tool-Tip" versehen werden, d.h. bei Mausbewegung über den Button wird eine Erläuterung angezeigt.
• Ergebnistabellen können mit einem Glossar versehen werden, das die in der Tabelle benutzten Begriffe auf einer zweiten Seite erläutert.
• Umfangreichere Hilfetexte sind über die kontextabhängigen Hilfetexte zu einem Themenbereich, z.B. "Studierende" verlinkt.
Für alle Dokumentationsarten wird dies im Menü Administration -> Masken -> Beschriftungen suchen ( Tabelle sx_captions) gepflegt, die Felderläuterungen und allgemeine Schlüssel w örter dokumentieren. Die Dokumentation ist sogar mehrsprachig möglich. Es werden immer Standardtexte ausgeliefert, die die Hochschule aber beliebig ändern kann.
Generell gilt: wenn eine Hochschule Beschriftungen ändert, werden diese nicht durch das System (z.B. beim Upgrade) überschrieben. Nur bei Deinstallation eines Moduls werden die zugehörigen Beschriftungen gelöscht.
Allgemeine Schlüsselwörter sind im Menü Administration -> Masken -> Beschriftungen suchen ( Tabelle sx_captions) definiert, man erkennt sie, daran dass die Spalte id gefüllt ist (table_name, field_name und record_no hingegen leer)
|
tid |
id |
table_name |
field_name |
record_no |
locale |
contents_short |
contents_long |
sachgebiete_id |
|
1 |
studiengang |
|
|
|
de |
Studiengang |
Studiengänge definieren sich durch das Fach, die Vertiefungsrichtung, durch Haupt- oder Nebenfach sowie den Abschluss. |
16 |
|
2 |
studiengang |
|
|
|
en |
Subject / Degree |
A combination of subject and degree as well as the major-minor distinction |
16 |
|
3 |
stud_general |
|
|
|
de |
Studierende allgemein |
|
|
|
4 |
stud_general |
|
|
|
en |
students (general) |
|
|
Im Beispiel wird der Tag studiengang definiert.
Dieser Tag wird, wenn darum die Sonderzeichen @@@ aufgeführt sind (also hier z.B. @@@studiengang@@@) an beliebiger Stelle (Maskennamen, Überschriften, select_stmt, XIL-Proplist, XSL-Dateien, etc) durch den Eintrag contents_short der aktuellen Locale ersetzt.
Für die Erläuterung von Maskenfeldern können kurze und längere Hilfetexte hinterlegt werden. Die kurzen Texte dienen als Beschriftung des Feldes (überschreiben als den "Feldnamen"), und die langen Texte erscheinen als Tool-Tip bei Mausbewegung auf den Button. Im Ausdruck werden die Maskenfelder wahlweise auf einer separaten Seite dokumentiert.
Damit nicht für jedes einzelne Maskenfeld ein Eintrag gemacht werden muss, kann ein Hilfetext über seinen Namen auch mehreren Maskenfeldern zugeordnet werden; in diesem Fall ist die Spalte record_no leer.
Für Felder aus der Tabelle felderinfo schaut SuperX nach, ob in der Tabelle sx_captions ein Eintrag für die Tabelle felderinfo , field_name studiengang und record_no = 10050 oder null vorhanden ist
Im folgenden Beispiel ist ein Maskenbutton "Studiengang" erläutert, der in dieser Weise und bei dem Feld Nummer 10050 dokumentiert sein soll.
|
tid |
id |
table_name |
field_name |
record_no |
locale |
contents_short |
contents_long |
sachgebiete_id |
|
9 |
|
felderinfo |
studiengang |
10050 |
de |
Grundständiger Studiengang |
Ein Studiengang im grundständigen Studium |
16 |
|
10 |
|
felderinfo |
studiengang |
10050 |
en |
Degree program |
|
16 |
Wenn Sie den Erläuterungstext bei allen Feldern mit dem Namen " studiengang " erscheinen lassen wollen, dann müssen Sie das Feld record_no leer lassen.
Bei jedem Themenbereich (z.B. "Studierende") ist ein Benutzerhandbuch verlinkt. Die Voreinstellung, das ausgelieferte Benutzerhandbuch, kann man anpassen. Gehen Sie dazu in das Menü Administration -> Masken -> Beschriftungen suchen, und suchen Sie dort nach "Benutzerhandbuch". Sie finden z.B. das Element für die Studierendenverwaltung, mit der ID sos_doku_benutzer_url . Im Feld "Beschriftung (kurz)" steht der voreingestellte HTML-Code mit der URL, z.B.
<br/><a class="handbuch_link" href="../doku/sos_modul/benutzer/index.htm" target="_blank">Benutzerhandbuch</a>
Den Inhalt können Sie auf eine beliebige Webadresse ändern.
Das XML-Frontend arbeitet mit den vorhandenen Masken und stellt dort grundlegende Funktionen zur Verfügung. Darüber hinaus bietet das Frontend die Möglichkeit, einzelne Abfragen individuell zu gestalten. Hierzu sind allerdings grundlegende XML-Kenntnisse erforderlich. Außerdem gibt es für den Betrieb gewisse Einschränkungen.
Ein großer Vorteil des XML-Frontends ist, dass Anwender sich ihre Bericht im XML-Format herunterladen können und ohne Datenbankkenntnisse ihre Berichte "maßschneidern" können.
Außerdem arbeitet das XML-Frontend asynchron, d.h. die neuen Servlets können (bislang über die URL) von beliebigen Stellen aus aufgerufen werden. Es ist z.B. damit möglich, auf beliebte Bericht mit gesetzten Parametern einen Bookmark zu legen.
Zunächst muss für das Ergebnis ein neues Stylesheet erzeugt werden. Als Vorlage für Masken können Sie das Muster-Stylesheet
$SUPERX_DIR/webserver/tomcat/webapps/superx/xml/maske_html_ns.xsl
(bzw.
maske_html_ie.xsl
mit speziellen Tags für den Internet Explorer von Microsoft) verwenden, für Ergebnistabellen können Sie das Muster-Stylesheet
$SUPERX_DIR/webserver/tomcat/webapps/superx/xml/tabelle_html.xsl
verwenden. Speichern Sie das Stylesheet unter einem anderen Namen im gleichen Verzeichnis ab, und ändern Sie das Stylesheet. Dann fügen Sie das Stylesheet in die Tabelle
sx_stylesheets
ein.
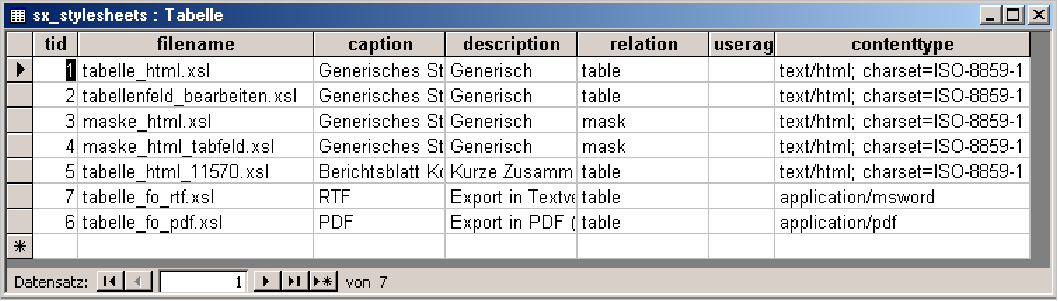
Das Beispiel zeigt einige Styleheets, das erste ist bereits Teil des Kernmoduls, das fünfte befindet sich im COB-Modul. Zu den Feldern:
• filename kennzeichnet den Dateinamen relativ zum Verzeichnis $SUPERX_DIR/webserver/tomcat/webapps/superx/xml .
• caption dient als Kurzüberschrift, die im Ergebnisblatt als Button angezeigt wird.
• description stellt einen Erläuterungstext für den Button dar.
• relation bezieht sich auf die Beziehung des Stylesheets; mögliche Werte sind "mask" für eine Maske und "table" für Tabelle.
• useragent beitet die Möglichkeit, ein Stylesheet für spezielle Lesegeräte anzubieten, z.B. WAP-Handys oder Braille-Zeilen.
• contenttype entspricht dem useragent und kennzeichnet den content-type , der dem Lesegerät im http-header übermittelt werden soll. Möglich sind derzeit die obigen Varianten (svg oder excel sind in Vorbereitung).
Konkret arbeitet SuperX so: Wenn einer Abfrage ein oder mehrere Stylesheets zugeordnet sind, dann werden die in der Reihenfolge angezeigt, in der sie definiert sind. Wenn kein Stylesheet definiert ist, dann wird das Standard-Stylesheet von SuperX benutzt: maske_html_ie.xsl bzw maske_html_ns.xsl für Masken sowie tabelle_html.xsl für Tabellen.
Die Zuordnung eines Stylesheets geschieht in der Tabelle sx_mask_style . Der Tupelidentifier des Stylesheets wird in der Tabelle sx_mask_style im Feld stylesheet_id eingetragen.
|
Das Beispiel zeigt, daß die beiden oben beschriebenen Stylesheets der Maske 11690 zugeordnet werden. |
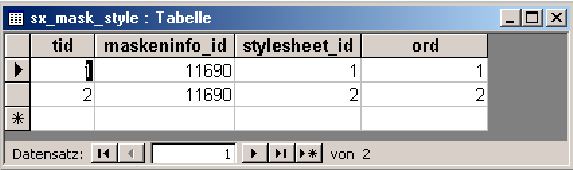
|
Das Feld ord kennzeichnet die Reihenfolge der anzubietenden Stylesheets. Wir sehen hier, dass zuerst das generische Standard-Stylesheet angezeigt wird, und dann das Stylesheet Nr.2.
Defaultmäßig sind die Stylesheets für html (Druckversion in neuem Fenster), xml und text in jeder Ergebnistabelle enthalten. Die Stylesheets für rtf und pdf müssen in der obigen Tabelle zugeordnet werden - dies ist sinnvoll, da die Standard-Stylesheets zunächst mit der in Frage kommenden Maske erprobt werden muss. Im PDF-Format z.B. muss man die Spaltenbreite nach der Textlänge bestimmen. Und das RTF-Fromat ist aufgrund des "experimentellen" Status von Jfor ebenfalls noch prüfungsbedürftig. In OpenOffice Version 1.1.x ist der erzeugte RTF-Code zum Beispiel unansehnlich, in Microsoft Word dagegen besser.
Der Vorteil von XML-Berichten ist, dass sie sich an individuelle Lesegeräte anpassen lassen. So können Sie die Standardoberfläche automatisch für das jeweilige Lesegerät anpassen und dadurch ganz individuelle Designs erzielen, z.B. auch für barrierefreie Angebote.
Das folgende Beispiel zeigt dies anhand des textbasierten HTML-Browsers lynx , der sich (zumindest am Anfang) gut zum Testen für barrierefreie Angebote eignet.
Klicken Sie jeweils auf die Grafik, um sie zu vergrößern.
|
Die rechte Abbildung zeigt die SuperX-Homepage in einer Konsole im Browser lynx . |
|
|
Wir gehen auf das XML-Frontend, und erhalten die Anmeldemaske. Die Frame-Tags ignorieren wir. |
|
|
Nach erfolgreicher Anmeldung erscheint das Menü aus dem Themenbaum. Wir wählen hier als Beispiel die Abfrage Benutzer von SuperX . |
|
|
Nun wird die Maske von dieser Abfrage angezeigt. Bei Kombinationsfeldern gehen wir auf das Feld, und drücken die Return-Taste. Es erscheinen die Auswahleinträge. Zum Abschluss gehen wir auf "Abschicken". |
|
|
Es erscheint die Ergebnisanzeige. Dies sieht natürlich noch nicht besonders gut aus, weil textbasierte Browser und Tabellen sich nicht gut vertragen. Via Stylesheet lassen sich aber ganz übersichtlich Darstellungen entwerfen. |
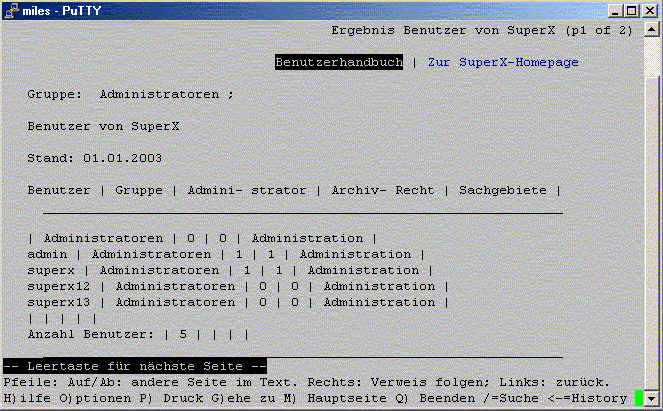
|
Das Beispiel zeigt, dass durch XML und XSL keine Grenzen bei der Gestaltung von Benutzeroberflächen für SuperX existieren. Die obigen Stylesheets befinden sich als Muster im Verzeichnis $SUPERX_DIR/webserver/tomcat/webapps/superx/xml .
Wein kleiner Tipp noch für lynx: Wenn Sie das produzierte html überprüfen wollen, dann starten Sie lynx wie folgt:
lynx -trace http://localhost:8080/superX/xml/
Eine Logdatei lynx.trace wird in das aktuelle Verzeichnis geschrieben.
Das XML-Frontend arbeitet zwar ähnlich wie das Applet, aber es gibt ein paar wichtige Unterschiede. Die Felder einer Maske werden in einem Durchgang aufgebaut, während das Applet die Maskenfelder interaktiv füllt. Dies führt zu folgenden Einschränkungen:
• Es ist im XML-Frontend nicht möglich, im relation-Feld in Felderinfo dynamisch auf den Inhalt eines anderen Feldes (mit <<Feldname>>) zu verweisen.
• Es gibt keine Möglichkeit, den Organigramm-Stand zu verändern
• Der Institut-Button zeigt auch bei der art 4 nur die Einträge an, bei denen "lehre" = 1 gesetzt ist, d.h. die Lehreinheiten und Fakultäten. Alles andere würde zu einer starken Verlangsamung führen (gilt nur bei Organigrammen von über 500 Einträgen).
• Die Mehrfachauswahl ist in html über ein spezielles Listenfeld möglich, dass derzeit aber nur der Internet Explorer unterstützt, nicht Mozilla oder Netscape.
• Das XML-Frontend ist recht langsam und nach unserer Erfahrung auch recht instabil; zukünftige SuperX-Versionen werden sich dieses Problems annehmen.
Das XML-Frontend bietet gegenüber dem Applet einige Erweiterungen, die insbesondere für aufwändiger gestaltete Webapplikationen nützlich sind:
• Die Ergebnissseiten werden nicht komplett geladen, sondern im Rahmen von frei definierbaren Intervallen, z.B. 30 Datensätze pro Seite. Am Seitenende wird dann eine Navigationsmöglichkeit gelifert (Vorherige Seite / Nächste Seite). Der Intervall wird in $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/web.xml definiert (Parameter maxOffset ).
• Die Ergebnisseiten können verlinkt werden, über spezielle Navigationsspalten (siehe Entwicklerhandbuch, Kap. "Navigationsspalten im XML-Frontend").
• In Feldern können Links zu anderen Masken definiert werden (Feldart 15).
Im XML-Frontend können Abfragen direkt nach html (Druckversion), XML, PDF oder XLS (->Excel) exportiert werden. Die zugehörigen Stylesheets lauten:
|
html |
$SUPERX_DIR/webserver/tomcat/webapps/superx/xml/tabelle_html_p.xls |
|
|
$SUPERX_DIR/webserver/tomcat/webapps/superx/xml/tabelle_fo_pdf.xsl |
|
XLS |
$SUPERX_DIR/webserver/tomcat/webapps/superx/xml/tabelle_xls.xsl |
Der PDF-Konverter arbeiten mit der OpenSource-Bibliothek FOP, der Excel-Konverter mit POI. Die Vorlagen können als Grundlage für eigene Stylesheets verwendet werden. Wir verweisen hier auf der SuperX-Entwicklerhandbuch.
Der PDF-Export funktioniert zwar technisch, aber leider sehen die Ergebnisse oft nicht "schön" aus, da die Berichte in SuperX generell über die Seitenbreite hinaus gehen. Wir empfehlen daher, die Exporte nur bei speziell geeigneten Berichten (mit weniger Spalten) zu verwenden. Außerdem gibt es für Volltexte keine Silbentrennung.
Der XLS-Export wurde mit MS Excel (95-2003) und OpenOffice (1.1.3-2.x) getestet. Da die Produkte automatisch auf Seitenbreite skalieren können, sieht der Export hier deutlich besser aus.
Außerdem können grundlegende Lauyoutelemente wie Kopf- und Fußzeilen und Seitenzahlen individuell angepasst werden, ohne zwingend XSLT-Kenntnisse zu haben.
Schauen Sie dazu im Abschnitt Individuelle Kopf/Fußzeilen unten.
Es ist möglich, auf einzelnen Masken Felder für einzelne Gruppen zu verstecken. Dies dient z.B. dazu, das Feld "Hörerstatus" für die Gruppe "Externe Anwender" auszublenden, d.h. es würde immer "Alle" selektiert. Um dies zu realisieren geht man wie folgt vor:
• Ermitteln Sie zuächst die Feldnummer mit der Maske "Administration"->Masken -> Felder -> Feld suchen. Die Nummer steht in der Spalte "tid".
• Öffnen Sie die Maske "Administration-> Tabelle suchen", als Stichwort geben Sie "pref" ein. Es erscheinen ein Listen- und ein Detailformular für die Tabelle:
Im Listenformular können Sie Datensätze überblicken und neue (mit dem "+"-Button) anlegen.
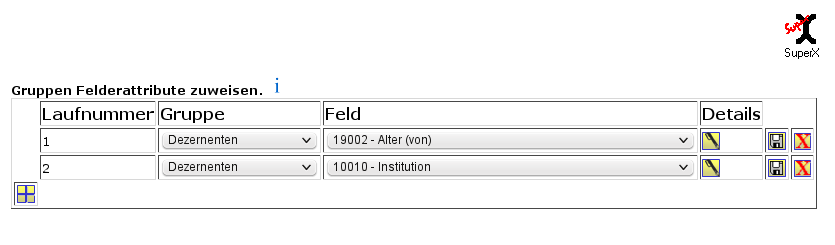
Mit Klick auf den Bearbeitungs-Button kommen Sie zum Detailformular, wo Sie die Voreinstellung "Versteckt" wählen können.
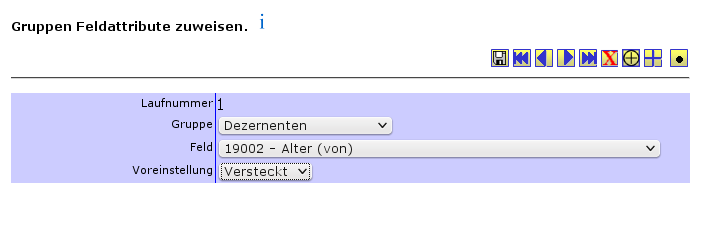
Damit ist das Feld für die jew. Gruppe versteckt.
Manche Masken haben Vorbelegungen, die bei der Hochschule nicht passen, z.B. Hörerstatus "Alle" im Bereich Studierende. Die in den jeweiligen Komponenten ausgelieferten Masken lassen sich zwar ändern, aber beim Einspielen eines neuen Releases würden diese überschrieben. Um dies zu vermeiden gibt es zwei Wege:
• Sie kopieren die Maske in einen eigenen Nummernkreis, dann ist sie vor Upgrades "geschützt"
• Sie ändern die Maske, und führen danach eine Customize -Regel ein, die nach jedem Upgrade ausgeführt wird.
Beide Varianten haben Vor- und Nachteile. Die erste Variante ist besser, wenn Sie nur eine Maske ändern wollen, und ggf. auch noch andere Layouts (z.B. auch Spaltenlayouts der Ergebnistabelle) ändern wollen. Die zweite Variante ist besser, wenn Sie auf einen Schlag mehrere Masken bzgl. einer Kleinigkeit ändern wollen. Das obige Beispiel "Hörerstatus" wäre also besser mit der zweiten Variante lösbar, weil es das Feld in vielen Masken gibt. Hier ein Beispiel wie man das macht:
Ändern Sie die Feldvorbelegung über die Maske Administration-> Masken -> Felder -> "Feld suchen", z.B. beim Feld "Hörerstatus" in der Maske "Studierende und Studienanfänger (Zeitreihe)":
Bisheriger Wert in Spalte Defaultwert:
<<SQL>> select apnr, eintrag from hoererstatus where eintrag='alle';
Neuer Wert:
<<SQL>> select apnr, eintrag from hoererstatus where eintrag='Haupthörer';
Speichern Sie die Änderung, und testen Sie die Maske. Wenn das Ergebnis Sie zufrieden stellt, können Sie es wie folgt vor Änderungen durch Releases schützen:
Erzeugen Sie eine Datei $SOS_PFAD/conf/customize.sql
und schreiben Sie den Inhalt hinein:
--Änderung xx.xx.xxxx Maskenvorbelegung von Hörerstatus "alle" auf Haupthörer ändern:
update felderinfo set defaultwert='<<SQL>> select apnr, eintrag from hoererstatus where eintrag=''Haupthörer'' where name='Hörerstatus' and tid=16004;
Damit wird diese Änderung nach jedem Upgrade ausgeführt. Sie können die Änderung auch direkt für alle Masken vornehmen, indem Sie die Where-Bedingung " and tid=16004 " entfernen.
Hier noch ein Beispiel für das Feld "Status": wir ändern den Default von "Alle ohne Beurl." nach "Alle ohne Beurl., ohne Exmatr.":
--Änderung xx.xx.xxxx: Standardwert für Feld Status im Bereich Studierende: alle ohne beurl., ohne exmatr.
update felderinfo set defaultwert='<<SQL>> select apnr,eintrag from sos_status where eintrag=''Alle ohne Beurl., ohne Exmatr.''' where name='Status'
and tid between 16000 and 16999;
Mit dem Kernmodul 3.1 bzw. HISinOne 3.0 lassen sich Masken auch browserbasiert entladen und laden. Dazu wird das Austauschformat XUPDATE sowie das zugehörige Servlet benutzt. Gehen Sie dazu in den Menüpunkt Webanwendung Manager -> Masken-Sicherung.
Geben Sie in das Feld "oder Spezialparam:" den Wert "maske" ein. Das Feld "Id:" enthält die Masken-ID der Maske, welche gesichert werden soll. Sie erfahren die ID, wenn Sie die Maus über den jew. Menüpunkt zum Öffnen der Maske halten und unten in der Statusleiste des Browsers auf die URL schauen (die Zahl hinter "tid=").
Wenn Sie auf "Absenden" klicken, erhalten Sie den Quellcode im Feld "enter here":
Bitte kopieren Sie den Textinhalt in die Zwischenablage und speichern Sie den Text in einer Textdatei mit der Endung ".xml", z.B. 16690.xml . Diese Datei besitzt das XUPDATE-Format und Sie können sie anderen Hochschulen zur Verfügung stellen oder z.B. in der Berichtsbörse hochladen. Wenn Ihr Server unter UTF-8 arbeitet, sollte der Editor, den Sie benutzen, UTF-8-fähig sein (z.B. Jedit ).
Wenn Sie eine Maske im XUPDATE-Format vorliegen haben, öffnen Sie die Datei mit einem Texteditor, und kopieren Sie den gesamten Inhalt in die Zwischenablage. Wenn Ihr Server unter UTF-8 arbeitet, sollte der Editor, den Sie benutzen, UTF-8-fähig sein (z.B. Jedit ).
Gehen Sie dann in den Menüpunkt Webanwendung Manager -> Masken-Sicherung, und fügen Sie den Textinhalt im Feld unter "enter here" ein. Hier ein Beispiel:
Die Felder darunter können Sie leer lassen, drücken Sie dann direkt auf "Abschicken". Die Maske wird in Ihr System eingespielt.
Danach müssen Sie einmalig im Webanwendung-Manager den Cache leeren und sich dann ab- und neu anmelden. Danach ist die neue Maske unter dem Menüpunkt, der in der Auslieferung vorgegeben wird, sichtbar, z.B. "Studierende".
Wichtiger Hinweis: die Änderung findet ausschließlich in der Datenbank statt, nicht im Dateisystem Ihres Servers. Wenn von der jew. Maske ein Auslieferungszustand existiert (z.B. die Masken der Komponente "Studierende"), dann wird die Maske beim Upgrade der regulären Komponente ggf. wieder auf den Auslieferungszustand zurückgesetzt. Das XUPDATE-Format bietet sich also nur in den Fällen an, in denen Sie direkt mit den Softwareherstellern in Kontakt stehen, oder die Berichtsbörse für individuelle Berichte nutzen.
In diversen Szenarien kann es sinnvoll sein, Masken nicht nur im Browser über die Webanwendung auszuführen, sondern über Kommandozeile, also ohne laufenden Tomcat:
• Für Entwicklungszwecke kann es praktisch sein, wenn man keinen laufenden Tomcat braucht, und Masken z.B. in Eclipse ausführt und debuggen kann
• Große Ergebnisdateien lassen sich leichter erzeugen, weil man von der Webanwendung unabhängig ist und z.B. dem Kommandozeilenaufruf mehr Arbeitsspeicher zuteilt.
• Für die Verteilung von Downloads kann es sinnvoll sein, Berichtsergebnisse in Dateiform zu generieren und im Download-Bereich zu verlinken.
Seit dem Kernmodul 4.2.1 bzw. HISinOne-BI 5.1 ist diese Funktionalität vorhanden, wenn die Kommandozeile eingerichtet ist:
• Unter SuperX: SQL_ENV
• Unter HISinOne-BI: Nutzung der SQL_ENV unter HISinOne-BI , oder Einrichtung einer HISinOne-Umgebung unter Eclipse: https://wiki.his.de/mediawiki/index.php/Einrichtung_einer_HISinOne-Arbeitsumgebung
Damit der Aufruf klappt, muss man in die Umgebungsvariable JDBC_CLASSPATH noch die Tomcat Library servlet-api.jar aufnehmen, diese liegt im jew. Tomcat unter „lib“. Der Aufruf muss in dem Verzeichnis $WEBAPP/WEB-INF ausgeführt werden.
Der Kommandozeilenaufruf sieht unter Linux wie folgt aus:
java -cp "$JDBC_CLASSPATH" $JAVA_OPTS de.superx.bin.ExecuteMask -tid:<<Maskennummer>> -out:<<Ausgabedatei>> -user:<<Benutzerkennung>> "-params:<<Parameter>>" -logger:$SUPERX_DIR/db/conf/logging.properties
Hier ein Beispiel für den Aufruf der Maske "Studierende und Studienanfänger (Zeitreihe)" (tid=16000) als Admin-User unter SuperX und deren Ausgabe in die Datei "test.htm":
java -cp "$JDBC_CLASSPATH" $JAVA_OPTS de.superx.bin.ExecuteMask -tid:16000 -out:test.htm -user:admin "-params:Köpfe oder Fälle ?=1=1&Stichtag=1" -logger:$SUPERX_DIR/db/conf/logging.properties
Hier das gleiche Beispiel für eine Installation in HISinOne-BI:
java -cp "$JDBC_CLASSPATH" $JAVA_OPTS de.superx.bin.ExecuteMask -tid:16000 -out:test.htm -user:admin "-params:Köpfe oder Fälle ?=1=1&Stichtag=1" -logger:$SUPERX_DIR/db/conf/logging.properties
Das Beispiel läßt sich fortführen für andere Ausgabeformate, hier z.B. für PDF:
java -cp "$JDBC_CLASSPATH" $JAVA_OPTS de.superx.bin.ExecuteMask -tid:16000 -out:test.pdf -user:admin "-params:Köpfe oder Fälle ?=1=1&Stichtag=1&stylesheet=tabelle_fo_pdf.xsl&contenttype=application/pdf" -logger:$SUPERX_DIR/db/conf/logging.properties
Das Beispiel zeigt daß über das Params-Argument beliebige Ausgabeformate übergeben werden können, z.B. auch Excel:
java -cp "$JDBC_CLASSPATH" $JAVA_OPTS de.superx.bin.ExecuteMask -tid:16000 -out:test.xls -user:admin "-params:Köpfe oder Fälle ?=1=1&Stichtag=1&stylesheet=tabelle_xls.xsl&contenttype=application/vnd.ms-excel" -logger:$SUPERX_DIR/db/conf/logging.properties
oder als CSV Export:
java -cp "$JDBC_CLASSPATH" $JAVA_OPTS de.superx.bin.ExecuteMask -tid:16000 -out:test.csv -user:admin "-params:Köpfe oder Fälle ?=1=1&Stichtag=1&contenttype=text/csv" -logger:$SUPERX_DIR/db/conf/logging.properties
Über den "Deep-Link"-Button lassen sich beliebige Parameter-Zeichenketten erzeugen und nutzen. Auch Aufrufe von JasperReports sind damit möglich, z.B. ein Studierendenbericht als Excel-Report:
java -cp $JDBC_CLASSPATH $JAVA_OPTS -Xmx2048m de.superx.bin.ExecuteMask -tid:16650 -out:$OUTFILE "-params:maxoffset=1000000&stylesheet=tabelle_16650_semester_geschlecht.jrxml&tablestylesheet=tabelle_16650_semester_geschlecht.jrxml&contenttype=application/vnd.openxmlformats-officedocument.spreadsheetml.sheet" -user:superx -logger:$SUPERX_DIR/db/conf/logging.properties
Bei Datenblattberichten sollte auch der Parameter tablestylesheet übergeben werden.
Unter Eclipse sieht der Aufruf für das erste Beispiel (Ausgabe nach html) so aus:
Und hier die Parameter:
Das Beispiel lässt sich leicht auf andere Plattformen (DOS, Netbeans) übertragen.
Sie können auch Parameter bewußt leer übergeben, indem Sie den Parameter ohne Wert übergeben, hier z.B. den Parameter „Sprache“:
java -cp "$JDBC_CLASSPATH" $JAVA_OPTS de.superx.bin.ExecuteMask -tid:70170 -out:test.htm -user:admin "-params:Stichwort=REPORT&Sprache=" -logger:$SUPERX_DIR/db/conf/logging.properties
Bei der HTML-Darstellung und dem PDF-Export ist auf der ersten Seite im Kopf vorgesehen den Hochschulnamen und die Internetadresse der Hochschule auszugeben. Dies geschieht allerdings nur, wenn diese im System hinterlegt sind. Um die Daten einzugeben oder zu ändern, gehen Sie in der Oberfläche in die Maske "Administration -> Masken -> Beschriftungen suchen". Dort geben Sie bei Stichwort "REPORT" ein.
Feld Sprache muss leer sein.
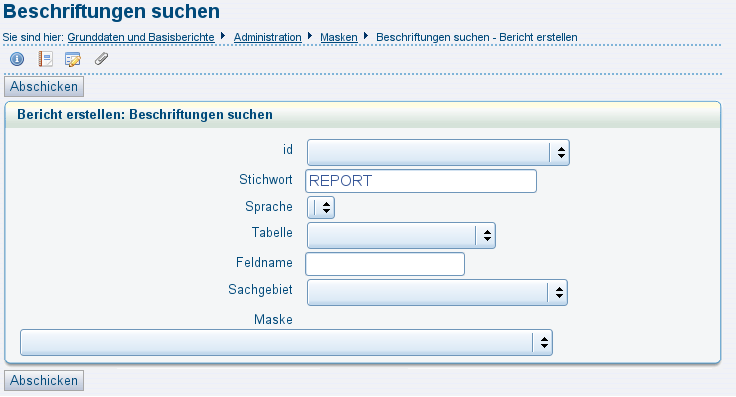
In der Ergebnistabelle sollte nun in der Spalte id jeweils ein Eintrag für "REPORT_HEADING_INSTITUTION" und für "REPORT_HEADING_URL" erscheinen.
Bei "REPORT_HEADING_INSTITUTION" sollte in der Spalte Inhalt (kurz) der Hochschulname stehen und bei "REPORT_HEADING_URL" die Internetadresse der Hochschule.
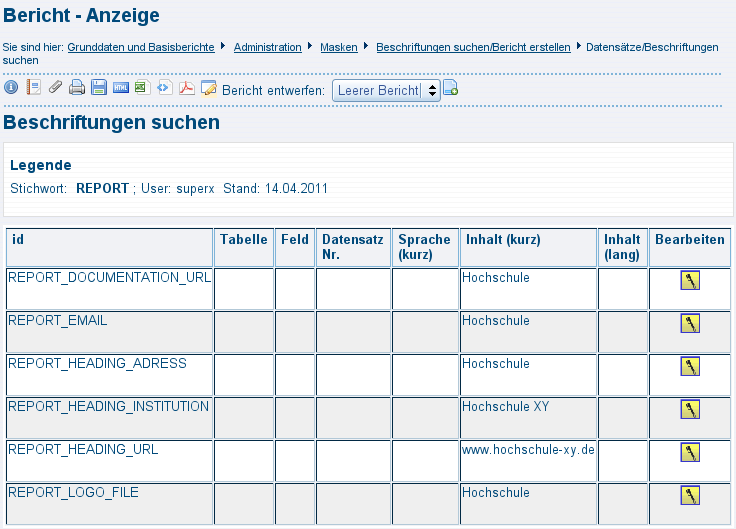
Dies kann über den Button Bearbeiten geändert werden.
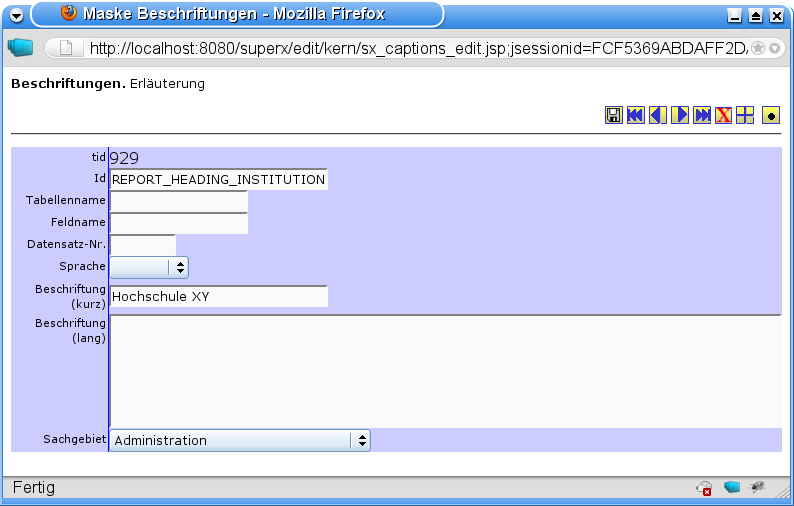
Hier kann bei Beschriftung (kurz) der Inhalt geändert werden. Danach einfach auf Speichern (oben rechts) klicken.Der Hochschulname ist schon voreingestellt.
Dann leeren Sie den SuperX Manager Dann leeren Sie den SuperX Manager Cache
URL der Hochschule
Soll im HTML/PDF-Kopf auch die URL der Hochschule angezeigt werden, ändern Sie die Variable
REPORT_HEADING_URL mit der gleichen Vorgehensweise.
Eigenes Logo
Für das Logo wird als Voreinstellung in der Beschriftung REPORT_LOGO_FILE der Wert bei HISinOne-BI der Wert ../xml/his1/images/logos/hisinone_logo_reports.png , und bei SuperX der Wert ../images/SymbolU.gif ausgeliefert, d.h. in dem Feld "Beschriftung (kurz)" steht der Pfad zur Bilddatei relativ zum Verzeichnis webapps/superx/servlet . Um ein eigenes Logo zu nutzen, können Sie die Grafikdatei z.B. in webapps/superx/images/mein_logo.png speichern, und in der Beschriftung (kurz) speichern Sie " ../images/mein_logo.png ".
Wenn Sie keinen direkten Zugang zum Tomcat Rechner haben, spielen Sie die Datei zunächst mit dem Uploadtool hoch (s.u.)
Dann wie gehabt:
Rufen Sie Adminstration -> Masken-> Beschriftungen suchen auf ,
wählen Sie bei ID REPORT_LOGO_FILE aus und bei Sprache das Feld leeren.
Klicken Sie auf Abschicken und dann bearbeiten.
Machen Sie im Feld "Beschriftung (kurz)" Ihre Änderung und klicken Sie speichern.
Wichtig, die Pfadangabe muss relativ sein, also starten mit
../MANDANTENID/custom/dateiname
Statt MANDANTENID muss Ihre konkrete MandantenID angegeben werden, die im Upload-Tool angezeigt wird. Hie rein Beispiel:
Dann leeren Sie den SuperX Manager Cache
Damit wird der Hochschulname ggfs. URL und Logo schon in Standard-HTML und PDF-Berichten angezeigt.
Für Kopfzeilen in Excel gehen Sie nach dem Abschnitt unten vor.
Derzeit noch nicht ausgewertet werden
REPORT_HEADING_ADRESS=Adressdaten der Hochschule, oder der Name der
Abteilung, die die Berichte rausgibt
REPORT_EMAIL=Kontaktadresse für Berichte
REPORT_DOCUMENTATION_URL=URL für hochschulinterne Doku-Seiten
Um beim Excelexport eine individuelle Kopf/Fußzeile zu nutzen, erzeugen Sie eine Exceldatei mit individueller Kopf/Fußzeile und speichern diese als ExcelVersion bis 2003 ab.
Dateiname vorlage.xls
Laden Sie diese Datei mit dem Uploadtool hoch.
Alternative via XSL:
Schauen Sie in die für das Seitenformat in die Datei $SUPERX_DIR/webserver/tomcat/webapps/superx/xml/pageComponents.xsl ; dort wird im Abschnitt <xls-pageformat> definiert, welche Einträge wie gefüllt werden sollen.
|
Das rechte Beispiel zeigt die Vorgabewerte des Seitenformats einer Excel-Datei. Die Knoten und Attributnamen sollten selbsterklärend sein. |

|
Sie können den gesamten Knoten kopieren in die hochschulspezifische pageComponents_final.xsl -Datei, sie überlagert automatisch die "normale" pageComponents.xsl und ist sofort in allen Berichten aktiv. So können Sie z.B. im Berichtskopf den Hochschulnamen und die Abteilung eintragen.
Einfach nur den Hochschulnamen/URL und Logo anzeigen, geht am einfachsten wie im ersten Abschnitt beschrieben.
Um eine ganz individuelle Kopfzeile für die Berichte im Browser anzulegen, erzeugen Sie testweise lokale auf Ihrem Computer eine Datei htmlheader.htm, die Sie in Ihrem Browser testen können.
(Die Datei braucht nicht auf den Server gespielt zu werden, nur für Sie lokal zum Ausprobieren)
Sie können diese Datei mit HTML gestalten.
Ein einfaches Beispiel
Sie wollen einfach nur den Namen Ihrer Hochschule zentriert über der Tabelle stehen haben,
der Inhalt der Datei kann dann so aussehen.
<h2 align="center">Hochschule XY</h2>
Wollen Sie zusätzlich ein Logo einbinden, laden Sie das Logo mit dem Upload-Tool hoch und definieren htmlheader.htm z.B. so:
<h2 align="center">Hochschule XY<br/>
<img src="/superx/MANDANTENID/custom/logo.gif"></h2>
Statt MANDANTENID nehmen Sie Ihre konkrete MandantenId, die Ihnen im Upload-Tool angezeigt wird.
Wenn die Datei gut aussieht, kopieren Sie den Inhalt in die Zwischenablage.
Allerdings ohne die <html> <body> </body> </html> Tags.
Dann wird der Inhalt ins Repository als Variable HTML_HEADER eingespielt.
Dazu gehen Sie unter Administration auf Tabelle suchen und geben bei Stichwort sx_repository ein.
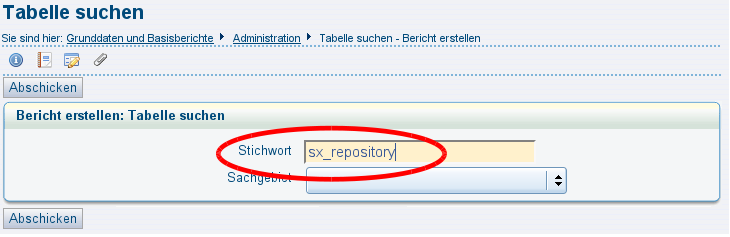
Nach dem Abschicken, klicken Sie bei sx_repository_list auf Bearbeiten.
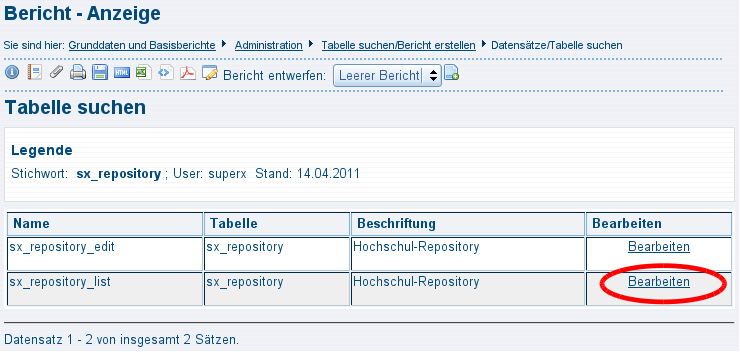
In der Zeile mit HTML_HEADER klicken Sie auf Details.

(Falls die Variable HTML_HEADER nicht gefunden wird, leeren Sie einmal den SuperXManager-Cache und versuchen es erneut.)
Tragen Sie Ihre Vorlage bei Inhalt der Variable ein, speichern Sie und leeren Sie den SuperX-Manager-Cache.
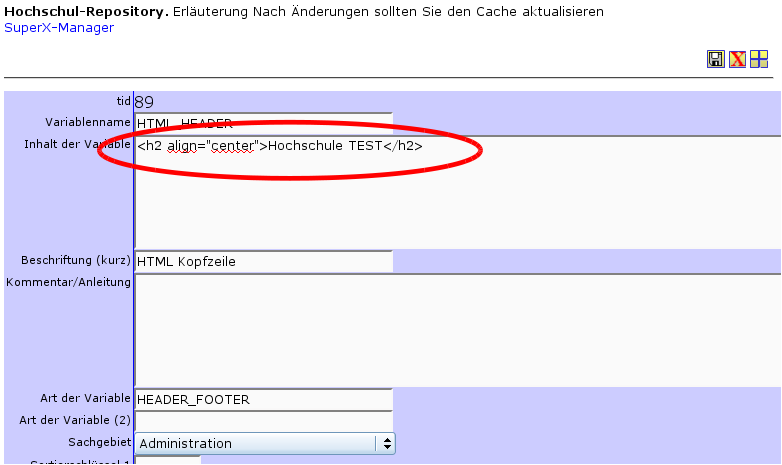
Für eine individuelle Fußzeile legen Sie nach dem gleichen Prinzip eine Datei htmlfooter.htm an und testen Sie sie lokal.
Sie könnten Sie z.B. füllen mit
<p align="center">Datenschutzbestimmungen beachten</p>
Dann steht der Hinweis "Datenschutzbestimmungen beachten" unter den Ergebnistabellen im Browser.
Spielen Sie diese als Variable "HTML FOOTER" im Repository ein.
Einfach nur den Hochschulnamen/URL und Logo anzeigen, geht am einfachsten wie im ersten Abschnitt beschrieben.
Wenn Sie ganz eigene Kop/Fußzeilen entwerfen wollen:
Für die ganz freie Erstellung individueller Kopf-/Fußzeilen muss man eine XSL-Vorlage erstellen und unter der Variablen CUSTOM_PDF ins repository einspielen.
Dazu gehen Sie unter Administration auf Tabelle suchen und geben bei Stichwort sx_repository ein.
Nach dem Abschicken, klicken Sie bei sx_repository_list auf Bearbeiten.
In der Zeile mit CUSTOM_PDF klicken Sie auf Details.
(Falls die Variable CUSTOM_PDF nicht gefunden wird, leeren Sie einmal den SuperXManager-Cache und versuchen es erneut.)
Tragen Sie Ihre Vorlage bei Inhalt der Variable ein, speichern Sie und leeren Sie den SuperX-Manager-Cache.
Bei PDF kann man separat steuern, wie die Kopf-/Fußzeile der ersten Seite und die der weiteren Seite aussehen soll.
Will man die Höhe einer Kopf/Fußzeile ändern, muss man das an der Stelle machen, wo ein entsprechender Kommentar steht.
z.B.
<xsl:template name="first_page_header_height">
<!-- falls Sie die Höhe verändern möchten tragen Sie hier statt 40mm einen anderen Wert ein -->
<fo:region-before extent="40mm" region-name="first-region-before"/>
hier kann man statt 40mm z.B. 60mm eintragen, wenn man ein großes Logo verwendet.
(Der unten im Beispiel angegebene XLM-Header darf nicht fehlen)
Die Gestaltung der Zeilen erfolgt mittels fo bzw. xsl.
Will man z.B. in der Kopfzeile nur den Namen der Hochschule haben, ändert man nach dem entsprechenden Kommentar
<!--hier können Sie die Gestaltung der Kopfzeile der ersten Seite anpassen-->
<fo:block position="absolute" text-align="center">
<fo:inline font-size="16pt">Hochschule XY</fo:inline>
</fo:block>
</xsl:template>
Wichtig ist, dass der <fo:block unten durch ein </fo:block> wieder geschlossen wird und ähnlich der Eintrag <fo:inline> auch mit einem </fo:inline> geschlossen wird.
Möchte man zusätzlich ein Logo einbinden, kann man es mit dem Upload-Tool hochladen und dann z.B. nehmen
<fo:block position="absolute" text-align="center">
<fo:inline font-size="16pt">Hochschule XY</fo:inline>
<fo:external-graphic src="MANDANTENID/custom/logo.gif"></fo:external-graphic>
</fo:block>
</xsl:template>
Statt MANDANTENID tragen Sie Ihre konkrete MandantenID ein, die vom Upload-Tool angezeigt wird.
Möchten Sie beispielweise in einer Fußzeile
Das Erstellungsdatum, die aktuelle Seitenzahl sowie die Gesamtzahl der Seiten haben, könnte der Eintrag für die Fußzeilen so ausshen
<!--hier können Sie die Gestaltung der Fußzeile der ersten Seite anpassen-->
<fo:block>
<fo:inline align="left" font-size="8pt" space-end="224mm">
Erzeugungsdatum: <xsl:value-of select="/ergebnisse/@datum" />
</fo:inline>
<fo:inline align="right" font-size="8pt">
<fo:page-number />/<fo:page-number-citation ref-id="endofdoc" />
</fo:inline>
</fo:block>
Es folgt nun eine komplette Beispieldatei mit den Standardeinstellungen, die Sie als Vorlage nutzen und anpassen können.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!-- falls UTF-Encoding verwendet wird bei encoding UTF-8 eintagen-->
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:ext1="de.memtext.util.DateUtils"
xmlns:ext2="java.util.Date"
xmlns:string="java.lang.String"
xmlns:HtmlUtils="de.superx.util.HtmlUtils"
xmlns:fo="http://www.w3.org/1999/XSL/Format">
<!--ERSTE SEITE - KOPFZEILE -->
<xsl:template name="first_page_header_height">
<!-- falls Sie die Höhe verändern möchten tragen Sie hier statt 40mm einen anderen Wert ein -->
<fo:region-before extent="40mm" region-name="first-region-before"/>
</xsl:template>
<xsl:template name="first_page_header">
<!--hier können Sie die Gestaltung der Kopfzeile der ersten Seite an
passen-->
<fo:block position="absolute" text-align="end">
<fo:external-graphic>
<xsl:attribute name="src"><xsl:text>servlet/</xsl:text><xsl:call-template name="logo_path"></xsl:call-template></xsl:attribute>
</fo:external-graphic>
</fo:block>
</xsl:template>
<!-- ERSTE SEITE - FUSSZEILE -->
<xsl:template name="first_page_footer_height">
<!-- falls Sie die Höhe verändern möchten tragen Sie hier statt 10mm einen anderen Wert ein -->
<fo:region-after extent="10mm" region-name="first-region-after"/>
</xsl:template>
<xsl:template name="first_page_footer">
<!--hier können Sie die Gestaltung der Fußzeile der ersten Seite anpassen-->
<fo:block>
<fo:inline align="left" font-size="8pt" space-end="224mm">
Erzeugungsdatum: <xsl:value-of select="/ergebnisse/@datum" />
</fo:inline>
<fo:inline align="right" font-size="8pt">
<fo:page-number />/<fo:page-number-citation ref-id="endofdoc" />
</fo:inline>
</fo:block>
</xsl:template>
<!-- AB SEITE 2 KOPFZEILE -->
<xsl:template name="rest_header_height">
<!-- falls Sie die Höhe verändern möchten tragen Sie hier statt 10mm einen anderen Wert ein -->
<fo:region-before extent="10mm" region-name="rest-region-before"/>
</xsl:template>
<xsl:template name="rest_page_header">
<!--hier können Sie die Gestaltung der Kopfzeile ab Seite 2 anpassen--
>
<fo:block>
<fo:inline align="left" font-size="8pt" > </fo:inline>
</fo:block>
</xsl:template>
<!-- AB SEITE 2 - FUSSZEILE -->
<xsl:template name="rest-region-after-height">
<!-- falls Sie die Höhe verändern möchten tragen Sie hier statt 10mm einen anderen Wert ein -->
<fo:region-after extent="10mm" region-name="rest-region-after"/>
</xsl:template>
<xsl:template name="rest_page_footer">
<!--hier können Sie die Gestaltung der Fußzeile ab Seite 2 anpassen-->
<fo:block>
<fo:inline align="left" font-size="8pt" space-end="224mm">
Erzeugungsdatum: <xsl:value-of select="/ergebnisse/@datum" />
</fo:inline>
<fo:inline align="right" font-size="8pt">
<fo:page-number />/<fo:page-number-citation ref-id="endofdoc" />
</fo:inline>
</fo:block>
</xsl:template>
</xsl:stylesheet>
Falls beim Aufruf einer PDF-Datei folgender Fehler kommt:
de.superx.common.DBServletException: Konnte XSL-Datei file:////home/superx/tomcat_sx/webapps/superx/xml/tabelle_fo_pdf.xsl nicht kompilieren
bedeutet dies, dass Ihre CUSTOM_PDF vorlage nicht der XSL-Syntax entspricht. Korrigieren Sie dies ggfs. anhand des Beispiels schrittweise
Für die Gestaltung eigener Kopf/Fußzeilen oder bei der Entwicklung eigener Maskenstylesheets kann es nötig sein, eigene Dateiein auf dem Server zu hinterlegen.
Wenn man Zugriff auf das Dateisystem des Webservers hat, kann man dies natürlich manuell machen, neu ist jetzt aber die Möglichkeit auch Dateien per Browser hochzuladen.
Eigene Dateien werden u.a. aus Sicherheitsgründen in ein eigenes Verzeichnis gelegt
webapps/superx/MANDANTENID/custom
ohne Mandantenbetrieb webapps/superx/default/custom
(falls noch nicht existiert wird das Verzeichnis vom Servlet angelegt)
Um das Upload-Servlet nutzen zu können, muss zunächst die web.xml angepasst werden.
Für das Upload-Servlet sind Ergänzungen in der web.xml nötig (falls noch nicht vorhanden).
Unter servlets
<servlet>
<servlet-name>SuperXUpload</servlet-name>
<servlet-class>de.superx.servlet.SuperXUpload</servlet-class>
<init-param>
<!--MandantenID-->
<param-name>default</param-name>
<!--Filter * vorlage.xls,*.xsl-->
<param-value>vorlage.xls,*.gif</param-value>
</init-param>
<init-param>
</servlet>
Für jeden Mandanten,der das Upload-Servlet nutzen soll, muss es einen Parameter geben.
Wenn es für einen Mandanten keinen param-Eintrag gibt, kann er das Upload-Servlet nicht benutzen.
Ohne Mandantenbetrieb ist es der param-name einfach nur default wie oben, bei zwei Mandanten FH_TEST1 und FH_TEST2
<init-param>
<param-name>FH_TEST1</param-name>
<param-value>vorlage.xls,*.gif,*.png,*.jpg,*.htm</param-value>
</init-param>
<init-param>
<param-name>FH_TEST2</param-name>
<param-value>vorlage.xls,*.gif,*.png,*.jpg,*.htm</param-value>
</init-param>
Als Parameter-Value wird eingetragen, welche Dateien/Dateiarten, die Hochschulen hochladen können sollen.
Weiterhin in der web.xml
Unter servlet-mapping
<servlet-mapping>
<servlet-name>SuperXUpload</servlet-name>
<url-pattern>/servlet/SuperXUpload</url-pattern>
</servlet-mapping>
Rufen Sie unter Administration / Upload auf.
Wenn Sie Abschicken anklicken, sehen Sie ein Protokoll über Uploads und ganz oben ist ein Link zum UploadServlet.
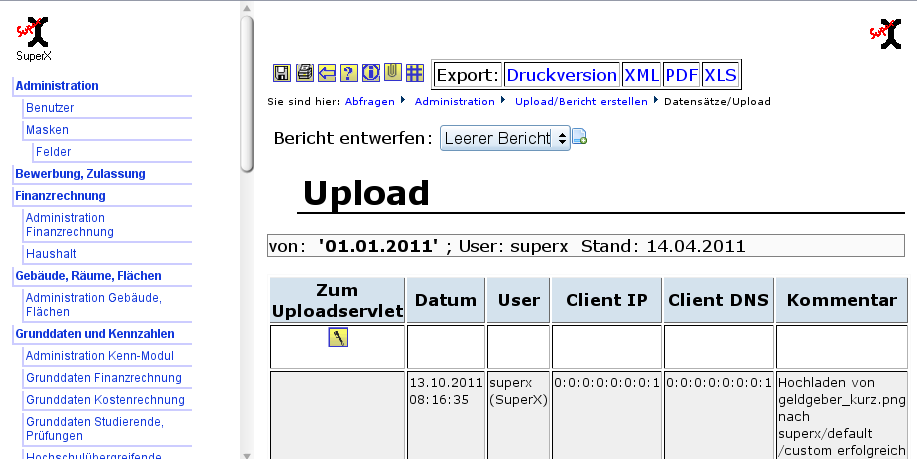
Das Upload-Servlet gibt viele Infos aus, wie Ihre MandantenID oder erlaubte Dateien.
Sie können maximal vier Dateien gleichzeitig hochladen.
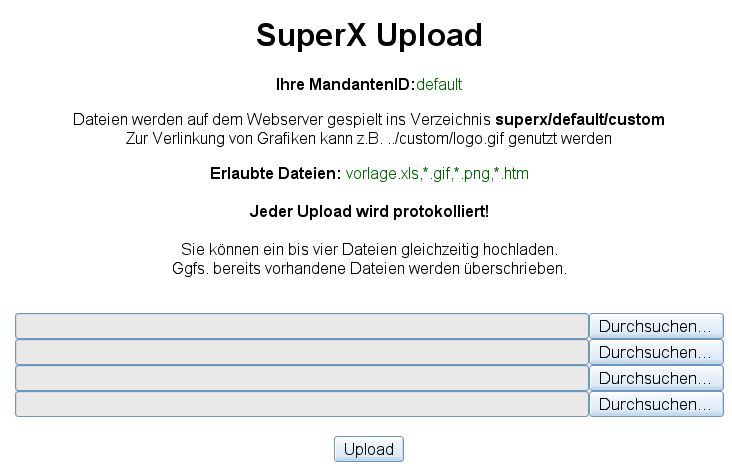
Jeder Upload wird einschließlich Dateiname,Username,Zeitpunkt und IP-Nummer protokolliert!
Nach dem Upload erhalten Sie eine Bestätigung.
Wenn eine Hochschule eigene XSL-Stylesheets mittels upload-Funktion nutzen möchte, sind zwei Dinge zu beachten:
1. Freigabe für *.xsl-Dateien muss in der web.xml eingetragen sein (s.o.)
2. Die Stylesheets werden in das Verzeichnis tomcat/webapps/superx/MANDANTENID/custom geladen, daher müssen in dem Stylesheets Links relativ sein.
z.B. statt standardmäßig <xsl:import href="xsl_functions.xsl" />
<xsl:import href="../../xml/xsl_functions.xsl" />
3.
filename-Eintrag in SuperX-Tabelle sx_stylesheets muss auch relativ sein,
z.B. ../custom/MANDANTENID/maske_html_M1.xsl
Es ist in SuperX mit dem Kernmodul 3.5 möglich, einzelne SuperX Masken und Ergebnistabellen in eigene Web-Präsenzeen einzubetten. Es werden dabei direkte Hyperlinks auf das SuperX-Servlet genutzt, d.h. unter Umgehung der normalen Menüstruktur in SuperX. Da bei jedem Zugriff die Authentifizierung und die jew. Rechte überprüft werden, ist dies auch sicherheitstechnisch kein Problem.
Wir erzeugen einen HTML-Hyperlink nach dem Muster
http://<<Pfad zum SuperX-Servlet>>?Feld1=Wert1&Feld2=Wert2...
Beim Pfad zum SuperX-Servlet gibt es drei Möglichkeiten:
|
Pfad zum Menü (Themenbaum) |
http://<<Servername>>:<<Port>>/superx/servlet/SuperXmlAnmeldung |
|
Pfad zur Maske |
http://<<Servername>>:<<Port>>/superx/servlet/SuperXmlMaske |
|
Pfad zur Tabelle |
http://<<Servername>>:<<Port>>/superx/servlet/SuperXmlTabelle |
Der Pfad zum Menü liefert ein HTML-Menü zurück, der Pfad zur Maske eine Maske. Der Pfad zur Tabelle liefert direkt die gewünschte Tabelle. Als erster Parameter sollte bei Masken und Tabellen der Parameter "tid=...." übergeben werden, dies ist die Maskennummer.
Diese Hyperlinks können wir in eine vorhandene Webpräsenz einbauen, Anwender, die (noch) nicht authentifiziert sind, müssen sich beim ersten Aufruf der URL anmelden, und werden dann zur gewünschten Seite weitergeleitet. Wenn mehrere Seiten aufgerufen werden sollen, müssen die Anwender allerdings für den Applikations-Server Cookies erlauben.
Das allgemeine Vorgehen ist sehr einfach, das Problem liegt nur im Detail: wir müssen für die Konstruktion des Hyperlinks die Schlüssel der zu übergebenden Felder kennen, und wir müssen alle Sonder- und Leerzeichen in Feldnamen oder Werten entfernen / abfangen. Wir können aber zur Erleichterung der Arbeit die Lesezeichen-Funktion oder Schlüsselanzeige von der Webanwendung nutzen.
Nehmen wir an wir wollen direkt auf folgende Seite verlinken:
Es wird das Servlet SuperXmlTabelle mit den Parametern "Köpfe oder Fälle = Köpfe" etc. aufgerufen.
|
Die zugehörige URL können wir durch den Lesezeichen-Button

|
|
|
Mit Klick auf den blauen Link mit der Rechten Maustaste können Sie den Link in die Zwischenablage kopieren: |
|
|
Der Text in der Zwischenablage ist ein Javascript-Aufruf, der den Komfort im normalen Lesezeichen erhöht. Wir benötigen aber nur das Ergebnis der Anweisung, das in der Variablen "url" steht. |
javascript:url="http:...encodeURIComponent(p[i].k);if(window.oeffne)oeffne(url);else%20self.location.href=url;
|
(Zeilenumbrüche bitte ignorieren, der Link besteht aus nur einer Zeile)
|
Ersetzen Sie den Passus "if(window.oeffne)oeffne(url);else%20self.location.href=url;" durch "alert(url);". |
javascript:url="http:...encodeURIComponent(p[i].k);alert(url)
|
|
Rufen Sie das Lesezeichen in einem leeren Browserfenster auf. Es erscheint eine Dialogbox mit einer Adresse, z.B. |
http://localhost:8080/superx/servlet/SuperXmlTabelle?tid=16160&K%C3%B6pfe%20oder%20F%C3%A4lle%20%3F=1%3D1&Stichtag=1&Seit%20Semester=20072&F%C3%A4cher=230&F%C3%A4cher-Sicht=k_stg&Studiengang-Sicht=sos_lstgab&Staatsangeh%C3%B6rigkeit-Sicht=sos_staat_astat&Hochschulzugangsber.=hzbart%20in%20%281%2C2%2C5%2C6%29&H%C3%B6rerstatus=1%3D1
|
Markieren Sie den Text, und kopieren Sie den Link mit STRG-c in die Zwischenablage. Testen Sie den Link in einem leeren Browserfenster. In manchen Browsern kann es Probleme wegen Leerzeichen im Pfad geben, im Zweifelsfall ersetzen Sie Leerzeichen durch "%20". Wenn die Anzeige funktioniert, können Sie die URL in einen "echten" Hyperlink (" <a href='...' ... " einbauen.
Analog können Sie auch auf Masken verlinken, die jew. Felder sind dann entsprechend vorbelegt, ermöglichen dem User aber dann, diese oder andere Parameter zu ändern, z.B.:
<p>Dies ist ein <a href= "javascript:document.location= unescape ('http://mercury:8080/superx/servlet/SuperXmlMaske?tid=16340&K%C3%B6pfe%20oder%20F%C3%A4lle%20%3F=studiengang_nr%20%3D%201%20and%20fach_nr%20%3D%201&Stichtag=0&Seit%20Semester=20061&bis%20Semester=20061&F%C3%A4cher-Sicht=k_stg&Status=1%2C2%2C3%2C5%2C6&H%C3%B6rerstatus=1%3D1&Aggregierung%20Fach=10');">Test einer Maske</a></p>
Hier ist der Link auf das Servlet SuperXmlMaske eingetragen.
Wenn Sie eine Tabelle direkt in einem speziellen Layout anzeigen wollen, können Sie auch Layoutparameter übergeben; wenn Sie ein spezielles Stylesheet nutzen wollen, fügen Sie den Parameter "&stylesheet=<<Pfad zum Stylesheet>>&contenttype=<<Mime-Type>>" an, z.B.
http://localhost:8080/superx/servlet/SuperXmlTabelle?tid=16160&Köpfe oder Fälle %3F=1%3D1&Stichtag=1&Seit Semester=20072&Fächer=230&Fächer-Sicht=k_stg&Studiengang-Sicht=sos_lstgab&Staatsangehörigkeit-Sicht=sos_staat_astat&Hochschulzugangsber.=hzbart in (1%2C2%2C5%2C6)&Hörerstatus=1%3D1 &stylesheet=tabelle_fo_pdf.xsl&contenttype=application/pdf
Folgende Layoutparameter sind immer möglich:
• Generisches Standardlayout HTML: stylesheet=tabelle_html.xsl&contenttype=text/html
• Generisches Standardlayout HTML Druckversion: stylesheet=tabelle_html_p.xsl&contenttype=text/html
• Generisches Standardlayout PDF: stylesheet=tabelle_fo_pdf.xsl&contenttype=application/pdf
• Generisches Standardlayout XML: stylesheet=tabelle_xml.xsl&contenttype=text/xml
• Generisches Standardlayout Excel: stylesheet=tabelle_xls.xsl&contenttype=application/vnd.ms-excel
• Wenn Sie eigene XSL-Stylesheets nutzen, übergeben Sie analog im Parameter den Namen bzw. Pfad zur xsl-Datei
• Wenn Sie JasperReports nutzen, übergeben Sie analog im Parameter den Namen bzw. Pfad zur jrxml-Datei.
Achtung: eigene Stylesheets werden aus Sicherheitsgründen nur akzeptiert, wenn Sie in der Stylesheetverwaltung der jew. Maske zugewiesen wurden. Sie (oder potentielle Angreifer) können also nicht im Parameter stylesheet beliebige Stylesheets einbinden.
Oben wurde gezeigt, wie man mit Hilfe einer URL eine Ergebnisseite direkt abrufen kann. Nun ist es hier und da sicher sinnvoll, eigene Parameter in einer benutzerdefinierten Maske anzugeben. Das folgende Beispiel zeigt eine Aufrufseite der Universität Bonn. Zunächst wird die Oberfläche gezeigt, und dann die zugehörige Technik dafür.
Die Seite bietet eine Studierenden- eine Personal- und eine Stellenstatistik, wobei einzelne Parameter (Semester, Datum) vom Anwender variiert werden können. Wenn ein Anwender z.B: bei der Voreinstellung "SS 2008" auf den Link "Studierende nach Fach und Abschluss" klicken, gelangen Sie (beim ersten Mal) zu einem Login-Dialog:

Nach dem Login erscheint direkt die Tabelle für das SS 2008:

Die obige Oberfläche wurde durch eine HTML-Seite erzeugt, in die folgende Komponenten eingefügt wurden:
|
Eine Javascript-Methode, die den Aufruf einer URL realisiert mit Parameter realisiert: |
<script language="Javascript" type="text/javascript"> |
Der folgende Quellcode zeigt, wie die Tabelle und darunter die Maske aufgerufen wird:
<form name="Studierende"> <b>Studierende im <SELECT class="maskinputPflicht" id="Sem" NAME="Sem" tabindex="1" ><option class="maskinput" value="20082">WS 2008/2009</option><option class="maskinput" value="20081" selected="true">SS 2008</option></SELECT></b> <br>
<a href="javascript:openWindow('Semester',document.forms['Studierende'].elements[0].options[document.forms['Studierende'].elements[0].selectedIndex].value,'../../servlet/SuperXmlTabelle?tid=16280&'+escape('Köpfe oder Fälle ?')+'=studiengang_nr%20%3D%201%20and%20fach_nr%20%3D%201&Stichtag=1&'+escape('Hörerstatus')+'='+escape('hrst in (select apnr from sos_k_hrst where astat=\'1\')')+'&Status=1%2C2%2C3%2C5%2C6&'+escape('Studiengänge')+'=2');">
Studierende nach Fach und Abschluss</a><br>
<b><a href="javascript:openWindow('Semester',document.forms['Studierende'].elements[0].options[document.forms['Studierende'].elements[0].selectedIndex].value,'../../servlet/SuperXmlMaske?tid=16280&'+escape('Köpfe oder Fälle ?')+'=studiengang_nr%20%3D%201%20and%20fach_nr%20%3D%201&Stichtag=1&'+escape('Hörerstatus')+'='+escape('hrst in (select apnr from sos_k_hrst where astat=\'1\')')+'&Status=1%2C2%2C3%2C5%2C6&'+escape('Studiengänge')+'=2');">
Abfragemaske...</a>
</b>
</form>
Wie Sie sehen werden die Felder mit Sonderzeichen, Hochkommata durch die Javascript-Funktion "escape(...)" umgewandelt, damit der Aufruf korrekt übergeben wird. Das Hochkomma muss darüber hinaus auch durch ein "\" maskiert werden.
Das obige <form> -Element wurde mit relativen URLs erzeugt, d.h. Sie können den Code z.B. in eine Seite http://<<Ihr-Server>>:<<Port>>/superx/xml/public/index.htm übernehmen, und der Code ist direkt lauffähig.
Das Kernmodul enthält außer Administrationsabfragen und Tabellen keinerlei Inhalte. Die Inhalte werden in Form von Modulen hinzugefügt. Dazu gibt es vorgefertigte Installationsscripte .
Die folgende Abbildung zeigt die Architektur von Modulen ab Beispiel vom HISCOB-Modul:
|
Ein Modul besteht auf Datenbankseite aus Abfragen, Hilfstabellen, Datentabellen und Schlüsseltabellen (sowie Prozeduren). Auf Webserver-Seite können auch XSL-Stylesheets vorhanden sein. |
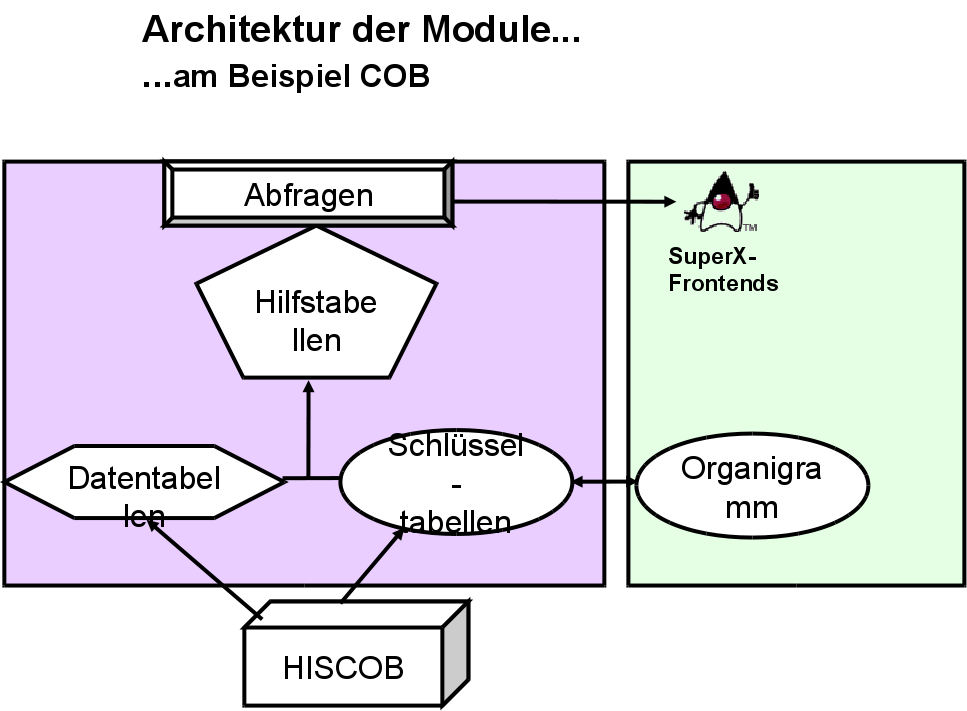
|
Die Abbildung zeigt, dass ein Modul eigene Komponenten nutzt, aber auch auf Teile des Kernmoduls zugreift, z.B. das Orgranigramm - dies macht SuperX zu einem integrierten System. Neben dem Organigramm sind alle anderen Komponenten des Kernmoduls natürlich betroffen, z.B. Themenbaum, Userrechte.
Die Ordnerstruktur eines Moduls spiegelt die Komponenten des Systems wieder. Es gibt je ein Verzeichnis für datentabellen , schluesseltabellen und hilfstabellen .
Die Installation eines Moduls ist in der Dokumentation des jeweiligen Moduls näher beschrieben. Module, die auf dem Kernmodul 2.1 oder höher basieren, haben einen einheitlichen Aufbau.
Seit Version 2.1 werden die Datenbankschemata und Scripte der Module in einem einheitlichen Format zusammengestellt und in einer Datei $SUPERX_DIR/db/module/$MODULNAME/conf/$MODULNAME.xml gespeichert. Das XML-Format hat den Vorteil, dass die Scripte dynamisch für Postgres und Informix erzeugt werden können, und dass die Scripte vereinheitlicht werden. Aus dieser Datei werden die Scripte erzeugt, die das Modul jeweils für Postgres und Informix installieren / updaten /aktualisieren / überprüfen und entfernen. Die folgende Abbildung zeigt das Vorgehen:
|
Aus der xml-Datei werden die jeweiligen Scripte für die Installation, den Update, die Extraktions-, Transformations- und Ladescripte (ETL) und die Deinstallation erzeugt. |
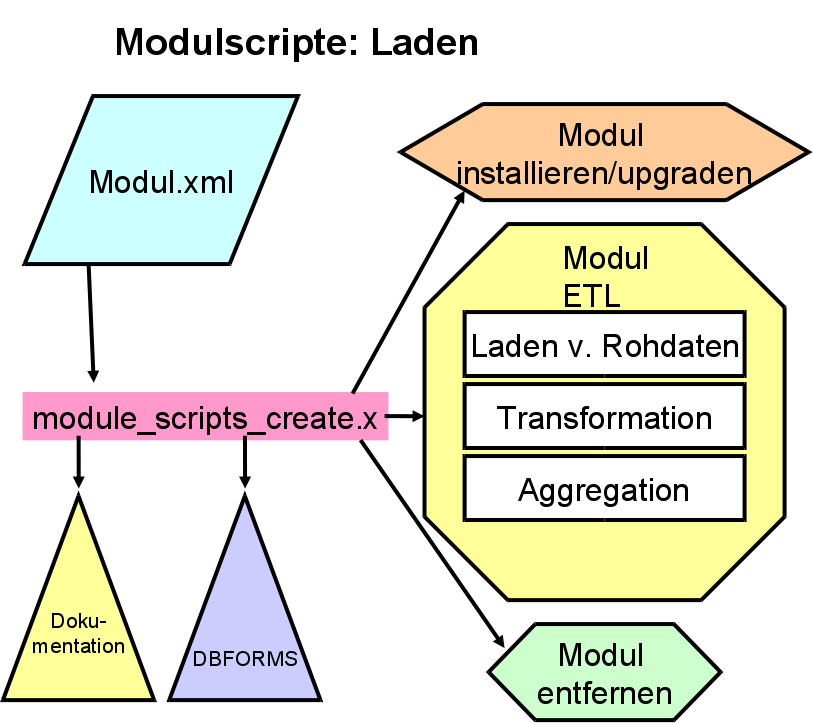
|
Die Modul-Scripte liegen als Shellscripte im Verzeichnis $SUPERX_DIR/db/bin, und sind an anderer Stelle im Detail erläutert.
|
module_install.x <<name>> <<pfad>> z.B.: module_install.x sos $SOS_PFAD |
Installiert ein Modul, d.h. erzeugt die Tabellen, Views, Funktionen und Abfragen. Die Abfragen werden in den Themenbaum eingehängt. |
|
module_etl.x <<name>> <<pfad>> z.B.: module_etl .x sos $SOS_PFAD |
Aktualisiert das Modul, d.h. lädt die Rohdaten, Transformiert sie, und aggregiert die Hilfstabellen. Fehler werden in eine Log-Datei geschrieben, diese kann dann per Mail an einen Admin versandt werden. Wenn das Script erfolgreich durchläuft, wird die Tabelle
systeminfo
aktualisiert. |
|
module_drop.x <<name>> <<pfad>> z.B.: module_ drop .x sos $SOS_PFAD |
Entfernt das Modul bzw. die Tabellen, Views, Funktionen und Abfragen. |
|
module_update.x <<name>> <<pfad>> z.B.: module_ update .x sos $SOS_PFAD |
Ein Modulupdate wird durchgeführt, d.h. eine neue Version des Moduls wird installiert (nicht zu verwechseln mit dem regelmäßigen Update im Sinne eines ETL-Prozesses). |
|
module_scripts_create.x |
Erzeugt via XSL-Transformation die jeweiligen Scripte, die in den obigen Scripten aufgerufen werden, z.B. bau_install_ids.sql für das Installationsscript des Baumoduls beim Informix Dynamic Server. |
Neben den operativen Scripten erzeugt
module_scripts_create.x
auch html-Dateien zur Dokumentation eines Moduls in
$SUPERX_DIR/db/module/<<Modulname>>/conf/<<Modulname>>.html
(auch als rtf-Datei zu Einbindung in Modul-Dokumentationen)
sowie zur Schnittstelle in
$SUPERX_DIR/db/module/<<Modulname>>/rohdaten/<<Modulname>>_unload.html
Darüber hinaus werden auch DBForms-Formulare erzeugt.
Das Vorgehen bei der Installation eines Moduls ist standardisiert. Im folgenden eine Kurzbeschreibung, weiter unten finden Sie das Vorgehen am Beispiel des ZUL-Moduls im Detail.
1. Entpacken Sie das Modul in $SUPERX_DIR
2. Erweiterung der Umgebung in der Datei $SUPERX_DIR/db/bin/ SQL_ENV : fügen Sie den Inhalt der jew. Beispieldatei SQL_ENV_<<Modulname>>.sam in der SQL_ENV an, wenn noch nicht vorhanden, und ändern Sie ggf. Email-Adressen für log- und Fehlermails.
3.
Entladen der Rohdaten; auch hier müssen vorher Umgebungsvariablen zum Vorsystem angepasst werden
(Datei
$<<Modulname>>_LOAD_PFAD
/
<<Modulname>>_ENV
), hier liegt ebenfalls eine
*.sam
-Datei vor
4. Kopieren der Rohdaten nach <<Modulpfad>>/rohdaten. Neuere SuperX-Module haben dafür vorgefertigte Scripte mit dem Namen <<Modulname>>_copy.x (z.B. zul_copy.x )
5.
Bei sehr großen Datenmengen bietet es sich an, die Rohdaten zunächst auf überschaubare kleine Dateien zu kürzen. Das Script
<<Modulname>>_shrink.x
kürzt alle
"*_neu"
-Tabellen auf 100 Zeilen. Sie können dies später mit
<<Modulename>>_unshrink.x
rückgängig machen.
6.
Installieren Sie das Modul mit
<<Modulname>>_erzeugen.x
z.B. mit
zul_modul_erzeugen.x
7.
Wenn die Installation erfolgreich war, können Sie das Modul aktualisieren mit
<<Modulname>>_update.x (ggf. mit Parametern)
z.B. mit
zul__update.x
d.h. die
ETL-Prozesse
werden gestartet (s.u.).
8. Wenn das Modul erfolgreich aktualisiert ist, wird eine Prüfprozedur gestartet, die die Daten plausibilisiert. Fehler und Warnungen finden Sie in der Datei $<<Modulname>>_ERRORDAT .
9. Starten Sie Tomcat neu. Wenn Tomcat auf einem separaten Server installiert ist, müssen Sie vorher die Datei $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/dbforms-config.xml dorthin übertragen.
10. Schritt 7 wird bei jedem SuperX-Update wiederholt. Nun muss der Entladerhythmus geplant werden, und die Cronjobs werden eingerichtet. Es gibt eine Musterdatei $SUPERX_DIR/db/module/<<MODULNAME>>/<<MODUL>>_update_cron.x.sam , benennen sie diese um nach <<MODUL>>_update_cron.x und fügen Sie das Script in die crontab ein.
Zunächst müssen die Rohdaten aus dem Vorsystem entladen werden.
Für das Entladen gibt es ferner zwei Modi: Das "Pull"-Verfahren und das "Push"-Verfahren.
•. Beim "Pull"- Verfahren wird einer Benutzerkennung auf dem SuperX-Rechner Zugriffsrecht auf die SOSPOS-Datenbank gegeben, und die Daten werden via TCP/IP aus dem Basissystem entladen. Bei APP / HISinOne als Quellsystem ist "Pull" das Standardvorgehen.
•. Beim "Push"- Verfahren werden die Entladescripte auf den SOSPOS-Rechner kopiert und dort von einer Benutzerkennung auf dem SOSPOS-Rechner ausgeführt. Die Rohdaten müssen dann auf den SuperX-Rechner kopiert werden. Dieses Verfahren klappt bei Informix unter Unix problemlos, bei Entladen aus Postgres müsste das komplette SuperX-Kernmodul installiert werden.
Am einfachsten ist immer das "Pull"-Verfahren, das mit fast allen Quellsystemen funktioniert und wenig Konfiguration auf dem Quellsystem erfordert. Aufgrund von Sicherheitsvorkehrungen oder Netz-Infrastrukturen wählen aber viele Hochschulen das "Push"-Verfahren. Da derzeit Informix /Unix die gängigste Plattform an Hochschulen ist, ist dies auch kein Problem.
Im Push-Verfahren btw. unter SuperX können Sie mitgelieferte Shellscripte nutzen. Das folgende Beispiel des ZUL-Moduls zeigt das Vorgehen:
Die Entladescripte liegen im Verzeichnis $SUPERX_DIR/db/module/zul/rohdaten und lauten je nach HIS-Systemversion:
zul_unload.x
Die Scripte laufen nur, wenn die entsprechenden Umgebungsvariablen in der Datei ZUL_ENV (im gleichen Verzeichnis, ein Muster liegt vor in ZUL_ENV.sam ) korrekt gesetzt sind, benennen Sie die Musterdatei um nach ZUL_ENV und tragen die richtigen Umgebungsvariablen ein, z.B. den Pfad für $INFORMIXDIR.
ZUL_ENV Die Umgebung für Entladescripte aus ZUL-GX(Auszug)
##Pfad für Entladedaten:
ZUL_PFAD=.; export ZUL_PFAD
##hier muss Unterverzeichnis unl existieren!
#Transaktionen abschalten?
TRANSACTION_OFF=""
export TRANSACTION_OFF
In der ZUL_ENV müssen außerdem folgende Umgebungsvariablen gesetzt werden (defaults sind bereits vorbelegt, aber hier und da müssen Sie sicher ran):
|
|
Nur für Informix gelten: |
|
INFORMIXDIR |
Home-Verzeichnis von Informix |
|
INFORMIXSERVER |
Name des Informixservers |
|
ONCONFIG |
Name der onconfig, wenn auf dem SOS-Rechner mehrere Informix-Instanzen laufen |
|
CLIENT_LOCALE |
Sprachumgebung (wichtig fürs Entladen von Datumsformaten) |
|
SERVER_LOCALE |
dito |
|
|
Nur für Postgres gelten: |
|
PGDATESTYLE |
Datumsformat "German" |
|
PGPORT |
Port vom Postgres-Server, standardmäßig 5432 |
|
PGHOST |
Hostname oder IP-Adresse vom Postgres-Server |
|
PGUSER |
Benutzerkennung für Postgres-Server (nur Datenbank, nicht Betriebssystem) |
|
PGPATH |
Installationsverzeichnis von Postgres, z.B. /usr/local/pgsql |
|
DB_PROPERTIES |
Pfad zur db-zul.properties-Datei mit den Zugangsparametern für SOSPOS unter Postgres |
|
LOGGING_PROPERTIES |
Pfad zur Steuerungsdatei mit den Parametern für das Logging beim Entladen, voreingestellt auf ./logging.properties. Normalerweise brauchen Sie hier nichts ändern, wenn beim Entladen Probleme auftauchen, kann man den Level von SEVERE auf INFO oder FINEST ändern, dann werden die konkreten SQLs geloggt. Aber Achtung: wenn keine Fehler mehr auftreten, müssen Sie den Level wieder auf SERVERE ändern, sonst kommen Schlüsselworte in die Logdatei zul_unload.err, die dann bei der Übernahme nach SuperX fälschlicherweise zu Fehlermeldungen führen. |
Unter Postgres muss für das "Pull"-Verfahren beim Entladen die Datenbankverbindung in der Datei db-zul.properties eingetragen werden (Muster für Postgres liegt bei in db-zul_pg.properties). Dazu laden Sie einmal die Datei ZUL_ENV mit den obigen Parameter, starten den SuperX-Propadmin (siehe Administrationshandbuch Kernmodul) und richten die Verbindung zum SOSPOS-Server ein. Das Kennwort wird verschlüsselt gespeichert. Danach sind die Entladescripte für Postgres ausführbar.
Hinweis: Anders als Informix hat Postgres hat eine eigene, vom Basissystem unabhängige Benutzerverwaltung. Daher brauchen Sie den User, den Sie zum Entladen aus Postgres nutzen, nicht auf dem SuperX- oder SOSPOS-Rechner auf Betriebssystem-Ebene einrichten. Sie können also z.B. auf dem SuperX-Rechner zum Entladen aus SOSPOS die Kennung sospos des Postgres- Rechners verwenden. Oder Sie richten in der SOSPOS -Datenbank den Benutzer SuperX ein und geben ihm Leserecht auf die Tabellen sowie das Recht, Tabellen und Stored Procedures anzulegen.
|
|
Für alle Platformen gelten folgende Variablen: |
|
ERRORMAIL |
An wen solle eine Logmail verschickt werden, wenn das Entladen nicht geklappt hat? (nur Unix). |
|
LOGMAIL |
An wen soll immer eine Logmail verschickt werden |
|
MAILPROG |
Pfad zum ausführbaren Mailprogramm unter Unix, Vorbelegung ist "mail", manche Unixe haben aber auch "mutt" oder "mailx" .
|
|
|
Wenn die Rohdaten beim Push-Verfahren nach dem Entladen vom ZUL-Rechner auf den SuperX-Rechner kopiert werden sollen, dann werden für das Script zul_copy.x folgende Umgebungsvariablen benötigt: |
|
COPY_METHOD |
Programm, das die Dateien kopiert; rsync und scp sind wählbar. |
|
REMOTE_DIR |
Verzeichnis, in das die Rohdaten auf dem SuperX-Rechner kopiert werden sollen, in der Regel ist dies "/home/superx/db/module/zul/rohdaten" |
|
REMOTE_USER |
Der Unix-Username auf dem SuperX-Rechner, in der Regel "superx". |
|
REMOTE_HOST |
Der Rechnername bzw. die IP-Nr. des SuperX-Rechners. |
Dann starten Sie das Script zul_unload.x. Wenn es gelaufen ist, müssten die Dateien im unl-Verzeichnis stehen. Prüfen Sie dann bitte, ob dort Dateien mit 0 bytes stehen. Die Logdatei heisst zul_unload.err.
Für das Entladen unter Windows gibt es Muster-Dateien im jew. Rohdaten-Verzeichnis, z.B. $SOS_PFAD/rohdaten/sos_unload.bat . Die Einrichtung geschieht dann in Java . Ans Ende der Datei können Sie noch schreiben:
date /T >superx.datum
Dann wird auch die Datumsdatei geschrieben.
Wenn Sie das Verzeichnis nicht gemounted haben, müssen das Verzeichnis unl, die zul_unload.err und die superx.datum dann in das Verzeichnis $ZUL_LOAD_PFAD auf dem SuperX-Rechner kopiert werden, ein Script dafür liegt ebenfalls bei (zul_copy.x). Das Entladedatum wird danach in der Textdatei $ZUL_LOAD_PFAD/superx.datum gespeichert; wenn das Script einen Fehler findet, dann wird das vorherige Datum (in der Datei superx.datum.alt) gesetzt.
In den jeweiligen Modulen wird im Verzeichnis rohdaten eine Beispieldatei mit dem Namen <<MODULNAME>>_ENV.sam ausgeliefert, die Sie umbenennen können nach <<MODULNAME>>_ENV. Darin werden am Ende der Datei die Parameter zum Kopieren festgelegt, also die Userkennung REMOTE_USER , der Hostname REMOTE_HOST , und die Methode des Kopierens ( COPY_METHOD ) sowie die jeweiligen Zielpfade. Diese Umgebungsvariablen werden von dem jeweiligen Script <<modulname>>_copy.x benutzt.
Damit die Passworteingabe unter Unix entfällt, muss man wie folgt vorgehen:
Loggen Sie sich zunächst testweise einmal ein. Wenn Sie z.B. vom COB-Server auf den SuperX-Server kopieren wollen, loggen Sie sich als user
cob
auf
cobhost
ein mit
ssh superx@superxhost
Beim ersten Mal müssen Sie die Sicherheitsabfrage mit "yes" bestätigen.
Erzeugen Sie auf dem Quellrechner einen öffentlichen Schlüssel mittels ssh-keygen -t rsa , wobei man eine leere Passphrase vergibt (Achtung: mögliche Sicherheitslücke!). Der öffentliche Teil dieses Schlüssels (~/.ssh/id_rsa.pub ) muss auf dem Zielrechner in die Datei ~/.ssh/authorized_keys eingefügt werden, ggf. muss die Datei neu erzeugt werden.
Wenn z.B. auf dem COB-Server unter der Kennung cob ein Key wie folgt erzeugt wurde:
|
Beispieleintrag eines Public Keys |
ssh-rsa AAAAB3Nza…[hier viele kryptische Zeichen] …pg6VkCc= cob@cobhost
|
Dann wird genau diese Zeile in der Datei /home/superx/.ssh/authorized_keys angefügt (die Datei kann mehrere PublicKeys enthalten, ein Eintrag pro Absatz).
Achten Sie auch auf Dateirechte: Die Verzeichnisse und Dateien sollten keine Schreibrechte für Gruppen haben. Im Zweifelsfall z.B. für den user superx:
chmod 700 /home/superx/.ssh
chmod 700 /home/superx/.ssh
chmod 600 /home/superx/.ssh/authorized_keys
Danach sollte z.B. der Login vom cobhost als user cob mit ssh superx@superxhost ohne Passworteingabe klappen. Wenn nicht, schalten Sie das Logging mit ssh -v superx@superxhost ein. Eine Möglichkeit ist, dass die PublicKey-Authentifizierung in der Konfigurationsdatei des SSHD (normal /etc/ssh/ssh_config ) abgeschaltet ist. Weitere Diagnosen liefert die Datei /var/log/messages .
Sie können außerdem noch einschränken, von welchem Host die obige Authentifizierung ermöglicht wird. Dazu setzen Sie den Parameter "from=*.uni-xy.de" davor, z.B.
|
Einschränkung "from" |
from="*. uni-xy.de " ssh-rsa AAAAB3Nza…[hier viele kryptische Zeichen]…pg6VkCc= cob@cobhost |
Wenn Sie die Kopiermethode scp benutzen, und die obige "authorized_keys"-Metohde mit PublicKey nicht nutzen wollen, können Sie auch mit Private Keys arbeiten (siehe SSH-Doku). Dazu können sie in der *_ENV-Datei in dem Parameter SCP_OPTS den Verweis auf den private Key setzen.
|
SCP_OPTS in *_ENV: |
SCP_OPTS="-p -B -i /home/cob/.ssh/superx_key" export SCP_OPTS |
Wenn Sie die ssh-Shell putty aus dem Installationspaket nutzen, haben Sie im Installationsordner auch die Anwendung "puttyGen.exe". Wenn Sie putty als reine Executable nutzen, laden Sie die Anwendung separat herunter. PuttyGen
• Folgen Sie der Anleitung auf der Seite http://winscp.net/eng/docs/ui_puttygen , um den SSH2-DSA oder RSA Schlüssel zu erzeugen. Für den Schlüssel bitte kein Passwort vergeben.
• Den privaten Schlüssel geben Sie in Putty bzw. Winscp im Menü "Session" im Feld "Private Key File" an.
• Der Button "Save public key" ist nicht für OPENSSH unter Linux als Zielserver geeignet. Im folgenden Screenshot sehen Sie den markierten Bereich, den Sie kopieren müssen:
• Kopieren Sie Ihren Public Key, den Sie oben mit PuttyGen erzeugt haben, zur Datei "authorized_keys" und kopieren Sie diese in das Verzeichnis ~/ .ssh/
• Bei erneutem Login mit Putty oder Winscp sollte die Passwortabfrage entfallen.
Beim Push-Verfahren wird, wenn mit scp oder rsync kopiert wird, eine Login-Shell vorausgesetzt. Wenn dies aus Sicherheitsgründen nicht gewünscht ist bzw. wg. Einsatz von Windows nicht möglich ist, können Sie auch sftp nutzen, dies wird in modernen ssh-Servern mitgeliefert und bietet ebenfalls verschlüsselten Datentransfer. Zur Einrichtung des Servers:
Der SSH-Dienst wird wie folgt konfiguriert (am Beispiel Ubuntu Linux 14.04 LTS):
In der /etc/ssh/sshd_config folgende Zeilen hinzufügen:
Subsystem sftp internal-sftp
UsePAM yes
X11Forwarding yes
Match Group sftponly
AllowAgentForwarding no
AllowTcpForwarding no
AuthorizedKeysFile /home/%u/.ssh/authorized_keys
ChrootDirectory /home/%u
ForceCommand internal-sftp -l INFO -u 0027
X11Forwarding no
Dann legen Sie die Gruppe "sftponly" an und dann den Unix-User an, und geben ihm die Gruppe "sftponly":
useradd -m $KENNUNG
usermod -aG sftponly $KENNUNG
usermod -s /sbin/nologin $KENNUNG
usermod -d "/" $KENNUNG
Dann vergeben Sie mit
passwd $KENNUNG
ein Passwort, und legen die Verzeichnisse an:
Ubuntu:
mkdir /home/$KENNUNG
mkdir /home/$KENNUNG/.ssh
chown -R $KENNUNG:<<Gruppe>> /home/$KENNUNG/*
chown -R $KENNUNG:<<Gruppe>> /home/$KENNUNG/.ssh
OpenSuse (siehe https://en.opensuse.org/SDB:SFTP_server_with_Chroot ) :
mkdir /home/$KENNUNG
chown root:sftponly /home/$KENNUNG
chmod 750 /home/$KENNUNG
mkdir /home/$KENNUNG/.ssh
chown -R $KENNUNG:<<Gruppe>> /home/$KENNUNG/.ssh
Der User kann sich dann nicht mehr mit ssh einloggen, nur noch mit sftp, und landen beim Login in /home/$KENNUNG, in einem "chroot-Käfig". Zum Testen geben Sie ein:
sftp $KENNUNG@<<Host>>
Wenn beim SFTP Login die Meldung kommt:
client_loop: send disconnect: Broken pipe
müssen Sie darauf achten dass das Home-Verzeichnis des Users nicht dem User gehört, sondern root.
Wenn der Login klappt, können Sie nach dem oben beschriebenen Verfahren die Passworteingabe durch PublicKey-Authentifizierung ersetzen.
Für das Kopieren der Rohdaten selbst werden in Zukunft im Kopierscript " <<modulname>>_copy.x " auch sftp-Kommandos aufgenommen. Sie müssen nur in der ENV-Datei die Variable
COPY_METHOD=sftp
setzen. Alle anderen Variablen und Mechanismen wie z.B. Entfernen der Passworteingabe entsprechen denen von SCP / SSH (s.o.).
Spezielle Optionen fürs sftp können Sie in der Umgebungsvariable SFTP_OPTS setzen. Es kann z.B. sein, dass das Kopieren großer Dateien in einen Timeout läuft. Bei CSV bietet es sich an, die Dateien zu komprimieren, sie können also setzen:
SFTP_OPTS="-oCompression=yes"
export SFTP_OPTS
Danach wiederholen Sie das kenn_copy.x
Dies ist nur ein Beispiel. Weitere Optionen für SFTP entnehmen Sie der manpage.
Das Kopieren mit sftp klappt übrigens auch unter Windows z.B. mit dem Programm winscp . Dies wird im folgenden erläutert.
Unter Windows ist das Standardprogramm für SFTP die Anwendung winscp . Sie können die Passworteingabe analog zu Putty entfernen . Danach können Sie eine Session erzeugen:

Im Feld "Private key file" geben Sie den private key ein, den Sie oben erzeugt haben. Klicken Sie dann auf "Save session", und geben Sie einen kurzen, sprechenden Namen ohne Leerzeichen oder Umlaute, z.B. "superx@vmmulti1"
Sie müssen nun die Verzeichnisse lokal und remote in der Winscp-Session speichern, im Menüpunkt "Directories":
Vergessen Sie auch hiernach nicht, die Session zu speichern.
Danach testen Sie einmal den Zugang. Wenn das klappt können Sie Winscp auch für die Kommandozeile automatisieren. Sie erzeugen zunächst eine Textdatei mit den Kommandos für Winscp, dies enthält auch die zu übertragenden Dateien. Der Aufbau der Datei ist wie folgt:
open <<Sessionname>>
# Upload the file to current working directory
put <<Datei>>
# Disconnect
close
# Exit WinSCP
exit
Die zu übertragenden Dateien sind in der Musterdatei des jew. Moduls in rohdaten/<<Modulname>> _sftp.txt aufgelistet, Sie müssen lediglich
• den "/" durch einen "\" ersetzen
• das Entladeprotokoll <<Modulname>>_unload.err und die Datumsdatei superx.datum hinzufügen
Hier ein Beispielscript fürs das Studierenden-Modul:
open superx@vmmulti1
# Change remote directory
# Upload the file to current working directory
put sos_unload.err
put superx.datum
put unl\konstanten.unl
put unl\sos_studenten.unl
put unl\sos_hzb.unl
put unl\sos_faecher.unl
put unl\sos_pord_to_stg.unl
put unl\sos_pruefungenext.unl
put unl\sos_pruefungen.unl
put unl\sos_lab_astat_attributes.unl
put unl\sos_stud_loe.unl
put unl\sos_faecher_ext.unl
put unl\sos_faecher_kontrolle.unl
put unl\sos_pruefungen_kontrolle.unl
put unl\sos_anschri.unl
put unl\sos_parstg.unl
put unl\sos_hsnr.unl
put unl\semester.unl
put unl\cif.unl
put unl\cifx.unl
put unl\k_pvers.unl
put unl\k_stg.unl
put unl\k_stgext.unl
put unl\k_abstgv.unl
put unl\sos_pord.unl
put unl\sos_dipl.unl
put unl\sos_minder.unl
put unl\sos_stud_d.unl
put unl\sos_pords.unl
put unl\sos_porg.unl
put unl\sos_labzuord.unl
put unl\sos_pnrzuord.unl
put unl\sos_gewichtungsvariante.unl
put unl\sos_gewichtungregel_filter.unl
put unl\sos_gewichtungregel.unl
put unl\personattribute.unl
put unl\personattributetype.unl
put unl\personattribute_value_list.unl
put unl\stu_update_prot.unl
put unl\exa_update_prot.unl
put unl\sos_accredited_ects.unl
put unl\sos_pord_orgeinheit.unl
# Disconnect
close
# Exit WinSCP
exit
Die Datei hat z.B. den Namen winscp_example_script.txt . Dann können Sie das Script aufrufen mit dem DOS-Kommando:
winscp /script= <<Pfad zu>> \winscp_example_script.txt
Hier ein Screenshot wie das dann aussieht:
Das DOS-Kommando läßt sich dann über die Windows-Taskverwaltung automatisieren.
Zum Entladen aus dem operativen Vorsystem wird unter Informix dbaccess genutzt. Unter Postgres wird generell der SuperX-JAVA-Client zum Entladen genutzt, denn SuperX benötigt ein spezielles, an Informix angepasstes CSV-Format, das sich mit Bordmitteln von Postgres (copy-Befehl) nicht erzeugen lässt. Es kann aber auch sinnvoll sein, aus der Informix-Datenbank mit SuperX-JAVA-Client zu entladen, z.B. wenn Sie kein UNIX-dbaccess auf dem Vorsystem installiert haben.
Wenn Sie das jew. operative Vorsystem im PUSH-Verfahren entladen wollen, d.h. die Rohdaten werden auf dem Vorsystem entladen und auf den SuperX-Rechner kopiert, dann müssen Sie spezielle Vorkehrungen treffen. SuperX nutzt generell zum Entladen eigene Java-Klassen. Beim Entladen im PULL-Verfahren sind diese Klassen vorhanden, denn die Entladeroutine läuft auf dem SuperX Rechner. Wenn Sie aber PUSH nutzen wollen, werden die SuperX-Java-Klassen auf dem Liefersystem benötigt, und die Entladeroutine muss konfiguriert sein. Im Folgenden nutzen wir das Beispiel "Entladen im Push-Verfahren aus SVA-GX unter Postgres". Gehen Sie dazu wie folgt vor:
• Kopieren Sie die Dateien
• superx*jar
• postgresql-*.jar
• jfor-0.7.2rc1.jar
• vom SuperX-Rechner im Verzeichnis $SUPERX_DIR/tomcat/webapps/superx/WEB-INF/lib auf den Quellrechner in ein Unterverzeichnis lib unter rohdaten (z.B. /home/sva/superx/rohdaten/lib ). In rohdaten liegt die bisherige Entladeroutine (z.B. sva_unload.x ).
• Fügen Sie dann folgenden Passus aus der Datei $SUPERX_DIR/db/bin/SQL_ENV in die Umgebungs-Datei der Entladeroutine, z.B. SVA_ENV :
#Pfad zu den SuperX-Java-Libraries
#Der JDBC_CLASSPATH enthält alles, was der jdbc-Client in superx für den Datenbankzugriff braucht.
#jfor-0.7.2rc1.jar, postgresql-9.2-1002.jdbc4.jar, superx4.6.jar
LIB_PATH=$SVA_LOAD_PFAD/lib
JDBC_CLASSPATH="." ; for i in `ls $LIB_PATH/*.jar` ; do JDBC_CLASSPATH=$JDBC_CLASSPATH:$i ; done
export JDBC_CLASSPATH
XML_CLASSPATH=""
export XML_CLASSPATH
Wenn dann noch die Variablen DB_PROPERTIES und LOGGER_PROPERTIES korrekt gesetzt sind, kann die Entladeroutine bei SX_CLIENT=jdbc (Wenn Sie unter Windows entladen, oder Informix ohne dbaccess entladen wollen) oder SX_CLIENT=psql (wenn Sie Postgres unter UNIX nutzen) mit Java entladen.
Wenn das Entladen aus dem Vorsystem geklappt hat (sofern es ein Vorsystem gibt), können Sie die Daten laden. Zum Update bzw. zum Laden der Rohdaten gehen in das Verzeichnis $SUPERX_DIR/db/module/<<Modulname>> und führen das Script aus:
<<Modulname>>_update.x
Die Logdatei lautet L_<<Modulname>>_UPDATE.log , im Mandantenfähigen Betrieb " L_<<Modulname>>_UPDATE<<MANDANTID>>.log ".
Für die Aufnahme der Laderoutine in die crontab gibt es im gleichen Verzeichnis Musterscripte nach dem Namensmuster:
<<Modulname>>_update_cron.x
Je nach Push/Pull-Szenario können Sie auch den Unload darin starten oder nicht.
Der Modulupdate in mandantenfähigen Installtion findet in einer SuperX-Installation statt, allerdings werden die einzelnen Scripte mit unterschiedlichen Umgebungsvariablen, wie sie in SQL_ENV.<<MANDANTID>> definiert ist, z.B. SQL_ENV.FHRO .
In der SQL_ENV.<<MANDANTID>> werden unterschiedliche Pfade für den jeweiligen *_LOAD_PFAD gesetzt, wobei in der Regel die Mandandid ein Unterverzeichnis vom "normalen" LOAD_PFAD ist. So ist z.B. beim COB-Modul folgender Pfad anzusetzen:
Normale SuperX-Installation:
COB_LOAD_PFAD=$SUPERX_DIR/db/module/cob/rohdaten
Mandantenfähige SuperX-Installation:
COB_LOAD_PFAD=$SUPERX_DIR/db/module/cob/rohdaten/FHRO
Unterhalb von FHRO befindet sich noch einmal die Entladeroutine sowie das Unterverzeichnis unl mit den Rohdaten. Dieses Verzeichnis FHRO kann der Einfahheit halber auch ein symbolischer Link auf den gemounteten COB-Rechner sein.
Durch Setzen der Mandantennummer in der Umgebungsvariable MANDANTID in der jeweiligen SQL_ENV des Mandanten werden die ETL-Scripte anders ausgeführt: Die Logdateien werden jeweils mit der Mandantennummer versehen (z.B. L_cob_updateFHRO.log), damit die Übersicht nicht verloren geht und der gleichzeitige Update mehrerer Mandanten in eine rsuperX-Installation möglich ist.
Außerdem können weitreichende Steuerungsmechanismen im Modulupdate eingesetzt werden: Nach jedem ETL-Schritt können optional mandantenspezifische Scripte aufgerufen werden. Diese müssen folgende Namenskonvention einhalten:
<<Scriptname>>_<<MANDANTID>>.sql
Also für eine hochschulspezifische Transformation im COB-Modul des Mandanten FHRO wird eine Datei namens
cob_trans_FHRO.sql
mit entsprechenden SQL-Anweisungen angelegt.
Generell gilt das Prinzp, daß Daten vom Vorsystem in CSV entladen werden, und dann in sog. Ladetabellen hochgeladen werden. Da CSV je nach DBMS unterschiedlich implementiert wird, hier eine kurze Beschreibung des Formats, das im wesentlichen den Vorgaben von Informix LOAD entspricht:
• Zeichenformat: UNIX LATIN1 oder UTF-8
• Feldtrenner: ^
• Satztrenner: Feldtrenner + UNIX NEWLINE
• Zeilenschaltung: Umbrüche innerhalb von Textfeldern sind als \ + NEWLINE codiert
• Feldtrenner, die im Textfeld vorkommen, werden mit "\" maskiert. Ebenso das Zeichen "\" selbst
• Die Datumsformate sind bei Datumsfeldern immer im deutschen Format (DD.MM.YYYY) vorgesehen
• Boolean-Werte werden durch "true" oder "false" codiert
• Der Dezimaltrenner ist ".", kein 1000-er Punkt bei Zahlen.
• Leerstrings und Leerzeichen werden als " " (Leerzeichen) exportiert.
Zum Upgrade bzw. zum Zurücksetzen des Moduls auf den Auslieferungszustand entpacken Sie das Paket in $SUPERX_DIR und gehen in das Verzeichnis $SUPERX_DIR/db/module/<<Modulname>>/upgrade und führen das Script aus:
<<Modulname>>_upgrade.x
Ausnahme: beim Kernmodul gibt es i.d.R. ein spezielles Upgrade Script.
Die Logdatei lautet upgrade.log , im Mandantenfähigen Betrieb " upgrade<<MANDANTID>>.log ".
Wenn Sie einen separaten Tomcat-Rechner betreiben, müssen Sie das Paket dort ebenfalls entpacken, und vom Datenbankserver die Datei $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/dbforms-config.xml an die gleiche Stelle auf den Tomcat Rechner kopieren. Ein nochmaliges Ausführen des Upgrade Scriptes ist nicht nötig, weil dies nur die Datenbank betrifft.
Nach der Installation bzw. beim Upgrade können Sie hochschuleigene SQL Scripte ausführen lassen. Erzeugen Sie dazu eine Datei $SUPERX_DIR/db/module/<<Modulname>>/conf/customize.sql (bei Mandantenbetrieb $SUPERX_DIR/db/module/<<Modulname>>/conf/customize$<<MANDANTID>>.sql ) und füllen Sie diese mit einem beliebigen Inhalt. Das Script wird beim Upgrade des Moduls automatisch am Ende ausgeführt. Ein Anwendungsbeispiel finden Sie im Kapitel Default-Vorbelegungen für Felder ändern.
Wenn Sie ein Modul nicht mehr benötigen, starten Sie das Script
$SUPERX_DIR/db/module/<<Modulname>>/<<Modulname>>_modul_entfernen.x.
Dieses Script löscht alle Tabellen, Prozeduren und Abfragen aus der Datenbank, und löscht auch die Einträge im Themenbaum. Danach können Sie den Pfad
$SUPERX_DIR/db/module/<<Modulname>>
löschen.
Wenn Sie nur die Inhalte der Daten- und Hilfstabellen des Moduls löschen wollen (z.B. aus Datenschutzgründen), ohne das ganze Modul zu deinstallieren, können Sie dies mit folgendem Befehl tun:
DOSQL $SUPERX_DIR/db/module/<<Modulname>>/<<Modulname>>_purge_pg.sql
(für Postgres)
bzw.
DOSQL $SUPERX_DIR/db/module//<<Modulname>>/<<Modulname>>_purge_ids.sql
(für Informix)
SuperX besteht aus verschiedenen Komponenten, die jeweils eigene Überwachungsmerkmale und Performance-Mechanismen besitzen.
Die Webanwendung baiert auf Tomcat, und die Logdateien des Tomcat liegen standardmäßig im Verzeichnis $SUPERX_DIR/webserver/tomcat/logs . Die Logdateien im Einzelnen:
• Logging von Tomcat: catalina.out bzw. localhost.xxx.out
• Logging der SuperX-Webanwendung jeweils in superx_default.log (statt "default" ggf. die Mandantenid) für allgemeines SQL-Logging, und superx_default_xml.log für das Logging der XML-Ausgabe des XML-Frontends.
• dbforms.log für Logging der DBForms-Komponente
Alle Logging-Ausgaben lassen sich flexibel an verschiedenen Stellen steuern:
• Das Tomcat-Logging lässt sich in der Datei $SUPERX_DIR/webserver/tomcat/common/classes/log4j.properties steuern
• Das Ausmaß des Loggings der SuperX-Webanwendung: Im propadmin wird der Logging-Level für die SQL-Ausgabe sowie für die XML-Ausgabe festgelegt.
• Das Logging für DBFORMS und Mondrian / Saiku wird in der Datei $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/log4j.properties festgelegt.
• Das Logging der java-bezogenen SuperX-DB-Anwendung wird in der Datei $SUPERX_DIR/db/conf/logging.properties gesteuert.
Die SQL-Scripte der SuperX-Abfragen können in der Java-Konsole des Applets sowie in der o.g. superx_default.log eingesehen werden. Bitte beachten Sie dabei, dass bei SQL-Fehlern nur im Entwicklungsmodus die genaue Stelle des Auftretens ermittelt werden kann.
Das Logging von Mondrian kann eigenst festgelegt werden. Dies wird im Kapitel Logging in Mondrian / Saiku erläutert.
Mit Java 1.6 und Tomcat 5.5 gibt es eine komfortable Möglichkeit, den Server zu überwachen. Vor dem Start von Tomcat setzen Sie die Option CATALINA_OPTS wie folgt:
|
Achtung: Alle Zeilen in eine Zeile tippen, die Umbrüche kommen nur durch das Layout |
CATALINA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8020 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -DSuperX-DB-PROPERTIES-SET=true " export CATLINA_OPTS |
Sie starten den Tomcat dann mit einer Überwachungsschnittstelle auf Port 8020, die Sie dann von einem (entfernten) Client auswerten können:
|
Starten Sie das Programm jconsole |
jconsole |
|
Bei einem entfernten Rechner geben Sie den Rechnernamen und Port an |
|
Diese Anwendung liefert detailliert Aufschluss über den Server:
|
Hier sehen Sie die |
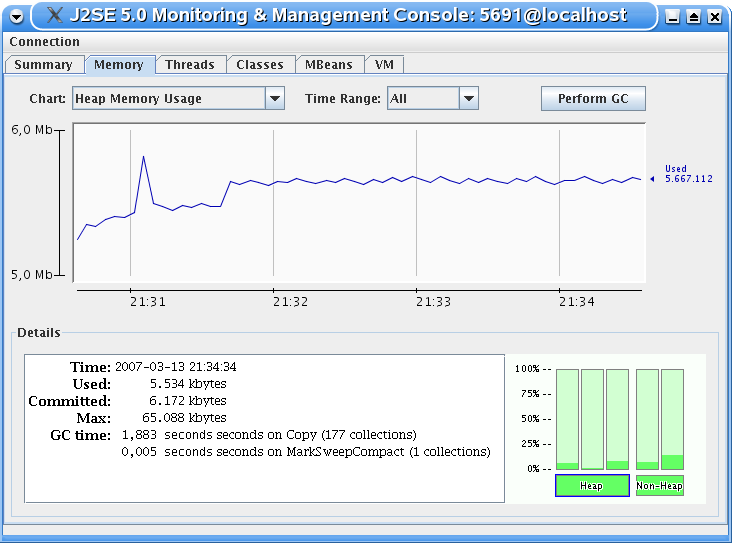
|
Wir empfehlen, im Produktivbetrieb dies abzuschalten (Sicherheitslücke und Performance-Kosten).
Eine detailliertere Anleitung finden Sie hier:
http://blog.linkwerk.com/entry/cl/2007-05-08T12.00.00
Generell empfehlen wir, den Tomcat im Produktivbetrieb jede Nacht einmal neu hochzufahren, im SuperX-Kernmodul wird dazu ein Beispielscript ausgeliefert ( db/bin/restart_tomcat.x ). Ein weiteres nützliches Script prüft z.B. alle 5 Minuten, ob der Server noch läuft; wenn nicht dann wird er automatisch hochgefahren ( db/bin/check_restart_tomcat.x ).
Datenblätter, die auf zentrale Funktionen des Kernmoduls zurückgreifen, lassen sich mit einer maximalen Zeilenanzahl konfigurieren. So kann verhindert werden, daß Anwender/innen ein zu umfangreiches Datenblatt abrufen, das den Datenbankserver über Gebühr belastet bzw., wie uns bei Informix berichtet wurde, sogar zum Absturz bringen kann.
Setzen Sie dazu die Konstante "Datenblatt max.Zeilenzahl" auf den Wert, der zu Ihrem Server paßt. Defaultwert ist 20.000 Zeilen.
Menüpunkt "Administration → Tabelle suchen → Stichwort "Konstanten" → Listenformular aufrufen und zur Konstante "Datenblatt max.Zeilenzahl" navigieren, und diese dann auf den entsprechenden Wert setzen.
Im Ergebnis erhalten Benutzer, die ein Datenblatt mit zu vielen Zeilen abrufen, folgende Meldung (z.B. bei max. 40 Zeilen):
Wenn das Datenblatt gar nicht angezeigt wird und direkt ein JasperReport aufgerufen wird, kommt folgende Meldung:

Da die Laufzeiten der Updates und Berichte immer wieder ein Thema an den Hochschulen ist, möchten wir versuchen Vergleichswerte zu schaffen und auch den Hochschulen die Möglichkeit bieten, zu prüfen, wie die Leistung der SuperX Datenbank zu bewerten ist. Mit dem Benchmark Script kann zu jeder Zeiten mit den gleichen Werten die Datenbank geprüft werden. Dadurch sind die Laufzeiten gut für Vergleiche geschaffen. Der Update der Module kann durch die angestiegene Anzahl der Datensätze/Studierenden im laufe der Zeit ansteigen. Ziel dieses Scripts ist somit einmal der Vergleich mit anderen Hochschulen und auch testen zu können, ob im laufe der Zeit der Server mit anderen Aufgaben zu sehr ausgelastet wird.
Das Script erhalten Sie im SuperX Download-Bereich:
http://download.superx-projekt.de/
Geben Sie als Stichwort Benchmark ein.
Wenn Sie das Script heruntergeladen haben, speichern Sie es am besten auf dem Server, von dem Sie die Updates starten. Dort laden Sie dann Ihre SQL_ENV und starten das entpackte Script mit DOSQL. Wenn Sie möchten können Sie die Ausgabe noch in eine Logdatei mit Datum umleiten um das Ergebnis zu sichern und in Zukunft weitere Logdateien für Vergleiche erstellen.
Hier noch ein paar Vergleichswerte.
|
Hochschule |
Datenbank |
Laufzeit |
|
HS mit 35T Studierende |
Informix Testsystem |
20 Minuten |
|
HS mit 35T Studierende |
Informix Produktivsystem |
24 Minuten |
|
HS mit 3T Studierende |
Postgres Testsystem |
15 Stunden 32 Minuten |
|
HS mit 8T Studierende |
Informix Testsystem |
4 Stunden 00 Minuten |
|
Entwickler Laptop |
Informix |
1 Stunde 04 Minuten |
|
Entwickler Laptop |
Postgres |
16 Minuten |
Die Download-Dateien werden in dem geschützten Verzeichnis der Webapplikation gespeichert. Um die Dateien gezielt in einem Verzeichnis zu speichern, muss man ggf. das Attribut "directory" des Feldes "datei" in der Tabelle sx_downloads in der Datei dbforms-config.xml setzen, standardmäßig ist dies (relativ zu dem Startpfad von Tomcat) ".. /webapps/superx/WEB-INF/downloads" .
Mit dem Attribut "encoding" (default "false") wird festgelegt, ob der Dateiname vom Original übernommen werden soll ("false") oder ob eine eindeutige Zufalls-Zeichenkette ("true") erzeugt werden soll. Die Endung der Datei wird bei letzterem beibehalten.
Gleichzeitig werden der Dateiname und diverse andere Metadaten in der Tabelle sx_downloads gespeichert. Wenn ein Anwender einen Download abruft, dann wird die Datei im SuperX-Servlet geladen und über http(s) ausgeliefert.
Die Auslieferung von Dateien wird defaultmäßig protokolliert und kann über die Maske "Downloadstatistik" abgerufen werden. Sie können diese Funktionalität (z.B. aus Datenschutzgründen) sperren, indem Sie die Konstante " DOWNLOAD_PROTOKOLL " statt auf "1" auf "0" setzen - damit werden keine Download-Aktivitäten in SuperX protokolliert (was aber nicht bedeutet, dass dies auch im Webserver-Log nicht mehr passiert, die dortige Protokollierung sowie die Tomcat-eigene Protokollierung ist davon unabhängig).
Außerdem können Sie die maximale Größe von Dateien festlegen. Dafür gibt es in der web.xml einen Parameter "maxUploadSize", der die maximal Größe (in Bytes) beschreibt:
<!--=========== DbForms Controller Servlet ==============-->
<servlet>
<servlet-name>control</servlet-name>
<servlet-class>org.dbforms.servlets.Controller</servlet-class>
<init-param>
<param-name>maxUploadSize</param-name>
<param-value> 800000 </param-value>
</init-param>
</servlet>
Es gibt eine Tabelle sx_downloads mit folgenden Feldern:
|
Feldname |
Feldtyp |
Größe |
Default |
Not Null |
Beschreibung |
|
tid |
SERIAL |
4 |
|
true |
Primärschlüssel |
|
name |
CHAR |
255 |
|
false |
Titel |
|
ch110_institut |
CHAR |
10 |
|
false |
Kostenstelle/Institut |
|
bezugsdatum |
DATE |
4 |
|
false |
(für Ermittlung Bezugsjahr,- Monat oder Sem.) |
|
importdatum |
DATE |
2 |
|
false |
Datum des Imports in die SuperX-Datenbank |
|
kommentar |
TEXT |
32000 |
|
false |
Kommentar für Website (Datenlegende o.ä.). |
|
kommentar_www |
CHAR |
255 |
|
false |
Verweis auf andere Website für längere und gelayoutete Kommentare oder Dokumentationen. |
|
contenttype |
CHAR |
50 |
|
false |
Mime-Type der Datei (pdf, html etc). |
|
datei |
CHAR |
255 |
|
true |
Pfad zum geschützten Verzeichnis (relativ zu $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/downloads ) |
|
gueltig_seit |
DATE |
2 |
|
false |
Soll Download angezeigt werden von … |
|
gueltig_bis |
DATE |
2 |
|
false |
Soll Download angezeigt werden bis… |
Desweiteren gibt es eine Tabelle sx_keywords zur Erhebung der Stichworte:
|
Feldname |
Feldtyp |
Größe |
Default |
Not Null |
Beschreibung |
|
tid |
SERIAL |
4 |
|
false |
Tupelidentifier |
|
name |
CHAR |
255 |
|
false |
Stichwort |
|
parent |
INTEGER |
4 |
|
false |
Übergeordnetes Stichwort Wird derzeit noch nicht ausgewertet. |
Die Zuordnung zwischen Download und Stichwort findet in der Tabelle download_keyw_bez statt:
|
Feldname |
Feldtyp |
Größe |
Default |
Not Null |
Beschreibung |
|
keyword_id |
INTEGER |
4 |
|
false |
|
|
download_id |
INTEGER |
4 |
|
false |
|
Die Berechtigungen für die Downloads werden über die SuperX-Gruppen- bzw. Userrechte verwaltet. Dazu werden eigene Tabellen user_download_bez und group_download_bez erzeugt, für die auch Pflegeformulare existieren. Die Institutions-Berechtigung wird auch Bordmitteln von SuperX realisiert, d.h. die Anwender erhalten über ihre Zuordnung zur jeweiligen Kostenstelle in der Tabelle user_institution das Recht für die Kostenstelle und alle jeweils untergeordneten Kostenstellen.
Einzelne vorgefertigte Masken sind bereits eingerichtet und werden im Folgenden beschrieben.
Im XML-Frontend finden Sie die Download-Masken im Themenbaum-Ast "Administration".
Mit der Maske "Download suchen" können sie einzelne Downloads einrichten, bearbeiten oder löschen.
|
In der Suchmaske können Sie verschiedene Parameter einschränken. Wenn ein Stichwort oder eine Kostenstelle ausgewählt wird, dann werden alle Downloads mit diesem oder untergeordnetem Stichwort/ Kostenstelle gefunden. |
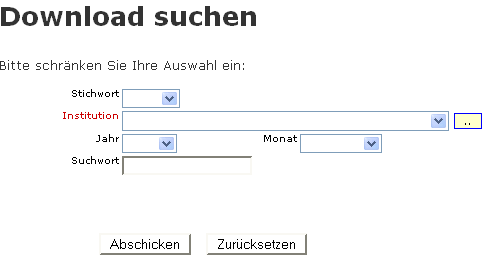
|
Das Freitext-Feld Suchwort bezieht sich auf den Namen des Downloads.
|
Die Ergebnistabelle zeigt die Downloads. Wenn Sie als Administrator gekennzeichnet sind (Feld administration in userinfo steht auf "1"), dann können Sie die Downloads nicht nur laden, sondern auch bearbeiten sowie zu Usern/Gruppen bzw. Themen zuordnen. |
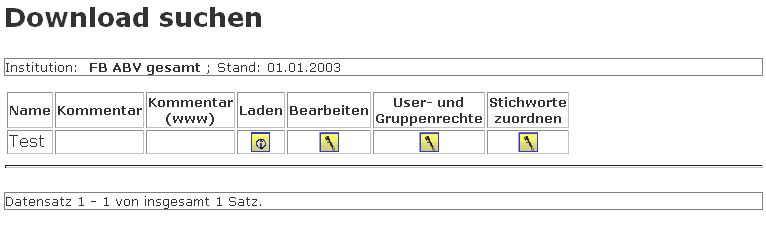
|
In der Bearbeitungsmaske erscheinen die oben beschriebenen Felder nebst Erläuterungen.
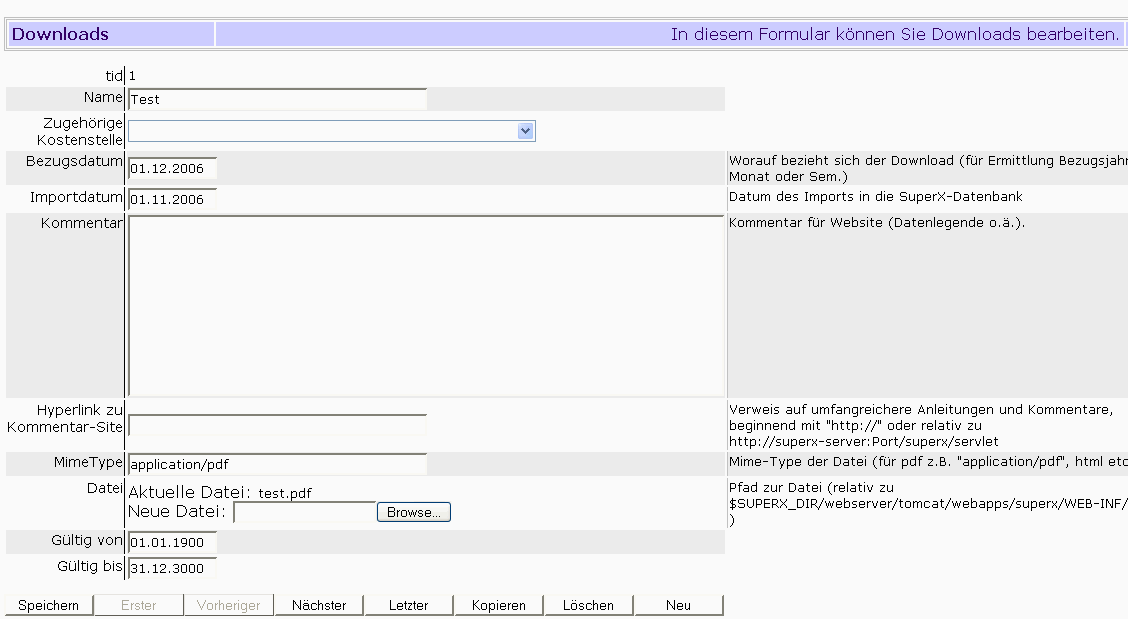
Sie können, müssen aber nicht, einem Download einer einzelnen Kostenstelle zuordnen. Hierarchische Anordnungen werden dabei suchbar, d.h. wenn ein Anwender in der Insitutions-Sicht des Organigramms eine Kostenstelle auswählt, dann werden alle Downloads mit untergeordneten Kostenstellen ebenfalls gefunden.
Sie können Dateien Hochladen, inden Sie in der Zeile Datei eine neue Daten festlegen. Ansonsten wird darüber der aktuelle Dateiname festgelegt. Wichtig ist, dass der Dateiname in dem Verzeichnis $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/downloads eindeutig ist. Außerdem funktioniert der Browser-basierte Upload nur mit kleinen Dateien, größere Dateien sollten Sie manuell in das Verzeichnis $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/downloads kopieren.
Sie können auch Datensätze kopieren, allerdings werden nur die Metadaten werden kopiert, sie müssen dann eine neue Datei hochladen.
Mit der Schaltfläche unter "User- und Gruppenrechte" sehen Sie das Bearbeitungsformular.
|
Sie können jeweils einzelne User oder Gruppen zuordnen, die Funktionalität entspricht der Berechtigung für Sichten . |

|
Mit der Schaltfläche unter "Stichworte zuordnen" sehen Sie das Bearbeitungsformular.
|
Sie können jeweils ein oder mehrere Themen zuordnen. |

|
Es gibt verschiedene Szenarien zur Migration von SuperX, hierzu werden Empfehlungen gegeben.
Unter Postgres bietet es sich an, von Postgres ISO-Codierung zu Postgres-UTF-8 Codierung zu wechseln. Für die Umsetzung der Zeichencodierung von Dateien gibt es in Postgres eingebaute Unterstützung: Wenn ein Text-Dump einer ISO-Datenbank erzeugt wird, dann steht im Kopf der Datei die Encodierung. Wenn man diese Datei mit psql in eine UTF-8-DB füttert, wird automatisch von ISO nach UTF-8 konvertiert. Für die Umcodierung der Datenbank hat sich also folgendes Vorgehen bewährt:
Exportieren Sie die ISO-Datenbank mit pg_dump im Format "plain text". Es wird eine sql-Datei erzeugt, im folgenden Beispiel für die Datenbank mit dem Namen "$DBNAME":
pg_dump -f $DBNAME.sql $DBNAME
Falls Sie direkt beim Dump eine zip-Datei erzeugen wollen, nutzen Sie folgendes Script:
pg_dump $DBNAME | gzip >$DBNAME.sql.gz 2>dump.err
Wechsel Sie dann in eine Postgres-Installation, die UTF-8 unterstützt, und erzeugen Sie die Datenbank neu:
createdb --encoding=UTF-8 $DBNAME
Dann importieren die Datenbank mit:
psql $DBNAME < $DBNAME.sql
Danach müssen Sie alle Dateien unterhalb von $SUPERX_DIR von ISO nach UTF-8 konvertieren. Bitte fertigen Sie zunächst eine Sicherung des Dateisystems unterhalb von $SUPERX_DIR an.
Zum Konvertieren sich die Shellscripte vom SuperX Kernmodul 4.0 oder höher an. In short:
cd $SUPERX_DIR
sx_list_isofiles.x . >iso.txt
sx_recode_isofiles.x iso.txt
Am Ende müssen Sie noch in der Datei $SUPERX_DIR/db/bin/ SQL_ENV die Variable LANG auf die UTF-8-Codierung setzen. Führen Sie dazu
locale -a | grep de
aus, um die verfügbaren Codierungen zu ermitteln, und setzen Sie dann den entsprechenden Wert, z.B.:
LANG=de_DE.utf8
export LANG
Außerdem ergänzen Sie im Parameter CATALINA_OPTS den Schalter -Dfile.encoding=UTF-8, z.B.
CATALINA_OPTS="-Xmx700M -XX:MaxPermSize=200m -Djava.awt.headless=true -DSuperX-DB-PROPERTIES-SET=true -Dfile.encoding=UTF-8 "
Danach laden Sie einmal die Datei SQL_ENV neu:
. $SUPERX_DIR/db/bin/SQL_ENV
Danach müssen Sie in der Datei $SUPERX_DIR/tomcat/conf/ server.xml den Parameter URIEncoding="UTF-8" ergänzen, z.B.
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8" />
Starten Sie dann noch Tomcat neu. Damit die die Migration nach UTF-8 beendet.
Eine direkte Konvertierung von Postgres nach Informix geht nicht, wg. der stored procedures. Wir raten zu folgendem Vorgehen:
• Entpacken Sie die jeweils genutzten Release-Module für Informix in $SUPERX_DIR. Die Versionsnummern sollten exakt den Postgres-Modulen entsprechen, die Sie bereits nutzen.
• Kopieren Sie die Datei $SUPERX_DIR/db/bin/SQL_ENV nach SQL_ENV.pg
• Ändern Sie die Datei $SUPERX_DIR/db/bin/SQL_ENV, indem Sie dort die Umgebungsvariablen DATABASE und SX_CLIENT nach INFORMIX / dbaccess ändern. INFORMIXSERVER etc. müssen Sie ebenfalls eintragen
•
Kopieren Sie die Datei
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/db.properties
nach
db_pg.properties, und legen Sie die Umgebungsvariable DB_PROPERTIES in der Datei $SUPERX_DIR/db/bin/SQL_ENV.pg auf diese Datei
•
Laden Sie die Informix-Umgebung mit
. $SUPERX_DIR/db/bin/SQL_ENV
• Installieren Sie das Informix-Kernmodul in der shell in
•
$SUPERX_DIR/db/install
mit
kernmodul_erzeugen.x
• Passen Sie die jetzige Datei $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/db.properties so an, daß der INFORMIXSERVER gefunden wird. Dafür haben wir ein Tool namens "propadmin.x", mit dem Sie die DB-Verbindung eintragen und testen können. Wenn Sie keine graphische Umgebung haben, müssen Sie die Informix-Parameter in der Datei manuell anpassen, Musterdateien liegen im gleichen Verzeichnis.
•
Installieren Sie die jew. Module mit dem *erzeugen.x-Script
(ohne jeweils den Update zu starten)
• Entladen Sie die Postgres-Module, indem Sie in das jew. Modulverzeichnis gehen, und
•
Laden Sie die Postgres-Umgebung mit
. $SUPERX_DIR/db/bin/SQL_ENV.pg
• Entladen sie das Modul mit <<Modulname>>_backup.x
• Es werden csv-Dateien in das Unterverzeichnis tmp geschrieben
•
-Laden Sie die Informix-Umgebung mit
. $SUPERX_DIR/db/bin/SQL_ENV
• Laden sie das Modul mit <<Modulname>>_restore.x
Voila! Sogar die Logins bleiben erhalten.
Probleme sind nur an folgenden Stellen zu erwarten:
• Die Kernmodul-Tabellen maskeninfo und felderinfo könnten beim CSV-Upload Probleme mit Umbrüchen machen. Mit dem jew. Script <<Modul>>_masken_einspielen_ids.x kann man die Masken aber manuell laden.
• Die Tabelle des SOS-Moduls lehr_stg_ab enthält Spalten mit "not null"-Constraints. Beim CSV-Upload werden Leerstrings aber NULLs, so daß die Tabelle sich nicht laden läßt. Man kann da über eine temp.Tabelle gehen
• Hochschul-spezifische Tabellen und Masken müssen manuell geladen werden. Ggf. müssen wir Anpassungen für Postgres-Syntax machen.
In HISinOne / Edustore ist folgendes fest vorgegeben:
• Das DBMS ist Postgres
• Die Zeichencodierung ist UTF-8
Vor einer Migration zu HISinOne / Edustore müssen Sie also o.g. zuerst erledigen. Eine Anleitung finden Sie oben .
• Wenn die Migration zu Postgres / UTF-8 gelungen ist, müssen Sie wie folgt vorgehen:
• Entpacken Sie das HISinOne Release auf dem Server, und richten Sie den Qisserver ein (databases.xml etc).
• Bei der Neuinstallation von HISinOne müssen Sie normalerweise eine leere Postgres-Datenbank "eduetl" anlegen, dies in Ihrem Falle nicht notwendig. Sie verlinken die oben migrierte Datenbank in der databases.xml
• Sie starten in der BI-Administration den Upgrade der jeweiligen Module, beginnend mit dem Kernmodul. Dies können Sie über den Browser realisieren, oder über Shell- bzw. ANT Scripte
Sie können nach der Migration der Datenbank die Korrektoren auf BI-Technik umstellen . Sie können alternativ auch die bisherigen SuperX Shellscripte weiterhin nutzen. Im HISinOne-Release ist die Verzeichnisstruktur allerdings eine andere als in SuperX: Es gibt nicht das Verzeichnis db/* im obersten Verzeichnis, sondern alle Dateien liegen unter ../webapps/superx. Hier eine Gegenüberstellung:
|
Pfad / Variable |
SuperX |
HISinOne-BI |
|
SUPERX_DIR |
[ganz oben] |
superx/WEB-INF/conf/edustore |
|
WEBAPP |
webserver/tomcat/webapps/superx |
s uperx |
|
Kernmodul |
$SUPERX_DIR/db/install |
superx/WEB-INF/conf/edustore/db/install |
Bitte passen Sie daher Ihre SQL_ENV entsprechend an.
Die Technik der BI-Konnektoren ist identisch mit der von SuperX, allerdings lassen sich BI Konnektoren auch in der Komponentenverwaltung von HISinOne ausführen. Wenn Sie die Komponentenverwaltung nutzen wollen müssen Sie die Umgebung der bisherigen SuperX-Shellscripte des jew. Moduls (z.B. $SOS_LOAD_PFAD/SOS_ENV und die darin referenzierte DB_PROPERTIES ) nach HISinOne (die Datei .../webapps/qissserver/WEB-INF/conf/databases_<<Spezialmodul>>.xml ). Beispiel sospos in HISinOne:
<dbconnection name="sospos" active="y" user="*,admin,system" scheme="sospos">
<jdbcDriver>org.postgresql.Driver</jdbcDriver>
<protocol>jdbc:postgresql:</protocol>
<database>sospos</database>
<host>soshost</host>
<dbserverport>5432</dbserverport>
<user>sospos</user>
<password>anfang12</password>
<testConnection>y</testConnection>
</dbconnection>
Das analoge Beispiel in $SOS_LOAD_PFAD/db-sos_pg.properties:
driverName=org.postgresql.Driver
connectionName=superx
connectionURL=jdbc\:postgresql\://localhost:5432/sospos
logLevelSQL=FINEST
connectionPassword=sx_des\#-1\#108\#-75\#72\#-110\#-117\#-34\#-94\#116\#120\#-97\#-28\#-54\#-55\#11\#8
Sie übertragen also die Connection Angaben in die databases.xml und starten den Tomcat neu.
Hinweis: Wenn Sie andere Vorsysteme als Postgres oder Informix nutzen (z.B. MACH unter SQL-Server), müssen Sie auch den jdbc-Treiber der Anwendung vom Rohdatenpfad (z.B. $FIN_LOAD_PFAD/lib/sqljdbc.jar) nach $WEBAPP/WEB-INF/lib kopieren und Tomcat neu starten.
Weitere Infos:
https://wiki.his.de/mediawiki/index.php/Komponentenverwaltung_der_HISinOne-BI
https://wiki.his.de/mediawiki/index.php/Komponenten_Update-HISinOne-BI#Skriptgesteuerter_Update
Wenn Sie den Tomcat benutzen, welcher mit SuperX ausgeliefert wird, wird dieser nicht automatisch vom System geupgradet. Dies muss manuell gemacht werden. Bei kleineren Versionssprüngen wird es sehr wahrscheinlich keine Probleme geben. Bei dem Upgrade auf eine neue Tomcat Version ist aber Vorsicht geboten.
Dieser Leitfaden zur Aktualisierung des Tomcats ist ein Vorschlag von uns, wie Sie den Tomcat aktualisieren können. Wir geben keine Garantie darauf, dass es funktioniert. Bitte sichern Sie zuvor das Dateisystem von SuperX und die Datenbank um bei eventuellen Problemen das System auf den funktionierenden Stand wieder zurück bringen zu können.
Bitte laden Sie sich hier: http://tomcat.apache.org/ die Version des Tomcats herunter, welche Sie verwenden möchten.
Nun beenden Sie den Tomcat und benennen das Verzeichnis $SUPERX_DIR/webserver/tomcat nach z.B. $SUPERX_DIR/webserver/old_tomcat um (eventuell verwenden Sie noch ein Datum in Dateinamen). Danach erstellen Sie wieder den Ordner $SUPERX_DIR/webserver/tomcat und entpacken dort das heruntergeladene Archiv. Aus dem alten Tomcat übernehmen Sie nun so wenig wie möglich, aber alle nötigen Konfigurationsdateien aus conf in den neuen Tomcat. Nun verschieben Sie noch den Ordner $SUPERX_DIR/webserver/old_tomcat/webapps/superx nach $SUPERX_DIR/webserver/tomcat/webapps/superx und der neue Tomcat sollte funktionieren. Sie können nun den neuen Tomcat starten und die Funktion im Browser testen.
Das Kernmodul besteht aus der Userverwaltung, der Maskenverwaltung sowie aus dem Organigramm. Die wichtigsten Tabellen des Kernmoduls sind im folgenden aufgeführt.
Die Basisdaten und zusätzlichen Schlüssel der weiteren Module werden nach folgender Konvention nach SuperX übernommen:
|
Tabellenname |
<Basisdatenbank>_<Name der Tabelle in der Basisdatenbank> |
|
Beispiele |
"cob_busa" oder "mbs_inst" |
Die User- und Gruppenverwaltung geschieht über eine Reihe von Tabellen, die User, Gruppen, Institutionen, thematische Sachgebiete und einzelne Abfragen in Beziehung setzen. Die Tabellen werden im folgenden dokumentiert. Client-Formulare zur Benutzerverwaltung finden Sie hier .
Die Userverwaltung beruht auf einige Tabellen, die Stammdaten und Beziehungen zu anderen Tabellen (z.B. Masken) abbilden.
Die Tabelle userinfo enthält die Angaben zur Person, d.h. email, Nutzerkennung, Passwort etc.
Tabelle userinfo
|
Feld |
Erläuterung |
Beispiel |
|
tid |
Id-Nummer |
1 |
|
benutzer |
Nutzerkennung für Anmeldung |
testuser |
|
kennwort |
Passwort alter Client |
frsgrgr |
|
name |
Name der Person |
Ein Testuser ohne Name |
|
max_versuch |
Maximale Logins |
5 |
|
akt_versuch |
Aktuelle Login-Versuche |
0 |
|
|
Email-Adresse |
test@uni.de |
|
administrator |
Administrator-Rechte (1=ja, 0=nein) |
0 |
|
archiv_recht |
Leserechte auf Archiv (1=ja, 0=nein) [im alten Client] |
0 |
|
passwd_sha |
Passwort neuer Client (SHA-1-verschlüsselter HexCode) |
|
|
info |
Beschreibung des Users (Sachgebiet, Fachgebiet) |
SG 22 |
Diese Tabelle kann manuell gepflegt werden und bildet die Grundlage für die Benutzerverwaltung in SuperX. Die Tabelle wird mit mehreren Tabellen verknüpft, z.B. user_group_bez.
Die Benutzerpassworte werden sha-verschlüsselt gespeichert. Sie können auch externe Daten in diese Tabelle füllen, z.B. aus einer anderen Benutzerverwaltung. Die Passwort-Verschlüsselung müssen Sie allerdings selbst vornehmen. Unter PostgresSQL kann dieses Verfahren elegant automatisiert werden, dort gibt es mit dem Paket pgcrypto eine Möglichkeit, SHA-Digests scriptgesteuert zu erzeugen. Die Syntax lautet:
select encode(digest('<<Klartext-Passwort>>', 'sha1'), 'hex');
Rechte einzelner User für einzelne (Abfrage-)Masken werden in der Tabelle
user_masken_bez
gespeichert:
Tabelle user_masken_bez
|
Feld |
Erläuterung |
Beispiel |
|
userinfo_id |
Nummer des Benutzers (entspricht dem Feld tid in der Tabelle userinfo ) |
1 |
|
maskeninfo_id |
Nummer der Maske (entspricht dem Feld tid in der Tabelle maskeninfo s.u.) |
10050 |
Der testuser , der den tid-Eintrag 1 in der Tabelle userinfo hat, bekommt Zugriffsrechte für die (Abfrage-)Maske mit der Nummer 10050 (Studierende allgemein).
Falls Sie Einzelrechte für (Abfrage-)Masken vergeben wollen, machen Sie einen Eintrag in der Tabelle user_masken_bez .
Damit man nicht jedem Benutzer für jede (Abfrage-)Maske einzeln Rechte geben muss, gibt es sog. Sachgebiete.
In SuperX gibt es u.a. die Sachgebiete
Studierende/Prüfungen
Personal/Stellen
Gebäude/Räume/Flächen
Kennzahlen
Haushalt.
Diese Sachgebiete finden sich in der Tabelle sachgebiete .
Tabelle sachgebiete
|
Feld |
Erläuterung |
Beispiel |
|
tid |
Nummer des Sachgebiets |
1 |
|
name |
Name des Sachgebiets |
Studierende/Prüfungen |
In der Tabelle sachgeb_maske_bez wird die Beziehung von (Abfrage-)Masken zu Sachgebieten festgelegt.
Tabelle sachgeb_maske_bez
|
Feld |
Erläuterung |
Beispiel |
|
sachgebiete_id |
Nummer des Sachgebiets (entspricht dem Feld tid in der Tabelle sachgebiete ) |
1 |
|
maskeninfo_id |
Nummer der Maske (entspricht dem Feld tid in der Tabelle maskeninfo s.u.) |
10050 |
Das Beispiel bedeutet, dass die Abfrage Studierende Allgemein (Nr. 10050) zum Sachgebiet Nr.1 (Studierende/Prüfungen) gehört.
Man kann dann einem Benutzer Zugriffsrechte für ein komplettes Sachgebiet (z.B. Studierende/Prüfungen) geben. Dazu macht man einen Eintrag in die Tabelle user_sachgeb_bez .
Tabelle user_sachgeb_bez
|
Feld |
Erläuterung |
Beispiel |
|
userinfo_id |
Nummer des Users (entspricht dem Feld tid in der Tabelle userinfo ) |
1 |
|
sachgebiete_id |
Nummer des Sachgebiets (entspricht dem Feld tid in der Tabelle sachgebiete ) |
1 |
Das Beispiel bedeutet,dass der User Nr. 1 ( testuser ) alle Masken aufrufen darf, die zum Sachgebiet Nr. 1 (Studierende/Prüfungen) gehören. Da über die Sachgebietseintragungen Rechte verwaltet werden, sollte hier pro Maske nur eine Eintragung erfolgen (im Gegensatz zum alten Client).
Weiterhin kann festgelegt werden, für welche Institutionen ein Benutzer Informationen erhalten darf.
Die Tabelle user_institution ordnet die Leserechte einer Person auf die Institutionen im Organigramm zu. Wenn ein User alle Institutionen einsehen darf, dann ist es notwendig, einen Datensatz zum User mit dem Wert 0 im Feld ch110_institut hinzufügen (Gültigkeitszeitraum beachten!). Der Übersichtlichkeit halber sollte man im Feld Name dann "Alle" eintragen.
In der Downloadversion des Kernmoduls enthält diese Tabelle zwei Beispielsätze: der User "admin" hat die Leserechte auf einen Fachbereich und auf alles.
Tabelle user_institution
|
Feld |
Erläuterung |
Beispiel |
|
userid |
Nummer des Benutzers (entspricht dem Feld tid in der Tabelle userinfo ) |
1 |
|
name |
Name der Institution (entspricht dem Feld name in der Tabelle organigramm ) Eingaben nicht unbedingt erforderlich |
TestFB |
|
ch110_institut |
Nummer der Institution (entspricht dem Feld key_apnr in der Tabelle organigramm ) |
11 |
|
hierarchie |
Hierarchieebene (0,1,2,3) [wird in Zukunft für COB-Abfragen benutzt] |
|
|
gueltig_seit |
Gültigkeit der Rechte: Anfang |
1.1.2001 |
|
gueltig_bis |
Gültigkeit der Rechte: Ende |
31.12.2001 |
|
lehre |
Freigabe einer Lehrheit bei lehrbezogenen Abfragen Wenn ein User z.B. keine Rechte für die Lehreinheit Physik hat, sondern nur für das untergeordnete Institut A, kann man hier beim Eintrag der Lehreinheit Physik das Feld auf 1 setzen, damit der User bei lehrbezogenen Abfragen (z.B. Mittelberechnung) trotzdem die Rechte für die Lehreinheit erhält. In allen anderen Fällen muss hier null stehen.
|
null |
Der testuser erhält im Beispiel das Recht den TestFB (ch110_institut - key_apnr=11) im Zeitraum vom 1.1.2001 bis zum 31.12.2001 einzusehen.
Die Masken, die einen Organigramm-Button enthalten, arbeiten mit den Prozeduren sp_user_orga bzw. sp_user_orga_child , die die Institutionen zusammensuchen und in eine temporäre Tabelle schreiben.
Man braucht nicht jedem User einzeln Rechte für (Abfrage-)Masken geben, sondern kann dies auch über die Zugehörigkeit zu einer Gruppe erledigen.
Die Gruppennamen werden in der Tabelle groupinfo festgelegt.
Tabelle groupinfo
|
Feld |
Erläuterung |
Beispiel |
|
tid |
Nummer der Gruppe |
0 |
|
name |
name der Gruppe |
Dezernenten |
Die Zugehörigkeit eines Users zu einer Gruppe wird in der Tabelle user_group_bez festgelegt.
Tabelle user_group_bez
|
Feld |
Erläuterung |
Beispiel |
|
userinfo_id |
Nummer des Users (entspricht dem Feld tid in der Tabelle userinfo ) |
1 |
|
groupinfo_id |
Nummer der Gruppe (entspricht dem Feld tid in der Tabelle groupinfo ) |
1 |
Der testuser (Nr. 1) wird zur Gruppe 1 (Dezernenten) gerechnet.
Die Gruppenrechte werden in den Datenbank-Tabellen group_masken_bez und group_sachgeb_bez gespeichert.
In der Tabelle group_masken_bez wird festgelegt, auf welche (Abfrage-)Masken die Gruppe Zugriff haben soll.
Tabelle group_masken_bez
|
Feld |
Erläuterung |
Beispiel |
|
groupinfo_id |
Nummer der Gruppe (entspricht dem Feld tid in der Tabelle groupinfo ) |
0 |
|
maskeninfo_id |
Nummer der Maske (entspricht dem Feld tid in der Tabelle maskeninfo s.u.) |
10050 |
Das Beispiel besagt, dass die Gruppe der Dezernenten (und damit alle User, die dieser Gruppe zugeordnet sind), Zugriffsrechte für die (Abfrage-)Maske 10050 (Studierende allgemein) hat.
Wie bei einzelnen Usern kann man auch bei Gruppen Zugriffsrechte auf ganze Sachgebiete festlegen. Dies geschieht in der Tabelle group_sachgeb_bez .
Tabelle group_sachgeb_bez
|
Feld |
Erläuterung |
Beispiel |
|
groupinfo_id |
Nummer der Gruppe (entspricht dem Feld tid in der Tabelle groupinfo ) |
0 |
|
sachgebiete_id |
Nummer des Sachgebiets (entspricht dem Feld tid in der Tabelle sachgebiete ) |
1 |
Das Beispiel zeigt die Freigabe des Sachgebiets 1 (Studierende/Prüfungen) für die Gruppe der Dezernenten. Die Reihenfolge der Berücksichtugng von Rechten ist wichtig. Werden innerhalb eines Sachgebiets Einzelrechte auf eine Abfrage vergeben, dann müssen bei jeder neuen Abfrage in diesem Sachgebiet wieder Einelrechte vergeben werden.
Alle fehlgeschlagenen Anmeldeversuche an die Datenbank SuperX werden protokolliert (proto_fkt_id=2). Die Protokollierung dient nur der Überwachung der Autorisierung des Anmeldenden; darüber hinaus findet keinerlei Aufzeichnung von Benutzeraktivitäten o. ä. statt. Die maximale Anzahl der Anmeldeversuche ist für jeden Benutzer einstellbar (Tabelle ,userinfo', Feld ,max_versuch') und ist standardmäßig auf 5 Versuche eingestellt. Wird die maximale Anzahl überschritten, so wird die Benutzerkennung gesperrt. Der SuperX-Administrator könnte sich zusätzlich ein per Cronjob aufzurufendes Skript einrichten, dass bei Häufung von fehlgeschlagenen Anmeldungen ein Warnemail verschickt.
Die Tabelle Protokoll enthält die Protokollsätze der Zugriffe auf SuperX.
|
Attributname |
Bedeutung |
Typ |
|
protokoll_id |
ID des Protokollsatzes |
serial |
|
proto_fkt_id |
Nummer der Protokollfunktion (siehe Tabelle proto_funktion) |
smallint |
|
userinfo_id |
Benutzer-ID (aus Tabelle userinfo) |
integer |
|
ip_adresse |
IP-Adresse des Benutzers |
char(16) |
|
client_name |
Rechnername des Benutzers bzw. Fehlermeldung, wenn keine Netzverbindung möglich war (WINSOCKET -Fehler etc.) |
char (255) |
|
zeitpunkt |
Zeitpunkt des protokollierten Ereignisses |
datetime year to second |
Diese Tabelle enthält Funktionen, die protokolliert werden.
|
Feld |
Bedeutung |
Typ |
|
proto_fkt_id |
Nummer der Protokollfunktion |
smallint |
|
proto_fkt |
Name der Protokollfunktion |
char(20) |
Inhalt der Tabelle proto_funktion :
|
proto_fkt |
Bedeutung |
|
LOGIN |
Benutzer ist angemeldet |
|
LOGIN_FAIL |
falsches Paßwort eingegeben |
|
LOGIN_LOCKED |
Kennung gesperrt (Versuche> max_versuch) |
|
LOGOUT |
Benutzer hat sich abgemeldet |
|
CH_PASSWD_OLD |
Paßwort im Paßwortänderungsdialog eingegeben |
|
CH_PASSWD_NEW |
Neues Paßwort im Paßwortänderungsdialog vergeben |
|
CH_PASSWD_FAIL |
Falsches Paßwort im Paßwortänderungsdialog eingegeben |
Das Organigramm stellt eine integrierende Sicht für verschiedene Datenquellen zusammen und ist somit die Voraussetzung für eine integrierte Betrachtung. Alle Einrichtungen, Institutionen und Projekte sind im Organigramm hierarchisch angeordnet.
Die folgende Abbildung zeigt ein Beispiel für ein Organigramm:
|
Wie im Themenbaum können Sie durch einen hierarchischen Baum navigieren. |
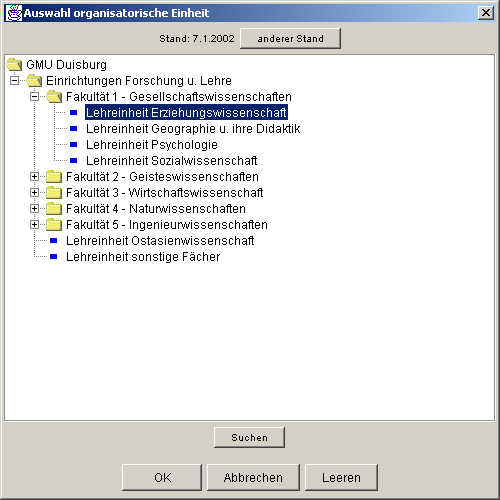
|
Das Organigramm wird vom Java-Applet aus der Tabelle organigramm unter Berücksichtigung der Userrechte aufgebaut.
Das Kernmodul enthält bei Auslieferung das Organigramm der Universität Duisburg als Beispiel. Die Datensätze können nach der Installation als Vorlage dienen.
|
Feld |
Erläuterung |
Beispiel |
|
tid |
Interne Nummer |
|
|
key_apnr |
Institutionennummer (z.B. im MBS) |
"1" |
|
parent |
key_apnr der übergeordneten Institution |
"0" |
|
drucktext |
Kurzer Text |
Einr. Forsch. und Lehre |
|
name |
Name der Institution |
Einrichtungen Forschung und Lehre |
|
ebene |
Hierarchieebene |
1 |
|
lehre |
Ist diese Institution relevant für Auswertungen im Bereich Lehre (1=ja, 0=nein); das Feld darf nicht leer sein |
1 |
|
gueltig_seit |
Beginn des Gültigkeitszeitraums |
1.10.2001 |
|
gueltig_bis |
Ende des Gültigkeitszeitraums |
31.12.2999 |
|
orgstruktur |
In diesem Feld wird festgelegt, dass es sich bei einem Eintrag um eine besondere Institution handelt. Wenn es sich um einen Fachbereich handelt, trägt man 20 ein, wenn es sich um eine Lehreinheit handelt 30. |
|
Bei der Gültigkeit bestehen einige Abhängigkeiten. Z.B. müssen bei Lehreinheiten als Anfang/Ende jeweils die Semestertermine genommen werden (also Lehreinheit alt gültig_bis 30.9.2001, Lehreinheit neu gültig_seit 1.10.2001).
Generell sollten Einrichtungen, die unbegrenzt gültig sind, im Feld gueltig_bis das Datum "31.12.2999" haben.
Erläuterung des parent-Felds:
Das Parent-Feld gibt die key_apnr der übergeordneten organisatorischen Einheit an. Das root-Element des Baums besitzt als parent einen null-Wert. Das Organigramm darf demenstprechend nur ein Element haben, dass keinen parent besitzt. Hier sollte grundsätzlich die Hochschulnummer eingetragen werden die auch in anderen HIS-Programmen verwendet wird. In Duisburg ist dies z.B. der Basiseintrag key_apnr = "70" ( GMU Duisburg ). Es ist praktisch der oberste "Knoten" im Baum. Dann werden alle Einträge in der Tabelle organigramm gesucht, die parent="70" haben – also direkte Kinder des Basiseintrags.
Hier findet sich u.a. Einrichtungen Forschung und Lehre (key_apnr="7", parent="70"). Dieser Eintrag hat wiederum u.a. folgende Kinder:
Fakultät 1 (key_apnr="1100", parent="7")
Fakultät 2 (key_apnr="1200", parent="7")
Faktultät 3 (key_apnr="1300", parent="7")
usw.
Die weiteren Äste des Baums werden rekursiv abgefragt.
Das Organigramm kann von Anwendern, die das "alte" SuperX bereits nutzen, relativ einfach importiert werden. Bei Neuinstallation von SuperX kann man (falls vorhanden) von der Institutionentabelle in MBS ausgehen (im SuperX-MBS-Modul lautet diese Tabelle mbs_inst ). Der Imort würde lauten
alter table organigramm modify (tid serial);
insert into organigramm select 0, inst_nr, uebinst_nr, lname1, lname2, "", 0, key_von, key_bis, orgstruktur from inst;
alter table organigramm modify (tid integer, key_apnr char(10), parent char(10));
Danach könnte man diese recht "flache" Hierarchie nachbearbeiten bzw. nicht gewünschte Unterorganisationen streichen. Nachträglich müssen alle Organisationseinheiten, die oberhalb einer Lehreinheit liegen (z.B. Fakultäten), sowie die Lehreinheiten selbst, auf lehre = 1 stehen.
Die Prozedur sp_user_orga sucht die Institutionen, die ein User sehen darf, und bereitet sie in einem temporären Organigramm auf (siehe Organigramm ).
sp_user_orga(userid integer default -1, p_datum date default today, p_lehre smallint)
Liefert für angegebenen Stand alle org. Einheiten zurück, die ein Benutzer sehen darf,
|
p_lehre=0 |
alle org. Einheiten, für die ein Benutzer Rechte hat |
|
p_lehre=1 |
nur org. Einheiten aus dem Bereich Lehre, für die der Benutzer Rechte hat |
|
p_lehre =2 |
Benutzer darf alle org. Einheiten im Bereiche Lehre sehen |
Die Prozedur sp_user_orga_child generiert die Tabelle tmp_ch110institut , die wiederum in der Abfrage aufgerufen wird und die alle Institutionen enthält, die ein User sehen darf und ausgewählt hat, d.h. den aktuellen „Ast“ des Users im Organigramm.
sp_user_orga_child(userid integer default -1, p_datum date default today, p_lehre smallint, p_key_apnr integer, p_erlaubt smallint)
Liefert für einen angegebenen Stand alle Untereinheiten einer org. Einheit, die ein Benutzer einsehen darf .
|
p_lehre=0 |
alle, |
|
p_lehre=1 |
nur die für den Bereich Lehre, |
Aufruf steht im select_stmt (Tabelle maskeninfo ), Änderungen dort
|
p_erlaubt = 0 |
Benutzer darf Einheit nicht komplett einsehen, nur ein oder mehrere untergeordnete Einheiten (z.B. nicht der gesamte FB6 – nur Geographie) |
|
p_erlaubt = 1 |
Benutzer darf die gewählte Einheit mit allen Untereinheiten einsehen. p_erlaubt wird vom Applet gesetzt. |
Beispielaufruf in einem SQL-Script:
Informix:
execute procedure sp_user_orga_child ( <<USERID>>,<<Organigramm-Stand>>, 0, <<Institution>>, <<erlaubt>>)
Variablen in << >> werden vor der Ausführung z.B. wie folgt ersetzt
User1, Fachbereich 6 (Interne Nummer = 6), Stand 1.5.2002, den der User komplett einsehen darf:
execute procedure sp_user_orga_child (1, "1.5.2002", 0, "6", 1)
Postgres:
select sp_user_orga_child ( <<USERID>>,<<Organigramm-Stand>>, 0, <<Institution>>, <<erlaubt>>);
Im folgenden werden die grundlegenden Tabellen für die Verwaltung der SuperX-Auswertungen bzw. Abfragen erläutert.
Basis einer SuperX-Abfrage ist ein Eintrag in der Tabelle maskeninfo . Eigene Masken müssen immer in einem definierten Nummernkreis liegen (z.B. >=10.000, <20000) ) und Zehnerzahlen sein (z.B. 10050).
Tabelle maskeninfo
|
Feld |
Erläuterung |
Beispiel |
|
tid |
Interne Nummer |
10050 |
|
name |
Name der (Abfrage-)Maske
|
Studierende Allgemein |
|
select_stmt |
SQL-Audrücke, die die Abfrage durchführen |
SQL-Statement (s) |
|
xil_proplist |
beschreibt den Aufbau der Ergebnistabelle (s.u.) |
|
|
chart_xtitel |
für graphische Darstellung der Ergebnisse [derzeit nur im alten Client] |
|
|
chart_ytitel |
für graphische Darstellung der Ergebnisse [derzeit nur im alten Client] |
|
|
erlaeuterung |
Erklärungstext zur Maske |
|
|
cleanup_stmt |
SQL-Ausdruck nach select_stmt, z.B. um temporäre Tabellen wieder zu löschen |
drop table tmp_stud; |
|
default_file |
[wird derzeit nur vom alten Client genutzt] |
|
|
frontend |
Ausgabefrontend (Applet, XML-Frontend, Angular Oberfläche (HIS)) |
|
|
breite |
Breite der Maske in Pixel |
|
|
hoehe |
Höhe der Maske in Pixel |
|
|
ampel |
[wird derzeit nur vom alten Client genutzt] |
|
|
hilfe |
Kennzeichen, ob Java-Hilfetext vorliegt (1=ja, 0=nein) |
|
|
hinweis |
Erläuterungstext zur Ergebnistabelle, wird im Kopf angezeigt |
<<SQL>> select erlaeuterung from koepfe_oder_faelle where apnr = "<<Köpfe oder Fälle>>" |
Die für die Suchanfrage einer Maske notwendigen SQL-Ausdrücke sind in der Tabelle maskeninfo im Blob-Feld select_stmt abgelegt.
Ein kleines Beispiel soll die Besonderheiten der SuperX-Suchanfragen erläutern.
|
Feld |
Eintrag |
|
name |
Auslastung |
|
select_stmt |
select lehreinheit, export, auslastquote from auslastung where jahr = <<Jahr>> /*and lehreinheit = <<Lehreinheit>> */ into temp tmp_auslastung with no log; select * from tmp_auslastung order by 1 ; |
|
cleanup_stmt |
drop table tmp_auslastung; |
Es handelt sich hierbei um eine Maske zur Bestimmung der Auslastung einer Lehreinheit. Auf der Auswahlmaske gibt es 2 Felder: Jahr und Lehreinheit. Jahr ist ein obligatorisches, Lehreinheitein fakultatives Eingabefeld.
Für jedes Eingabefeld gibt es im select_stmt eine Variable << >>, die beim Auswerten der SQL Anweisungen durch den Inhalt des Feldes ersetzt wird. <<Jahr>> wird durch das vom User gewählte Jahr er setzt. Handelt es sich wie bei <<Lehreinheit>> um ein fakultatives Eingabefeld, so kann der Feldinhalt leer sein. In diesem Fall wird zusätzlich der Teil der SQL-Anweisung auskommentiert (/*...*/), in dem die entsprechende Variable vorkommt (zwischen 2 Kommentarklammern (/*...*/) muss genau eine Feldvariable stehen!). Falls eine Lehreinheit vom User ausgewählt wird (z.B. 50000=Psychologie) wird die Zeile and lehreinheit =50000 mit ausgeführt. Wenn keine Lehreinheit ausgewählt wurde, bleibt sie unberücksichtigt und man erhält einen Gesamtwert über alle Lehreinheiten.
Der Variablen <<UserID>> kommt eine Sonderbedeutung zu: Sie ist im Applet als verborgenes Feld vorhanden. Für <<UserID>> wird die Nummer des Benutzers eingesetzt (vgl. sp_user_orga_child, s.o.).
|
! |
Wichtig:Die letzte SQL-Anweisung muss ein select-Ausdruck sein, der das Ergebnis der Suchanfrage liefert. Das Ergebnis steht in unserem Beispiel in der temporären Tabelle tmp_auslastung. Diese Tabelle muss nach der Ausführung des select-Ausdrucks noch entfernt werden. Dafur gibt es das Feld cleanup_stmt, dessen Inhalt nach Ausführung von select_stmt ausgewertet wird. |
Das Suchergebnis wird in einer Ergebnistabelle auf einer speziellen Suchergebnismaske dargestellt. Die Definition der Ergebnistabelle geschieht durch besondere Tags, die im Feld xil_proplist gespeichert werden.
Wichtig ist, dass für die Ergebnistabelle die Anzahl der selektierten Felder größer sein darf als die Anzahl der COLUMNS in XIL-List sein, aber nicht umgekehrt . Am einfachsten ist es, die Tabellendefinition einer bestehenden Maske zu kopieren und dann anzupassen.
|
Ein Beispiel für die Abfrage Aufnahmekapazität im aktuellen Studienjahr:
|
^XIL List\ sizable_columns horizontal_scrolling\ white_space_color=COLOR_WHITE\ drop_and_delete movable_columns fixed_columns=1\ min_heading_height=50\ Column CID=0 heading_text="Lehreinheit / Studiengang" center_heading\ row_selectable heading_platform readonly\ width=35 text_size=50\ Column CID=1 heading_text="Aufnahme-\\n kap. o. Ber.\\n Schwundquote" center_heading\ row_selectable col_selectable rightJust heading_platform readonly\ width=14\ Column CID=2 heading_text="Aufnahme-\\n kap. m. Ber.\\n Schwundquote" center_heading\ row_selectable col_selectable rightJust heading_platform readonly\ width=14\ Column CID=3 heading_text="Studierende\\n im 1. FS\\n im Studienj. " center_heading\ row_selectable col_selectable rightJust heading_platform readonly\ width=11\ Column CID=4 heading_text="1. FS / \\n Aufn.kap o.\\n Schwund in %" center_heading\ row_selectable col_selectable rightJust heading_platform readonly\ width=14\ Column CID=5 heading_text="1. FS / \\n Aufn.kap m.\\n Schwund in %" center_heading\ row_selectable col_selectable rightJust heading_platform readonly\ width=14\ Column CID=6 heading_text="Studier.\\n in RSZ\\n im WS" center_heading\ row_selectable col_selectable rightJust heading_platform readonly\ width=8\ Column CID=7 heading_text="Studier.\\n gesamt\\n im WS" center_heading\ row_selectable col_selectable rightJust heading_platform readonly\ width=8 \ @@@
|
Die Attribute zu den Felder werden wie folgt interpretiert:
|
Attribut |
Erläuterung |
|
heading_text |
Spaltenüberschrift |
|
center_heading |
Zeilenausrichtung der Überschrift zentriert |
|
row_selectable |
Zeile ist selektierbar (z.B. für Kopie in Zwischenablage) |
|
col_selectable |
Spalte ist selektierbar |
|
rightjust |
Zeilenausrichtung der Zellen rechtsbündig |
|
heading_platform |
wird z.Zt. nicht genutzt |
|
readonly |
Nicht editierbar |
|
height |
Höhe der Zelle in Pixel (default ist 12) |
|
width |
Breite der Zelle in Pixel (default ist Auto) |
Die einzelnen Felder auf einer Maske (z.B. Semester, Lehreinheit, Haushaltsjahr, Köpfe oder Fälle) sind in der Tabelle felderinfo abgelegt. Gibt es zu einer Maske der Nummer <TID> n Felder, so haben diese in der Tabelle felderinfo die Nummern:
<TID>, <TID>+1, ..., <TID>+n-1
So gehören z.B. zur Maske 10050 "Studierende allgemein", die folgenden Einträge in der Tabelle felderinfo
|
tid |
name |
|
10050 |
Köpfe oder Fälle? |
|
10051 |
Semester |
|
10052 |
Organisatorische Einheit |
|
10053 |
Abschluss |
|
10054 |
bis Fachsemester |
|
10055 |
Hörerstatus |
|
10056 |
Hochschulzugangsberechtigung |
|
10057 |
Staatsangehörigkeit |
|
10058 |
Aggregierung? |
Gibt es mehr als 10 Felder auf einer Maske, so entfällt die entsprechende Zehnerzahl als Nummer für eine andere Maske, man sollte aber sicherheitshalber eine entsprechenden Eintrag in maskeninfo machen.
In der Tabelle felderinfo sind die einzelnen Auswahlfelder einer Maske abgelegt (s.o.).
Die Lage der Felder auf der Maske wird durch die Attribute x und y bestimmt. Der Ursprung des Koordinatensystems eines Fensters ist die obere linke Ecke, die y-Achse geht nach unten. Die Felder werden mit dem Offset (z.B. 60,60) platziert.
|
|
Tabelle felderinfo Erläuterung |
|
|
tid |
Interne Nummer |
|
|
name |
Name des Feldes auf der Maske
|
|
|
nummer |
Nummer des Feldes auf der Maske |
|
|
x |
x-Position auf der Maske |
|
|
y |
y-Position auf der Maske y = 0 : Gehe in die nächste Zeile y = -1 : Bleibe in der aktuellen Zeile sonst : Nehme y als absoluten (auf die Maske bezogenen) y-Wert |
|
|
buttonbreite |
Die Feldnamen werden durch SuperX rechtsbündig angeordnet. Die dafür vorgesehene Breite wird mit dem Attribut buttonbreite definiert und in Pixel angegeben. Der Wert 100 reicht in den meisten Fällen aus. buttonbreite = 0 : Übernehme die entsprechenden Werte vom vorhergehenden Feld |
|
|
feldbreite |
Die Breite des Eingabefeldes wird mit feldbreite bestimmt. Häufige Wer1e sind 70 für kurze Felder (z.B. Rechnungsjahr) oder 200 für längere Felder (z.B. Institution). feldbreite = 0 : Übernehme die entsprechenden Werte vom vorhergehenden Feld |
|
|
zeilenanzahl |
Für die Anzahl der Zeilen des Eingabefeldes gibt es das Attribut zeilenanzahl. zeilenanzahl = 1 : Es kann höchtens ein Wert im Eingabefeld angegeben werden. zeilenanzahl> 1 : Es können mehrere Werte im Eingabefeld angegeben werden. Eingabefeld besitzt Scroll-Leiste. Damit das Eingabefeld nicht zu groß wird, reicht zeilenanzahl = 3 aus.
Achtung
: Bei Mehrfachauswahlfeldern, die als Werte
integer
-Schlüssel zurückgeben sollen, muss beim folgenden Attribut typ der Wert
sql
eingetragen werden. In SuperX werden die einzelnen Werte mit "," getrennt, z.B. |
|
|
typ |
In SQL-Ausdrucken wird zwischen numerischen und alphanumerischen Werten unterschieden. Alphanumerische Werte müssen mit Hochkommas versehen werden. Aus diesem Grund gibt es in SuperX verschiedene Typen von Feldern: typ = integer : Es werden für dieses Feld in dem SQL-Ausdruck der Suchanfrage keine Hochkommas eingesetzt. typ = char : Im select_stmt werden automatisch Hochkommata um den Variablenwert gesetzt. Bei Mehrfachauswahlfeldern gibt es eine Sonderbehandlung (s.o.). typ = sql : Das Ergebnis des Feldes liefert einen SQL-Ausdruck. Im select_stmt werden keine Hochkommas eingefügt. typ = date :Es werden für dieses Feld in dem SQL-Ausdruck der Suchanfrage date('...') eingesetzt, bei PostgreSQL lautet die Funktion date_val('...'). typ = decimal :Der eingegebene Wert (mit "," als Dezimaltrennzeichen) wird im SQL-Ausdruck der Suchanfrage mit "." als Dezimaltrennzeichen versehen. |
|
|
laenge |
zur Zeit nicht genutzt |
|
|
obligatorisch |
Eingabe kann zwingend (obligatorisch =1) oder freiwillig sein (obligatorisch = 0) |
|
|
art |
In den operativen Systemen wird oft mit Schlüsselwerten (z.B. Institutsnummern) gearbeitet. Um selbsterklärend zu sein, werden in SuperX nur intern diese Nummern verwendet. Nach außen sieht der Anwender den Klartext (z.B. den Institutsnamen). Für die Felder muss unterschieden werden, ob eine Nummemausprägung existiert. Daher gibt es verschiedene Arten von Feldern: art = 0 : SuperX verwaltet nur den Wert des Eingabefeldes. In diese Felder kann man immer direkt Werte eingeben. Die Eingabe über einen Dialog ist wahlweise möglich (siehe Abschnitt Dialogsteuerung ). art = 1 : Eine Dialogbox wird geöffnet, die eine Liste mit Auswahlmöglichkeiten anzeigt. Die Datenquelle ist eine Tabelle oder ein SQL-Ausdruck, wobei die erste Spalte unsichtbar ist und den Rückgabewert der Dialogbox liefert. In diese Felder kann man nicht direkt, sondern nur über einen Dialog Werte eingeben. art = 2 : Genau wie art = 1. Die Auswahlwerte des Dialogs können jedoch nur durch Angabe einer Stored Procedure bestimmt werden. art = 3 : Feld zur Auswahl einer Datei mit Hilfe des plattformspezifischen Dateiauswahldialogs. Eine direkte Eingabe ist nicht möglich, das Feld ist nur einzeilig. Wird in Version 2.0 des Applets noch nicht umgesetzt. art = 4 : Es handelt sich um ein Feld zur Auswahl einer Institution oder Person. Dazu wird ein spezieller Dialog geöffnet, der die hierarchische Struktur der Hochschule widerspiegelt. Dabei werden alle Institutionen angezeigt, für die der Benutzer Zugriffsrechte hat. art = 5 : SuperX verwaltet nur den Wert des Eingabefeldes. Im Unterschied zu art = 0 ist eine direkte Eingabe nicht möglich. Die Art kann für die Gestaltung von Kommentarzeilen genutzt werden. art = 6 : wie art=4, aber es erscheinen nur alle Institutionen im Bereich Lehre, für die der Benutzer Rechte hat (lehre=1 in der Tabelle organigramm ) art = 7 : wie art=4, aber es erscheinen alle Institutionen im Bereich Lehre (lehre=1 in der Tabelle organigramm) ohne Rechteeinschränkung art = 8 : Das Feld dient nur als Label, es erscheint kein Eingabefeld art = 12 : Sicht, in Spalte relation muss ein SQL stehen, der die tids der gewünschten Sichten aus der Sichtentabelle liefert |
|
|
relation |
wird für Dialogsteuerung benötig, s.u. |
|
|
attribut |
Feld in der DB-Tabelle, die man in relation angegeben hat (s. Dialogsteuerung) |
|
|
default_wert |
Vorgabewerte für den Feldinhalt (s.u.) |
|
Überwiegend erfolgt die Eingabe in die Felder dialoggesteuert, das heißt der Anwender kann aus einem Dialog mögliche Eingabewerte auswählen. In der Tabelle felderinfo kann zu jedem Feld definiert werden, wie die möglichen Auswahlwerte des Dialoges lauten. Um selbsterklärend zu sein, sollte der Anwender nur Klartext sehen. Die entsprechende Nummernausprägung verwendet SuperX nur intern. Die Bestimmung der Auswahlwerte eines Dialogs geschieht entweder durch Angabe einer DB-Tabelle und eines dazugehörigen Attributs, durch Angabe einer Stored Procedure oder eines SQL-Ausdrucks. Soll die Feldeingabe mit Hilfe eines Dialoges nicht möglich sein, so müssen die Einträge für relation und attribut leer bleiben.
Soll z.B. auf einer Studierenden-Maske das Semester ausgewählt werden können, so steht in der Tabelle felderinfo :
|
Feld |
Eintrag |
|
name |
Semester |
|
relation |
semester |
|
attribut |
eintrag |
In der SuperX-Datenbank gibt es dazu die Tabelle semester .
|
Feld |
Erläuterung |
Beispiel |
|
tid |
Interne Nummernausprägung des Semesters |
20011 |
|
eintrag |
Semester als Klartext |
SS 2001 |
|
sem_beginn |
Datum des Semesterbeginns |
01.04.2001 |
|
sem_ende |
Datum des Semesterendes |
30.09.2001 |
Statt einer DB- Tabelle kann auch eine Stored Procedure angegeben werden. Diese wird beim Maskenaufbau ausgeführt und liefert als Rückgabewerte die Auswahlwerte des Dialogs.
Damit SuperX zwischen einer Tabelle und einer Stored Procedure unterscheiden kann, muss der Name der Stored Procedure mit "sp_" beginnen. Bei Feldern mit art = 2 ist diese Konvention nicht erforderlich.
Häufiges Beispiel sind Felder, deren Eingaben aus der CIF (Central Information File) kommen. Hier die Tabelle felderinfo für ein Feld, mit welchem die Dienstart ausgewählt werden soll (in der CIF: hochschulallgemeiner Schlüssel der Nummer 107):
|
Feld |
Eintrag |
|
name |
Dienstart |
|
relation |
sp_cif(0,107) |
|
attribut |
|
Die Ergebnisse des angegebenen SQL-Ausdrucks sind die Auswahlwerte des Dialogs. Genau wie bei der Definition von Vorgabewerten für Felder muß der SQL-Ausdruck mit "<<SQL>>" beginnen. Beispiel:
|
Feld |
Eintrag |
|
name |
Etage |
|
relation |
<<SQL>> select distinct geschossnr, druck from baupc-geschoss order by 1; |
|
attribut |
|
Für Felder bei denen eine Nummernausprägung intern verwendet wird (art = 1, 2) ist zu beachten, dass die Stored Procedure bzw. der SQL-Ausdruck 2 Werte (Nummernausprägung und Klartext) zurückliefern muss. Bei Angabe einer Tabelle müssen entweder 2 Attribute angegeben werden (attribut = A1,A2) oder man gibt nur das Attribut für den Klartext an. In diesem Fall geht SuperX davon, dass das Attribut für die Nummernausprägung "tid" heißt. Die Nummernausprägung muss zuerst angegeben werden. Man kann natürlich auch zugleich Nummernausprägung und Klartext in dem Dialog darstellen:
<<SQL>> select geschossnr, druck || "(" || geschossnr || ")" from baupc-geschoss;
Beim Öffnen einer Maske können dem Anwender Vorgabewerte angeboten werden, Dabei handelt es sich entweder um konstante Werte oder um Ergebnisse eines SQL-Ausdrucks:
Ein Feld für die Eingabe eines Rechnungsjahres soll den fest vorgegebenen Wert "2002" besitzen. In der Tabelle felderinfo steht:
|
Feld |
Eintrag |
|
name |
Rechnungsjahr |
|
default |
2002 |
Viel flexibler ist die Definition des Vorgabewertes mit Hilfe eines SQL-Ausdrucks. Damit kann sowohl auf Werte aus der Datenbank als auch auf das aktuelle Datum zugegriffen werden.
Damit SuperX zwischen Konstanten und SQL-Ausdrücken unterscheiden kann, beginnen letztere mit "<<SQL>>" (Leerzeichen nicht vergessen !). Im folgenden Beispiel lautet der
SQL-Ausdruck für das Vorjahr:
|
Feld |
Eintrag |
|
name |
Rechnungsjahr |
|
default |
<<SQL>> select (year(today) -1) || "" from xdummy; |
Die Tabelle xdummy ist eine Tabelle mit einem Satz. Sie dient lediglich dazu, den o.g. SQL-Ausdruck syntaktisch korrekt zu machen.
Für Felder bei denen eine Nummernausprägung intern verwendet wird (art = 1, 2) ist zu beachten, dass der SQL-Ausdruck 2 Werte (Nummernausprägung und Klartext) zurückliefern muss.
Achtung : Vorgabewerte können nicht für Institutions-Felder (art = 4,6,7) angegeben werden. Für mehrzeilige Felder (zeilenanzahl> 1) können lediglich SQL-Ausdrücke angegeben werden.
Die Tabelle systeminfo enthält für einzelne Sachgebiete/System, das Datum des letzten Datenupdates.
Tabelle systeminfo
|
Feld |
Erläuterung |
Beispiel |
|
tid |
interne Nummer |
6 |
|
name |
Name des Systemteils |
Personal/Stellen |
|
datum |
Datum des letzten Datenupdates |
14.1.2002 |
Dier Eintrag aus der Tabelle systeminfo wird über die Tabelle maske_system_bez mit der Tabelle maskeninfo verknüpft; so lassen sich die Abfragen den Systemen zuordnen.
Nach der Anmeldung erhält der User eine Reihe von Auswertungen zur Auswahl in Form eines sog. "Themenbaums". Der Themenbaum wird dynamisch generiert aus der Tabelle themenbaum , die alle Auswertungen und deren hierarchischen Zusammenhang enthält, und den spezifischen Rechten, die der Benutzer hat. Die folgende Abbildung zeigt einen Ausschnitt aus einem Beispiel-Themenbaum.
Das Java-Applet erzeugt aus der Tabelle themenbaum unter Berücksichtigung der Userrechte die graphische Oberfläche.
Hier werden die Themen und Sachgebiete gesammelt und strukturiert. So kann aus der relativ einfachen Zuordnung von Themen (bzw. Masken) und Sachgebieten eine relativ komplexe Hierarchie gebildet werden.
Tabelle Themenbaum
|
Feld |
Erläuterung |
Beispiel |
|
tid |
Interne Nummer |
2 |
|
name |
Name der Maske bzw. des Sachgebiets |
Absolventen |
|
maskeninfo_id |
ID der Maske (entspricht dem Feld tid in der Tabelle maskeninfo ) Bei Sachgebieten bleibt dieses Feld leer. |
10140 |
|
parent |
ID der übergeordneten Maske bzw. des Sachgebiets |
1 |
|
sort |
Sortiernummer |
10 |
|
gueltig_seit |
Beginn des Gültigkeitszeitraums |
1.1.2001 |
|
gueltig_bis |
Ende des Gültigkeitszeitraums |
1.10.3000 |
|
erlaeuterung |
Erläuterungstext bei Überschriften |
|
|
css_class |
CSS-Klasse/n bei HTML Darstellung |
icon icon-magic |
Der hierarchische Aufbau der Tabelle über das Feld parent entspricht dem der Tabelle
organigramm
. Die folgende Tabelle zeigt ein paar Beispieleinträge.
|
tid |
name |
maskeninfo_id |
parent |
sort |
gueltig_seit |
gueltig_bis |
|
5 |
Kennzahlen |
|
1 |
|
01.01.1900 |
01.01.3000 |
|
8 |
Studierende |
|
2 |
|
01.01.1900 |
01.01.3000 |
|
6 |
Gesamtüberblick |
|
5 |
|
01.01.1900 |
01.01.3000 |
|
4 |
Gebäude,Räume,Flächen |
|
1 |
|
01.01.1900 |
01.01.3000 |
|
3 |
Personal/Stellen |
|
1 |
|
01.01.1900 |
01.01.3000 |
|
2 |
Studierende / Prüfungen |
|
1 |
|
01.01.1900 |
01.01.3000 |
|
1 |
Abfragen |
|
|
|
01.01.1900 |
01.01.3000 |
|
88 |
Kostenrechnung |
|
1 |
|
01.01.1900 |
01.01.3000 |
|
81 |
Zeitreihen |
|
2 |
|
01.01.1900 |
01.01.3000 |
|
91 |
Evaluierung |
|
1 |
|
01.01.1900 |
01.01.3000 |
|
92 |
Prüfungen |
|
2 |
|
01.01.1900 |
01.01.3000 |
|
7 |
Haushalt |
|
1 |
|
01.01.1900 |
01.01.3000 |
|
47 |
Flächenarten für Institutionen |
10010 |
4 |
|
01.01.1900 |
01.01.3000 |
|
9 |
Studierende nach Hörerstatus |
10040 |
8 |
|
01.01.1900 |
01.01.3000 |
|
10 |
Studierende allgemein |
10050 |
8 |
|
01.01.1900 |
01.01.3000 |
Die Maske Studierende nach Hörerstatus hat als übergeordneten Knoten das Thema Studierende , und dies wiederum das Thema Studierende/Prüfungen .
Im SuperX können einzelne Masken zu einem Bericht kombiniert werden. Dazu wird ein Makro definiert, und die einzelnen Auswertungen werden dem Makro zugeordnet.
|
Feld |
Erläuterung |
Typ |
|
maskeninfo_id1 |
Makro-Auswertung |
integer |
|
maskeninfo_id2 |
Dem Makro zugeordnete Auswertungen |
integer |
|
nummer |
Ordnungsnummer der Zuordnung |
|
Die Makrofunktionalität ist in der Version 2.02 vom SuperX-Kernmodul wie folgt umgesetzt:
1. Sie erzeugen eine Maske mit allen relevanten Feldern. Diese Maske benötigt kein select_stmt und keine xil_proplist , sie dient gewissermaßen als "Hülle" für die eigentlichen Abfragen.
2. Dann ordnen Sie die vorhandenen Abfragen diese Maske in der obigen Tabelle zu. Mit dem Feld nummer legen Sie die Reihenfolge fest. Achten Sie darauf, daß die Feldnamen in der Makro-Maske mit denen in den Unter-Masken identisch sind.
3. Der Makromechanismus läuft im XML-Frontend automatisch ab. Die Stylesheet-Einstellungen der Makro-Maske überlagern die der etwa vorhandenen Einzel-Masken.
Ein Beispiel im COB-Modul ist das Makro zum Berichtsblatt MSWF NRW.
Für die Abfragen aus den verschiedenen Basissystemen gibt es ein paar regelmäßig wiederkehrende Anfragen, z.B. Aggregierung nach Quartalen und Halbjahren. Deshalb sind diese im Kernmodul angelegt.
Die Tabelle menu_element enthält ausschließlich Metadaten zum Betrieb von SuperX; sie enthält Schlüssel und Erläuterungstexte zu den einzelnen Funktionalitäten in SuperX, z.B. zu den Feldtypen auf einer Maske etc.
Die Tabelle besitzt folgende Struktur:
|
Feldname |
Feldtyp |
Größe |
Default |
Not Null |
Beschreibung |
Fremdschlüssel |
|
id |
INTEGER |
4 |
|
true |
Tupelidentifier |
|
|
element |
VARCHAR |
50 |
|
false |
Art der Variable / des Schlüssels |
|
|
element_value |
VARCHAR |
255 |
|
false |
Codierung oder SQL-Ausdruck |
|
|
description |
VARCHAR |
255 |
|
false |
Kurzer Erläuterungstext |
|
|
nature |
VARCHAR |
255 |
|
false |
Variablentyp / Schlüsseltyp |
|
|
annotation |
VARCHAR |
255 |
|
false |
Langer Erläuterungstext |
|
Die folgende Tabelle zeigt die Metadaten zum Aufbau von Feldern einer Maske. Die "Werte" sind wiederum die Schlüssel, die in der Tabelle Felderinfo als Attibute gefüllt werden.
Die Tabelle aggregierung wird in Abfragen verwendet, um nach bestimmten Merkmalen zu zu summieren oder zusätzliche Kriterien einzufügen.
Die Abfrage Nutzungsprotokolle (intern) benutzt die Tabelle z.B., um auf Zeiträume (Halbjahre, Quartale) einzuschränken.
Die Tabelle besitzt folgende Struktur
|
Feld |
Erläuterung |
Typ |
|
tid |
Tupelidentifier |
integer |
|
ord |
Sortiernummer |
smallint |
|
name |
Beschreibung |
char(30) |
|
kategorie |
Kategorie |
char(30) |
|
wert |
numerischer Wert oder sql-Ausdruck |
char(255) |
Die Schlüsseltabelle cif ist Bestandteil des Kernmoduls und enthält Schlüssel, die in verschiedenen operativen Systemen verwendet werden. Die Tabelle cifx ist eine analoge Schlüsseltabelle, die auch alphanumerische Ausprägungen enthält.
Die Tabellen sind das "Herzstück" des Data Warehouse, und möglichst alle Schlüssel sollen darin enthalten sein. Die Art des Schlüssels wird dirch den Wert "key" bestimmt, und prinzipiell ist es möglich, hochschulspezifische und allgemeine Schlüssel zu pflegen. So gibt es in der cifx z.B. den Schlüssel:
|
Schlüsselname |
ch35_ang_abschluss |
|
Key |
35 |
|
Bedeutung |
Hochschulspezifischer Schlüssel für die angestrebte Abschlussprüfung aus SOS |
Der jeweilige Wert für des Schlüssels steht im feld apnr, und die Kurz- und Langbeschreibungen stehen in den Felder kurz, druck, lang_1 usw.
|
Feld |
Erläuterung |
Typ |
|
tid |
Interne Nummer |
serial |
|
hs |
Hochschul-Nr. (0=Hochschulübergreifend) |
integer |
|
key |
Schlüsselgruppe |
smallint |
|
apnr |
Schlüssel |
integer |
|
d_akt_von |
Datum von |
date |
|
d_akt_bis |
Datum bis |
date |
|
kurz |
Kurzbeschreibung |
char(10) |
|
druck |
Drucktext |
varchar(30) |
|
lang_1 |
Langbeschreibung 1 |
char(50) |
|
lang_2 |
Langbeschreibung 2 |
char(50) |
|
lang_3 |
Langbeschreibung 3 |
char(50) |
Folgende Schlüsselgruppen sind z.B. in SuperX enthalten (Schlüssel in der cifx sind gesondert gekennzeichnet):
|
key |
hs |
Bedeutung |
Schlüsseltabelle |
Herkunft System |
Herkunft Tabelle |
|
12 |
0 |
Staat |
|
|
|
|
13 |
<>0 |
Familienstand |
cifx |
|
|
|
27 |
<>0 |
Grund Beurlaubung |
|
|
|
|
30 |
0 |
Studienfach |
cifx |
|
|
|
30 |
<>0 |
Studienfach |
cifx |
|
|
|
35 |
0 |
HS-Abschluss |
cifx |
|
|
|
35 |
<>0 |
HS-Abschluss |
cifx |
|
|
|
36 |
0 |
Hochschule |
cifx |
SVA / COB |
k_hochschule |
|
39 |
<>0 |
Vertiefungsrichtung |
cifx |
|
|
|
40 |
<>0 |
Studientyp |
|
|
|
|
62 |
<>0 |
Grund Exmatrikulation |
|
|
|
|
86 |
0 |
Dienstverhaeltnis |
|
|
|
|
90 |
<>0 |
Fakultaet fuer Wahlen |
|
|
|
|
95 |
0 |
Anrede / Titel |
cifx |
|
|
|
106 |
0 |
Beurlaubungsgrund |
cifx |
|
|
|
*107 |
0 |
Dienstart |
|
|
|
|
108 |
0 |
Amt-/Dienstbezeichnung |
cifx |
|
|
|
*109 |
0 |
BVL-Gruppe |
|
|
|
|
110 |
<>0 |
Besch.stelle |
|
|
|
|
*115 |
0 |
Haushaltsvermerk |
|
|
|
|
*116 |
0 |
Stellenart |
|
|
|
|
120 |
0 |
Bewährungs-, Zeitaufstieg |
|
|
|
|
212 |
<>0 |
Geldgeber |
cifx |
|
|
|
258 |
0 |
Stellung in der HS |
|
|
|
|
*259 |
0 |
Stellenkategorie |
|
|
|
|
260 |
0 |
Grund Ausscheidung/Befristung |
cifx |
|
|
|
261 |
0 |
Grund fuer das Besetzungsende |
cifx |
|
|
|
268 |
0 |
Staatspruefung-Abschluss |
|
|
|
|
*270 |
0 |
Besetzungsabweichung |
|
|
|
|
284 |
<>0 |
Kapitel |
cifx |
|
|
|
286 |
0 |
Arbeitszeit |
|
|
|
|
*291 |
0 |
Personalkategorie |
|
|
|
|
305 |
0 |
Sperrkennzeichen |
|
|
|
|
500 |
0 |
Mittelschoepfung |
cifx |
|
|
|
501 |
0 |
Staat |
cifx |
|
|
Die vorgegebenen Schluessel sind hier mit * gekennzeichnet und dürfen nicht in die cif geladen werden. Die Tabelle wird im Zuge der Aufnahme von weiteren Modulen (z.B. SOS und SVA) weiter gefüllt.
Die organisatorischen Einheiten des Organigramms werden in SuperX gebündelt; mitunter stammen aus den zugrundeliegenden Basissystemen sehr viel detailliertere bzw. "tiefere" Institutionen, die in SuperX nicht unbedingt von Interesse sind, z.B. die Kostenstellen aus HISCOB. Diese Einrichtungen werden in der Tabelle trans_inst auf übergeordnete Insitutionen des Organigramms projiziert. Die Tabelle hat folgende Struktur:
|
Feld |
Erläuterung |
Typ |
|
tid |
Tupelidentifier |
serial |
|
inst_nr |
Institutionen- bzw. Kostenstellen-Nummer |
char(10) |
|
ch110_institut |
Übergeordnete bzw. zugeordnete Institution im SuperX-Organigramm |
char(10) |
|
name |
Name der Institution |
char(200) |
|
gueltig_von |
Gültigkeit der Projektion: Datum von |
date |
|
gueltig_bis |
Gültigkeit der Projektion: Datum bis |
date |
Bei der Übernahme von Daten aus einem Basissystem wie COB wird dann der Datentabelle das Feld der Institution im SuperX-Organigramm hinzugefügt, in dem die Projektion abgebildet wird: Zum Beispiel die Kostenstelle 1200144 (Werkstatt) wird für den Zeitraum vom 1.1.2001 bis 1.4.2002 der SuperX-Institution 12001 (Lehreinheit Psychologie) zugeordnet:
|
inst_nr |
1200144 |
|
ch110_institut |
12001 |
|
name |
Werkstatt |
|
gueltig_von |
1.1.2001 |
|
gueltig_bis |
1.4.2002 |
Im Ladescript eines Basissystems wird diese Zuordnung dann übertragen:
|
Auszug aus dem Ladescript für HISCOB |
update cob_busa set ch110_institut = (select ch110_institut from trans_inst M where M.inst_nr = cob_busa.instnr and M.d_gueltig_von <= date ("01." || cob_busa.monat || "." || cob_busa.jahr) and M.d_gueltig_bis >= date ("01." || cob_busa.monat || "." || cob_busa.jahr)) where instnr is not null; |
Neben der eigentlichen Kostenstelle "Werkstatt" finden wir also bei obigem Beispiel im Feld ch110_institut die SuperX-Institution "Lehreinheit Psychologie". In allen Statistiken zur Lehreinheit, die auf cob_busa beruhen, wird also die Werkstatt stillschweigend hinzugezählt.
Die Tabelle hochschulinfo enthält die Nummer und den Namen der eigenen Hochschule.
Der Schlüssel der Hochschule wird in der Tabelle cif bzw. cifx benutzt, um hochschuleigene Schlüssel von allgmeinen Schlüsseln abzugrenzen.
Sie können die Hochschulinfo in einem DBFORM pflegen; gehen Sie dazu im XML-Frontend auf "Tabelle suchen"-> hochschulinfo. Sie erhalten ein DBFORM mit einem Datensatz:
|
Wählen Sie Ihre Hochschule aus. Wenn Ihre Hochschule in dem Klappmenü nicht enthalten ist, erfragen Sie die Hochschulnummer bei HIS und tragen sie sie manuell mit einem SQL-Tool in die Tabelle ein. |
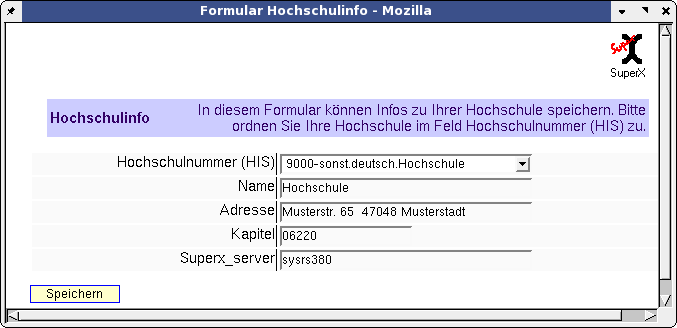
|
SuperX enthält verschiedene Formen von Scripten: Das Laden und die Übernahme der Basisdaten sowie die Erzeugung der Hilfstabellen wird von Shell-Scripten erledigt, wie in der Installationsanleitung der jeweiligen Module dokumentiert. Die Abfragen sind in der Datenbank in der Tabelle maskeninfo sowie felderinfo ; Änderungen sind im Howto dokumentiert. Die Erzeugung von Hilfedokumenten für die Abfragen ist im Abschnitt Javahelp beschrieben.
Das Applet und Servlet wurde in Java programmiert. Änderungen werden im Folgenden beschrieben.
Das Java-Applet und das Servlet sind im Quellcode verfügbar. Für die Entwicklung nutzen wir das Build-Tool Ant, es können aber auch andere Entwicklungsumgebungen eingesetzt werden.
Die SuperX-Quellen haben folgende Struktur:
|
de.superx.applet |
Klassen des SuperX-Applets |
|
de.superx.dbadmin |
Klassen des SuperX-Admintools |
|
de.superx.servlet |
Klassen des SuperX-Servlet |
|
de.superx.bin |
Kommandozeilen-Klassen für den SuperX-Client |
|
de.superx.util |
Gemeinsam benutzte Dateien |
|
de.memtext.* |
Gemeinsam benutzte Utilities der Fa. memtext |
|
images |
Gemeinsam benutzte Grafiken |
|
com.sun.help |
Javahelp-Klassen |
|
javax.help. |
Ebenfalls Javahelp-Klassen |
Auf dem Webserver wird im Verzeichnis
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/lib
die Datei superx<<Versionsnr.>>.jar abgelegt. Diese enthält alle Klassen. Beim Zugriff über Tomcat ist die Datei automatisch im CLASSPATH, beim SuperX-Client via
jdbc
muss diese Datei manuell, z.B. über die Datei
SQL_ENV
, im CLASSPATH sein (Umgebungsvariable JDBC_CLASSPATH).
Das Applet und das Admintool soll wegen WWW-Einsatz möglichst "leicht" sein, deshalb wird es separat kompiliert. Lediglich die Klasse
de.superx.servlet.SuperX_el.class
wird sowohl vom Applet als auch vom AdminTool benötigt. Das Archiv heißt jeweils
superx.jar
für das Applet, und
SuperXDBAdmin.jar
für das Admintool. Beide werden nach
$SUPERX_DIR/webserver/tomcat/webapps/superx/applet
kopiert.
Beachten Sie beim Kompilieren, dass das Applet und das AdminTool bei vielen Browsern im Cache gehalten wird (selbst wenn der Browser immer nach aktuellen Versionen suchen soll). Sie sollten nach neuem Kompilieren sicherheitshalber immer den Cache löschen und den Browser einmal beenden. Alternativ können Sie das Applet auch lokal aus dem Browser starten (also nicht über http://), Sie müssen lediglich eine korrekt eingestellte superx.properties mit gültiger SxServerURL im gleichen Verzeichnis haben.
Aufgrund der Komplexität der eingebundenen Klassen ist ein Build mit normalen Bordmitteln des JDK zwar möglich, aber viel zu umständlich. Der Build läuft voreingestellt nur mit ANT (s.u.) und unter Linux.
Wir empfehlen, Applet und Servlet mit dem im Kernmodul enthaltenen Werkzeug ant zu kompilieren, das bereits in dem SuperX-Kernmodul enthalten ist. Sämtliche Quellen lassen sich von der Konsole aus mit dem Sun JDK 1.4.x und ANT kompilieren. Folgende Pfade sind für Entwickler wichtig:
|
Javadoc-Dateien zum gesamten SuperX-Paket |
$SUPERX_DIR/doc/apidoc |
|
Quellcode des |
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/src/de/superx/applet |
|
Quellcode des |
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/src/de/superx/servlet |
|
Quellcode des |
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/src/de/superx/dbadmin |
|
Ant-Pfad zur |
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/src/build.xml |
|
Ant-Shellscript für den Build |
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/src/build_it.x |
Die Quellen lassen sichmit einem JDK-Compiler der Generation 1.4.x oder höher kompilieren. Zum Kompilieren des Servlets muss die Bibliothek für Servlets im Classpath enthalten sein; dies ist bei der normalen SuperX-Distribution der Fall.
Bei einer eingerichteten Umgebung für SuperX brauchen Sie die build.xml nicht anpassen. Bei benutzerspezifischen Einstellungen passen Sie die Einträge zum CLASSPATH, zur SuperX-Version und zu SUPERX_DIR an. Für die Versionierung wird der Filter-Mechanismus in ant genutzt, d.h. jedesVorkommen des Strings "@version@" wird durch den aktuellen Wert ersetzt, der in der ant-Property VERSION gesetzt ist.
Zur Nutzung von
ant
wechseln Sie in der Konsole in das Verzeichnis
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/src
und rufen Ant wie folgt auf:
|
Kompilieren der Klassen des Applets |
build_it.x compileApplet |
|
Kompilieren und Erzeugen des Applets |
build_it.x distApplet |
|
Dokumentieren des Applets |
build_it.x docApplet |
|
Kompilieren des gesamten Pakets |
build_it.x compileServer |
|
Erzeugen der superx<<Versionsnr>>.jar |
build_it.x distServer |
|
Dokumentieren des Servlets |
build_it.x docServlet |
|
Kompilieren der Klassen des Admin-Tools |
build_it.x compileAdmin |
|
Kompilieren und Erzeugen des Admin-Tools |
build_it.x distAdmin |
|
Dokumentieren des Admin-Tools |
build_it.x docAdmin |
Bei der Distribution des Applets ist im ant-Script folgende Nachbearbeitung vorgesehen: zunächst werden nicht benötigte Klassen aus der superx.jar entfernt, um das Applet möglichst klein zu halten. Das OpenSource-Tool obfuscator wird aufgerufen und die resultierende superx.jar wird an die richtige Stelle kopiert ($SUPERX_DIR/webserver/tomcat/webapps/superx/applet). Danach ist eine Signierung des Applets vorgesehen. Die Syntax ist in dem Kommentar des targets distApplet in der build.xml beschrieben:
Geben Sie auf der Kommandozeile ein:
|
Befehlsfolge zum Signieren des Applets |
keytool -genkey -alias superx_applet -keyalg RSA keytool -selfcert -alias superx_applet -validity 365 |
Als Passwort wählen Sie das, das in der build.xml vorgesehen ist. Der Wert hinter Validitiy beschreibt den Gültigkeitszeitraum des Zertifikats (in Tagen).
Wenn Sie das Zertifikat erneuern wollen, müssen Sie es zunächst löschen mit
keytool -delete -alias superx_applet
Das gleiche Vorgehen gilt für das Admin-Tool.
Als Entwicklungsumgebung empfehlen wir Eclipse von IBM oder den plattformübergreifend verfügbaren OpenSource-Editor jedit ( www.jedit.org ). Er unterstützt via Pugins die Java-Entwicklung. Für SuperX benötigen Sie die folgenden Plugins:
|
Plugins für Jedit |
|
Console-Plugin |
|
|
|
JBrowse |
|
|
|
JCompiler |
|
|
|
AntFarm |
|
|
|
XML |
|
|
|
XSLT |
Im Clientpaket sind diese Plugins bereits enthalten.
Sie starten das Plugin
AntFarm
, und geben als Build-File die Datei
$SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF/src/build.xml
an. Die Targets werden dann übersichtlich angezeigt und können sofort ausgeführt werden.
Die SuperX-Hilfe besteht aus einem Archiv im Javahelp-Format. Sie ist nur für das Applet nutzbar. Die Hilfetexte sind in den Modulen erzeugt und können problemlos integriert werden. Falls Sie eigene Hilfetexte einbinden wollen, müssen Sie wie folgt vorgehen:
1. Erzeugen Sie html-Seiten mit der Hilfe (html 3.2)
2.
Binden Sie die Dateien in die Mapping-Datei ein
(
$SUPERX_DIR/webserver/tomcat/webapps/superx/applet/javahelp/map.jhm
)
3. Falls die Hilfeseiten kontextabhängig abrufbar sein sollen, müssen die Titel der Mapping-Einträge folgenden Konventionen folgen:
• Allgemeine Beschreibungen der Abfragen lauten A<<TID>>.htm
• Beschreibungen der Masken lauten M<<TID>>.htm
• Beschreibungen der Ergebnistabellen lauten T<<TID>>.htm
Am Anfang ist es hilfreich, die vorhandenen Hilfetexte als Vorlage zu benutzen.
Die Javahilfe kann auch komfortabler mit dem Memtext-Autorensystem aus einer Word-Datei erzeugt werden. Details dazu siehe http://studio.memtext.de .
Siehe http://www.superx-projekt.de/doku/kern_modul/f_Versionshistorie.htm
In der tomcat/webapps/superx/WEB-INF/web.xml muss eingetragen werden, dass SuperX Standalone läuft.
<web-app xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd" version="2.4">
<display-name>SuperX</display-name>
<absolute-ordering />
<description>SuperX</description>
<context-param>
<param-name>superxStandalone</param-name>
<param-value>false</param-value>
</context-param>
Falls Sie LDAP benutzen, stellen Sie gemäß Kapitel „LDAP Anbindung“ auf die neue Technik um.
Tomcat server.xml anpassen
Öffnen Sie die Datei tomcat/conf/server.xml und kommentieren Sie den normalen Realm mit userdatabase aus.
<!--
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
debug="0" resourceName="UserDatabase"/>
-->
Fügen Sie statt dessen einen JNDI-Realm für LDAP nach folgendem Beispiel hinzu:
<Realm className="org.apache.catalina.realm.JNDIRealm"
debug="0"
connectionName="cn=Manager,dc=hostname,dc=de"
connectionPassword="secret"
connectionURL="ldap://hostname.de:389"
userSearch="(uid={0})"
userPassword="userPassword"
userPattern="uid={0},ou=people,dc=hostname,dc=de"
roleBase="dc=roles,dc=hostname,dc=de"
roleName="cn"
roleSearch="(uniqueMember={0})"
roleSubtree="false"
/>
entweder userPattern oder userBase etc (s.u. Freiburg)
Bei diesem Beispiel wird davon ausgegangen, dass die User unter dem Knoten ou=people,dc=hostname,dc=de hängen, für die Userkennung uid benutzt wird (könnte stattdessen auch cn oder etwas anderes sein) und das Passwort im Attribut userPassword hinterlegt ist. Vergleiche folgende ldif-Einträge:
#der Hauptknoten
dn: dc =hostname, dc =de
dc : dc =hostname, dc =de
objectClass : dcObject
objectClass : organization
o : Hochschule XY
#Unterknoten people
dn: ou =people, dc =hostname, dc =de
ou : people
objectClass : top
objectClass : organizationalUnit
#User admin unter people,hostname,de
dn: uid =admin, ou =people, dc =hostname, dc =de
mail : admin@hochschuleXY.de
userPassword :: YWRtaW5wYXNzd29yZA= =
uid : admin
givenName : Admin
objectClass : person
objectClass : inetOrgPerson
sn : Admin
cn : Admin
#User testuser unter people,hostname,de
dn: uid =testuser, ou =people, dc =hostname, dc =de
userPassword :: YW5mYW5nMTI=
uid : testuser
givenName : test
objectClass : person
objectClass : inetOrgPerson
sn : test
cn : test
Passen Sie die Einträge userSearch , userPassword und userPattern ggfs. gemäß Ihren LDAP-Konventionen an (wenn das Passwort nicht in einem Attribut abgelegt ist, kann die Angabe u.U. auch entfallen).
Alle User, die Sie durch diese Parameter gefunden werden, können sich bei Tomcat als User authentifizieren – was aber nicht heißt, dass auch alle User Zugriff auf SuperX bekommen.
Als nächstes muss geklärt werden, welche Gruppen/Rollen Zugriff auf SuperX bekommen sollen.
Die Gruppenzugehörigkeit der User wird aus LDAP über die Parameter roleBase,roleName und RoleSearch herausgesucht.
In unserem Beispiel ist in LDAP ein Knoten dc=roles,dc=hostname,dc=de angelegt unter dem eine Gruppe sxusers mit den eindeutigen Kennzeichern der Gruppenmitglieder existiert.
Vergleiche folgende Ldif-Einträge
#Knoten roles unter dem Haupt
dn: dc =roles, dc =hostname, dc =de
objectClass : person
sn : Roles Entry
cn : roles
#Gruppe sxusers unter role
dn: cn =sxusers, dc =roles, dc =hostname, dc =de
objectClass : groupOfUniqueNames
uniqueMember : uid =admin, ou =people, dc =hostname, dc =de
uniqueMember : uid =testuser, ou =people, dc =hostname, dc =de
cn : sxusers
Bei der Realmdefinition muss angegeben werden, wie nach Gruppenzugehörigkeit gesucht werden soll, im Beispiel ist die Basis der Knoten roles , der Name der Rolle steht in cn und die Mitglieder werden über uniqueMember identifiziert. So erklären sich die folgenden Einträge in der Realmdefinition:
roleBase="dc=roles,dc=hostname,dc=de"
roleName="cn"
roleSearch="(uniqueMember={0})"
Da der Login nicht vom Tomcat übernommen werden soll, wird das bei der Connection mitgeteilt. Je nach Tomcat Version kann bzw. muss der Parameter tomcatAuthentication und/oder tomcatAuthorization angegeben werden. Hier ein Beispiel:
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8" tomcatAuthentication="false" tomcatAuthorization="false" />
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" URIEncoding="UTF-8" tomcatAuthentication="false" tomcatAuthorization="false" />
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" tomcatAuthentication="false" tomcatAuthorization="false" />
Verwenden Sie am besten die web.xml_superxonly. Dort sind die Einstellungen bereits so gewählt, dass LDAP funktioniert.
Es ist nicht unbedingt nötig, eine Gruppe sxusers zu haben. Welche Gruppen Zugriff auf SuperX haben sollen, wird in der Datei tomcat/webapps/superx/WEB-INF/web.xml geregelt.
Öffnen Sie die Datei und fügen Sie den folgenden Abschnitt nach am Ende ein:
<security-constraint>
<display-name> SuperX Security Constraint </display-name>
<web-resource-collection>
<web-resource-name> Protected Area </web-resource-name>
<url-pattern> /* </url-pattern>
<!-- root ist hier schon IP:8080/superx, also ohne /superx angeben-->
<!-- z.B. /FH_TEST1/* für Unterverzeichnis eines Mandanten-->
<http-method> DELETE </http-method>
<http-method> GET </http-method>
<http-method> POST </http-method>
<http-method> PUT </http-method>
</web-resource-collection>
<auth-constraint>
<role-name> sxusers </role-name>
</auth-constraint>
</security-constraint>
<login-config>
<realm-name> SuperX Authentication Area </realm-name>
<auth-method> FORM </auth-method>
<form-login-config>
<form-login-page> /anmeldung_ldap.jsp </form-login-page>
<form-error-page> /anmeldung_jail.jsp </form-error-page>
<!-- Datei also unter webapps/superx/anmeldung_ldap.jsp-->
</form-login-config>
</login-config>
<security-role>
<role-name> sxusers </role-name>
</security-role>
Achtung: Wenn Sie auch Joolap einsetzen, darf das joolap-Unterverzeichnis nicht geschützt sein, schützen Sie in dem Fall am besten per url-pattern nur die Unterverzeichnisse applet,servlet,edit und xml.
Für jede Grupppe, die Zugriff auf SuperX erhalten soll machen Sie einen Eintrag
<role-name>Gruppenname</role-name> unter <auth-constraint> und <security-role> .
Wenn Sie keine spezielle LDAP-Usergruppe haben, können Sie als role-name auch * angeben.
Benennen Sie die mitgelieferten Dateien webapps/superx/anmeldung_ldap.jsp.sam und anmeldung_jail.jsp.sam um nach anmeldung_ldap.jsp und anmeldung_jail.jsp und gestalten Sie sie ggfs. nach Ihren Vorstellungen.
Hilfreiche Links
http://tomcat.apache.org/tomcat-4.0-doc/realm-howto.html
http://cymulacrum.net/writings/adv_tomcat/c302.html
http://cymulacrum.net/writings/adv_tomcat/c487.html
Startdateien anpassen
a) superx/
Löschen Sie die index.htm und index.jsp und benennen Sie die Datei index.jsp.sam um in index.jsp
b) superx/applet
Löschen Sie alle alten Startdateien wie index.htm, superx.html, index.jsp und benennen Sie die index.jsp.sam um nach index.jsp. Falls Sie ein mandantenfähiges SuperX laufen lassen, ändern Sie in der Datei den Parameter MandantenID von default auf die ID des jeweiligen Mandanten.
c) superx/xml
Löschen Sie auch hier alle vorhandenen Startdateien wie index.htm,index2.htm, index.jsp,anmeldung.htm,anmeldung.js,anmeldung.jsp.
Benennen Sie dann index.htm.sam um in index.htm, anmeldung.jsp.sam in anmeldung.jsp (darin auch wieder ggfs. den Parameter MandantenID anpassen)
Die index.html muss im Frame auf anmeldung.jsp verweisen.
1 Abmeldeurl kontrollieren
Standardmäßig wird bei der Abmeldung vom XML-Frontend auf die Url /superx/ redirected, falls eine andere URL gewünscht ist, kann diese als Parameter alt_redirect_url dem SuperXmlAbmeldung-Servlet in der web.xml übergeben werden.
Beispiel Konfiguration Freiburg
Zertifikat für den Zugriff auf den LDAP-Server:
Tomcat sucht das Zertifikat unter:
$JAVA_HOME/jre/lib/security/jssecacerts
1. keytool -import -alias tomcat -file bv1.pem.public -keystore jssecacerts
1. jssecacerts nach $JAVA_HOME/jre/lib/security kopieren
2. Tomcat neu starten
3.
server.xml:
<Realm className="org.apache.catalina.realm.JNDIRealm" debug="0"
connectionURL="ldaps://xxx.ruf.uni-freiburg.de:636"
userBase="ou=people,dc=uni-freiburg,dc=de"
userSubtree="true"
userSearch="(uid={0})"
userRoleName="uid"/>
web.xml:
<security-constraint>
<display-name>SuperX Security Constraint</display-name>
<web-resource-collection>
<web-resource-name>Protected Area</web-resource-name>
<url-pattern>/konto/*</url-pattern>
<http-method>DELETE</http-method>
<http-method>GET</http-method>
<http-method>POST</http-method>
<http-method>PUT</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>*</role-name>
</auth-constraint>
</security-constraint>
<login-config>
<realm-name>SuperX Authentication Area</realm-name>
<auth-method>FORM</auth-method>
<form-login-config>
<form-login-page>/anmeldung_ldap.jsp</form-login-page>
<form-error-page>/anmeldung_jail.jsp</form-error-page>
</form-login-config>
</login-config>
<security-role>
<role-name>*</role-name>
</security-role>
Security Role wichtig
<Realm className="org.apache.catalina.realm.JNDIRealm"
debug="99" digest="SHA"
connectionURL="ldaps://xxxx.uni-jena.de:636"
connectionName="cn=superx,ou=service,o=uni"
connectionPassword="superXzzzz"
userPattern="cn={0},ou=user,o=uni"
/>
<security-constraint>
<display-name>SuperX Security Constraint</display-name>
<web-resource-collection>
<web-resource-name>Protected Area</web-resource-name>
<url-pattern>/xml/*</url-pattern>
<url-pattern>/servlet/*</url-pattern>
<url-pattern>/edit/*</url-pattern>
<http-method>DELETE</http-method>
<http-method>GET</http-method>
<http-method>POST</http-method>
<http-method>PUT</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>*</role-name>
</auth-constraint>
<user-data-constraint>
<transport-guarantee>CONFIDENTIAL</transport-guarantee>
</user-data-constraint>
</security-constraint>
<login-config>
<realm-name>SuperX Authentication Area</realm-name>
<auth-method>FORM</auth-method>
<form-login-config>
<form-login-page>/anmeldung_ldap.jsp</form-login-page>
<form-error-page>/anmeldung_jail.jsp</form-error-page>
</form-login-config>
</login-config>
<security-role>
<role-name>*</role-name>
</security-role>
Anmeldung.jsp
<%
if(request.getRemoteUser() != null)
{
%>
<jsp:forward page="../servlet/SuperXmlAnmeldung" >
<jsp:param name="kennung" value="<%= request.getRemoteUser() %>" />
<jsp:param name="MandantenID" value="default" />
</jsp:forward>
<%
}
else
{
%>
<html>
<body>
Kein authentifizierter LDAP-User gefunden
</body>
<html>
<%}%>
server.xml
<Realm className="org.apache.catalina.realm.JNDIRealm" debug="99"
connectionURL="ldaps://141.7.17.7:636"
userBase="ou=people,dc=hs-heilbronn,dc=de"
userSubtree="true"
userSearch=" (&(uid={0})(employeetype=personal)(accountstatus=aktiv)) "
userRoleName="uid"/>
als letztes Element in web.xml
<security-constraint>
<display-name>SuperX Security Constraint</display-name>
<web-resource-collection>
<web-resource-name>Protected Area</web-resource-name>
<url-pattern>/FH_TEST1/*</url-pattern>
<http-method>DELETE</http-method>
<http-method>GET</http-method>
<http-method>POST</http-method>
<http-method>PUT</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>*</role-name>
</auth-constraint>
</security-constraint>
<login-config>
<realm-name>SuperX Authentication Area</realm-name>
<auth-method>FORM</auth-method>
<form-login-config>
<form-login-page>/anmeldung_ldap.jsp</form-login-page>
<form-error-page>/anmeldung_jail.jsp</form-error-page>
</form-login-config>
</login-config>
<security-role>
<role-name>*</role-name>
</security-role>
Kombination von LDAP-Login und dem normalen Login
Es gibt auch die Möglichkeit LDAP und den normalen Login parallel zu betreiben. Dazu sind einige schritte nötig:
1. unter webserver/tomcat/webapps/superx den Ordner ldap anlegen.
2. Dort werden folgende Dateien aus dem xml Verzeichnis hinein verschoben:
anmeldung_fail.jsp
anmeldung_ldap.jsp
anmeldung.jsp
index.jsp
3. Die index.htm aus dem xml Verzeichnis nach index_superx.htm kopieren.
4. In der index.htm aus dem xml Verzeichnis wird in den HEAD die Weiterleitung eingerichtet:
<META HTTP-EQUIV="refresh" CONTENT="0;URL=../ldap/index.jsp">
Damit wird bei normalen Aufruf der LDAP Login verwendet. Bei Eingabe von explizit index_superx.htm gelangt man zu dem normalen Login.
6. In der web.xml folgende Einträge anpassen:
<url-pattern>/ldap/*</url-pattern>
<form-login-page>/ldap/anmeldung_ldap.jsp</form-login-page>
<form-error-page>/ldap/anmeldung_fail.jsp</form-error-page>
Troubleshooting beim LDAP Zugang
Falls der LDAP Zugang nicht wie gewünscht funktioniert, gibt es mehrere Ursachen:
• Die Benutzerkennung existiert noch nicht bzw. hat zu wenig Rechte in der Anwendung. Prüfen Sie in der Userverwaltung , ob die Login-Kennung existiert und welche Rechte sie hat.
• Der Benutzerkennung fehlt im LDAP Server die zugehörige Rolle. Prüfen Sie den Suchstring in der server.xml, ggf. mit einem Werkzeug eines Drittanbieters. Man kann z.B. mit dem Werkzeug ldapsearch ein LDAP Verzeichnis durchsuchen:
ldapsearch -H <<URL>> -b "ou=..." "uid=testuser"
• Der Zugang vom Tomcat zum LDAP-Server funktioniert noch nicht. In diesem Falle sollten Sie das Logging des Tomcat verfeinern:
Datei tomcat/conf/logging.properties:
org.apache.catalina.realm.level = ALL
org.apache.catalina.realm.useParentHandlers = true
org.apache.catalina.authenticator.level = ALL
org.apache.catalina.authenticator.useParentHandlers = true
Wenn Sie Tomcat neu starten, bekommen Sie in der Tomcat-Konsole (bzw. unter Unix in der Datei catalina.out) eine bessere Logausgabe.
W enn sich im LDAP nur ein Benutzer anmelden kann
Wenn Sie in der server.xml eine userBase angeben und einen connectionName angeben, kann es vorkommen dass sich nur dieser dort angegebene User anmelden kann. Beispiel:
connectionURL="ldaps://ldaps-rzkj-3.rrz.uni-koeln.de:636"
userBase="ou=People,dc=uni-koeln,dc=de"
userSearch="(uid={0})"
userSubtree="true"
und weiter unten:
connectionName="uid=mbunny,ou=People,dc=uni-koeln,dc=de"
connectionPassword="xxx"
Wir haben die connectionURL auf userPattern umgestellt, und dann klappte es:
connectionURL="ldaps://ldaps-rzkj-3.rrz.uni-koeln.de:636"
userPattern="uid={0},ou=People,dc=uni-koeln,dc=de"
Damit klappt es dann immer.
Es war möglich, die Authentifizierung von Usern über ein Shibboleth - Login laufen zu lassen.
Die User müssen aber auf jeden Fall in SuperX auch existieren und entsprechende Gruppenzugehörigkeiten und Rechteeinstellungen haben (Tabellen userinfo, groupinfo, user_group_bez, user_masken_bez,group_masken_bez,user_sachgeb_bez,group_sachgeb_bez, user_sichten etc).
Nach der Anmeldung in Shibboleth wird die Kennung an SuperX weitergeleitet und der User ist in SuperX angemeldet. Dazu muss unterhalb von der Webapplikation superx/ die index_shibboleth.jsp nach index.jsp umbenannt werden.
1 in älteren Versionen des SuperX-Kernmoduls laden die Rohdaten unter db/rohdaten . Dies hat sich als unpraktisch erwiesen
2 Bezüglich der Postgres Installation ist Herrn Wehling von der Uni Köln aufgefallen, daß die
Postgres 7.2 Versionen unter dem neuen Redhat 9 nicht kompilierbar sind.
Wenn man in
/install/postgres-7.2.4/src/backend/commands/copy.c
oben folgende Zeile einbaut, geht es:
#include <errno.h>
3 Unter Suse Linux 8.x, 9.x und RedHat 8.x und Fedora ist der Postgres-Datenbankserver für internationale Umgebungen installiert und daher problemlos lauffähig. Siehe allerdings den Hinweis zur Sysconfig unter SuSE .
4 In den 7.x-Postgres-Versionen ist dies offensichtlich ein Bug: Wenn ein User Datenbanken und Benutzer anlegen darf, dann wird er von Postgres als "Superuser" klassifiziert und darf deshalb auch Scriptsprachen installieren. In Postgres 8.x wurde dies korrigiert.
5 Unter Win 98 / Me befindet sich diese Datei im Verzeichnis c:\windows
6 http://support.microsoft.com/default.aspx?scid=kb;DE;304548
7
Ändern Sie mit regedit folgenden Schlüssel:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Jet\VERSION\Engines\ODBC
Setzen Sie dort den (dezimalen) Wert ConnectionTimeout (z.B. 600) auf 0
Siehe
http://www.ms-office-forum.net/forum/archivethread-111477.html
oder
http://www.ms-office-forum.net/forum/showthread.php?s=&postid=438543#post438543
8 Eine hervorragende Einführung zum Einsatz des Apache mit Tomcat findet sich in der Zeitschrift iX, 2/2001, S.48ff.
9 Vielen Dank für diese Anleitung an Herrn Behnke, Uni Bonn. Siehe auch http://www.junlu.com/msg/48529.html
10 Im letzten Release waren versehentlich noch veraltete eine veraltete propadmin.x und propadmin.bat im Verzeichnis $SUPERX_DIR/webserver/tomcat/webapps/superx/WEB-INF vorhanden. Falls der Fehler NoClassDefFound auftaucht, löschen Sie diese zwei Dateien.
12
Auch in der offiziellen Doku von
mod_ssl
wird dies empfohlen, mit dem Zusatz,dass nur root und der apache-daemon diese Datei lesen darf.
http://www.modssl.org/docs/2.0/#FAQ-nopass
13
Auch in der offiziellen Doku von
mod_ssl
wird dies empfohlen, mit dem Zusatz,dass nur root und der apache-daemon diese Datei lesen darf.
http://www.modssl.org/docs/2.0/#FAQ-nopass
14 Aus historischen Gründen liegen die Nummern aus Karlsruhe im Bereich 0-9990, aus Duisburg im Bereich 10000-19990.
15 Warum ausgerechnet Word? Das Access-Frontend ist in Visual-Basic-for-Applications programmiert, und nach unserer Erfahrung ist dies der am meisten verfügbare Editor mit VBA-Unterstützung, wenn auch Access (als Teil von MS Office) installiert ist. Der Editor WordPad z.B. bietet keine VBA-Schnittstelle. Uns war außerdem eine ausgefeilte Such- und Undo-Funktion wichtig. Theoretisch könnte man in der mitgelieferten Dokumentvorlage editblob.dot im gleichen Verzeichnis auch Autotexte und Makros hinterlegen. Daher: Auch wenn es ungewöhnlich ist, Word als IDE zu benutzen: nach unserer Erfahrung ist es recht praktisch. Fehlt nur noch die farbige Syntaxunterstützung...
16 Details zu rsync siehe Dr. Boris Pasternak, Dr. Uwe Meyer-Gruhl (2003). Der Gleich-Macher. Dateien mit Rsync synchronisieren. c't 10/2003,S. 116ff.
17 Achtung: diese Funktion ist bei mandantenfähigen Installationen nicht ohne weiteres nutzbar, hier sind Anpassungen notwendig. Wenden Sie sich bei Bedarf an den SuperX-Support.